 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRoboCup@Home 2024 OPL Winner NimbRo: Anthropomorphic Service Robots using Foundation Models for Perception and Planning
Dec 19, 2024
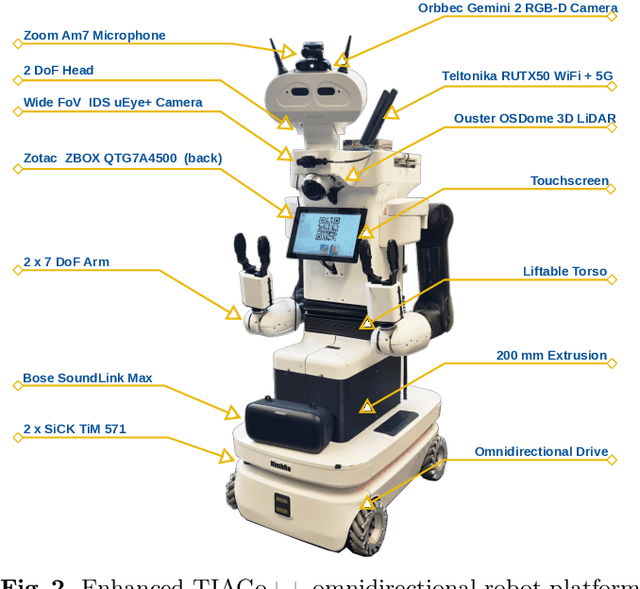


We present the approaches and contributions of the winning team NimbRo@Home at the RoboCup@Home 2024 competition in the Open Platform League held in Eindhoven, NL. Further, we describe our hardware setup and give an overview of the results for the task stages and the final demonstration. For this year's competition, we put a special emphasis on open-vocabulary object segmentation and grasping approaches that overcome the labeling overhead of supervised vision approaches, commonly used in RoboCup@Home. We successfully demonstrated that we can segment and grasp non-labeled objects by text descriptions. Further, we extensively employed LLMs for natural language understanding and task planning. Throughout the competition, our approaches showed robustness and generalization capabilities. A video of our performance can be found online.
Marker-free Human Gait Analysis using a Smart Edge Sensor System
Nov 14, 2024The human gait is a complex interplay between the neuronal and the muscular systems, reflecting an individual's neurological and physiological condition. This makes gait analysis a valuable tool for biomechanics and medical experts. Traditional observational gait analysis is cost-effective but lacks reliability and accuracy, while instrumented gait analysis, particularly using marker-based optical systems, provides accurate data but is expensive and time-consuming. In this paper, we introduce a novel markerless approach for gait analysis using a multi-camera setup with smart edge sensors to estimate 3D body poses without fiducial markers. We propose a Siamese embedding network with triplet loss calculation to identify individuals by their gait pattern. This network effectively maps gait sequences to an embedding space that enables clustering sequences from the same individual or activity closely together while separating those of different ones. Our results demonstrate the potential of the proposed system for efficient automated gait analysis in diverse real-world environments, facilitating a wide range of applications.
Anticipating Human Behavior for Safe Navigation and Efficient Collaborative Manipulation with Mobile Service Robots
Oct 07, 2024
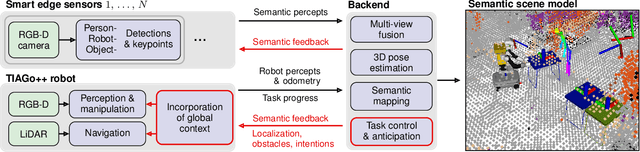
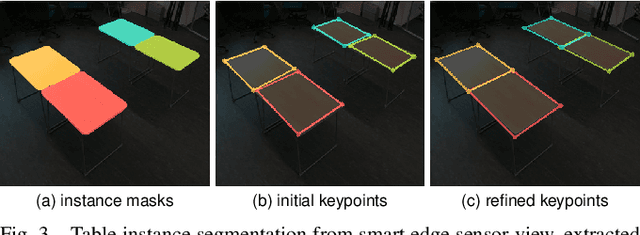
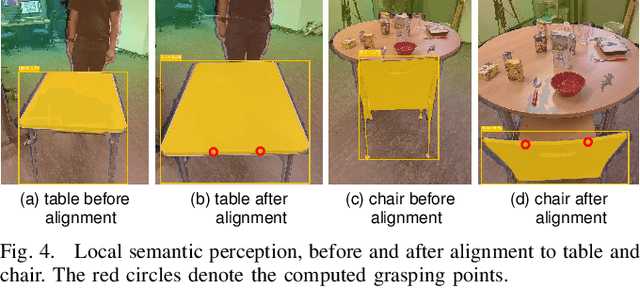
The anticipation of human behavior is a crucial capability for robots to interact with humans safely and efficiently. We employ a smart edge sensor network to provide global observations along with future predictions and goal information to integrate anticipatory behavior for the control of a mobile manipulation robot. We present approaches to anticipate human behavior in the context of safe navigation and a collaborative mobile manipulation task. First, we anticipate human motion by employing projections of human trajectories from smart edge sensor network observations into the planning map of a mobile robot. Second, we anticipate human intentions in a collaborative furniture-carrying task to achieve a given goal. Our experiments indicate that anticipating human behavior allows for safer navigation and more efficient collaboration. Finally, we showcase an integrated system that anticipates human behavior and collaborates with a human to achieve a target room layout, including the placement of tables and chairs.
External Camera-based Mobile Robot Pose Estimation for Collaborative Perception with Smart Edge Sensors
Mar 07, 2023



We present an approach for estimating a mobile robot's pose w.r.t. the allocentric coordinates of a network of static cameras using multi-view RGB images. The images are processed online, locally on smart edge sensors by deep neural networks to detect the robot and estimate 2D keypoints defined at distinctive positions of the 3D robot model. Robot keypoint detections are synchronized and fused on a central backend, where the robot's pose is estimated via multi-view minimization of reprojection errors. Through the pose estimation from external cameras, the robot's localization can be initialized in an allocentric map from a completely unknown state (kidnapped robot problem) and robustly tracked over time. We conduct a series of experiments evaluating the accuracy and robustness of the camera-based pose estimation compared to the robot's internal navigation stack, showing that our camera-based method achieves pose errors below 3 cm and 1{\deg} and does not drift over time, as the robot is localized allocentrically. With the robot's pose precisely estimated, its observations can be fused into the allocentric scene model. We show a real-world application, where observations from mobile robot and static smart edge sensors are fused to collaboratively build a 3D semantic map of a $\sim$240 m$^2$ indoor environment.
Object-level 3D Semantic Mapping using a Network of Smart Edge Sensors
Nov 21, 2022



Autonomous robots that interact with their environment require a detailed semantic scene model. For this, volumetric semantic maps are frequently used. The scene understanding can further be improved by including object-level information in the map. In this work, we extend a multi-view 3D semantic mapping system consisting of a network of distributed smart edge sensors with object-level information, to enable downstream tasks that need object-level input. Objects are represented in the map via their 3D mesh model or as an object-centric volumetric sub-map that can model arbitrary object geometry when no detailed 3D model is available. We propose a keypoint-based approach to estimate object poses via PnP and refinement via ICP alignment of the 3D object model with the observed point cloud segments. Object instances are tracked to integrate observations over time and to be robust against temporary occlusions. Our method is evaluated on the public Behave dataset where it shows pose estimation accuracy within a few centimeters and in real-world experiments with the sensor network in a challenging lab environment where multiple chairs and a table are tracked through the scene online, in real time even under high occlusions.
Real-Time Multi-Modal Semantic Fusion on Unmanned Aerial Vehicles with Label Propagation for Cross-Domain Adaptation
Oct 18, 2022


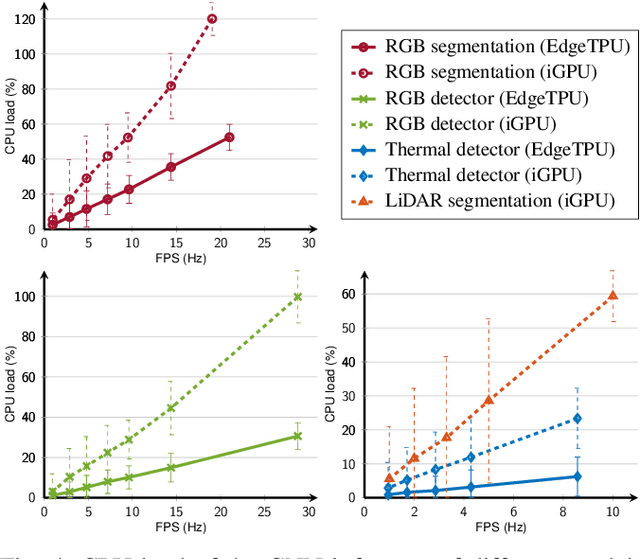
Unmanned aerial vehicles (UAVs) equipped with multiple complementary sensors have tremendous potential for fast autonomous or remote-controlled semantic scene analysis, e.g., for disaster examination. Here, we propose a UAV system for real-time semantic inference and fusion of multiple sensor modalities. Semantic segmentation of LiDAR scans and RGB images, as well as object detection on RGB and thermal images, run online onboard the UAV computer using lightweight CNN architectures and embedded inference accelerators. We follow a late fusion approach where semantic information from multiple sensor modalities augments 3D point clouds and image segmentation masks while also generating an allocentric semantic map. Label propagation on the semantic map allows for sensor-specific adaptation with cross-modality and cross-domain supervision. Our system provides augmented semantic images and point clouds with $\approx$ 9 Hz. We evaluate the integrated system in real-world experiments in an urban environment and at a disaster test site.
Online Marker-free Extrinsic Camera Calibration using Person Keypoint Detections
Sep 15, 2022

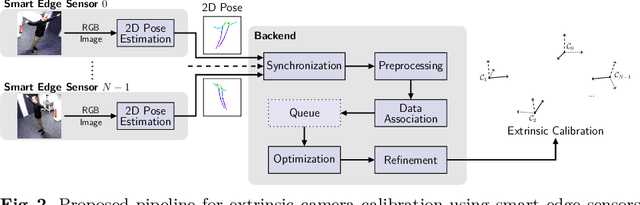

Calibration of multi-camera systems, i.e. determining the relative poses between the cameras, is a prerequisite for many tasks in computer vision and robotics. Camera calibration is typically achieved using offline methods that use checkerboard calibration targets. These methods, however, often are cumbersome and lengthy, considering that a new calibration is required each time any camera pose changes. In this work, we propose a novel, marker-free online method for the extrinsic calibration of multiple smart edge sensors, relying solely on 2D human keypoint detections that are computed locally on the sensor boards from RGB camera images. Our method assumes the intrinsic camera parameters to be known and requires priming with a rough initial estimate of the camera poses. The person keypoint detections from multiple views are received at a central backend where they are synchronized, filtered, and assigned to person hypotheses. We use these person hypotheses to repeatedly solve optimization problems in the form of factor graphs. Given suitable observations of one or multiple persons traversing the scene, the estimated camera poses converge towards a coherent extrinsic calibration within a few minutes. We evaluate our approach in real-world settings and show that the calibration with our method achieves lower reprojection errors compared to a reference calibration generated by an offline method using a traditional calibration target.
3D Semantic Scene Perception using Distributed Smart Edge Sensors
May 03, 2022



We present a system for 3D semantic scene perception consisting of a network of distributed smart edge sensors. The sensor nodes are based on an embedded CNN inference accelerator and RGB-D and thermal cameras. Efficient vision CNN models for object detection, semantic segmentation, and human pose estimation run on-device in real time. 2D human keypoint estimations, augmented with the RGB-D depth estimate, as well as semantically annotated point clouds are streamed from the sensors to a central backend, where multiple viewpoints are fused into an allocentric 3D semantic scene model. As the image interpretation is computed locally, only semantic information is sent over the network. The raw images remain on the sensor boards, significantly reducing the required bandwidth, and mitigating privacy risks for the observed persons. We evaluate the proposed system in challenging real-world multi-person scenes in our lab. The proposed perception system provides a complete scene view containing semantically annotated 3D geometry and estimates 3D poses of multiple persons in real time.
Target Chase, Wall Building, and Fire Fighting: Autonomous UAVs of Team NimbRo at MBZIRC 2020
Jan 11, 2022


The Mohamed Bin Zayed International Robotics Challenge (MBZIRC) 2020 posed diverse challenges for unmanned aerial vehicles (UAVs). We present our four tailored UAVs, specifically developed for individual aerial-robot tasks of MBZIRC, including custom hardware- and software components. In Challenge 1, a target UAV is pursued using a high-efficiency, onboard object detection pipeline to capture a ball from the target UAV. A second UAV uses a similar detection method to find and pop balloons scattered throughout the arena. For Challenge 2, we demonstrate a larger UAV capable of autonomous aerial manipulation: Bricks are found and tracked from camera images. Subsequently, they are approached, picked, transported, and placed on a wall. Finally, in Challenge 3, our UAV autonomously finds fires using LiDAR and thermal cameras. It extinguishes the fires with an onboard fire extinguisher. While every robot features task-specific subsystems, all UAVs rely on a standard software stack developed for this particular and future competitions. We present our mostly open-source software solutions, including tools for system configuration, monitoring, robust wireless communication, high-level control, and agile trajectory generation. For solving the MBZIRC 2020 tasks, we advanced the state of the art in multiple research areas like machine vision and trajectory generation. We present our scientific contributions that constitute the foundation for our algorithms and systems and analyze the results from the MBZIRC competition 2020 in Abu Dhabi, where our systems reached second place in the Grand Challenge. Furthermore, we discuss lessons learned from our participation in this complex robotic challenge.
Real-Time Multi-Modal Semantic Fusion on Unmanned Aerial Vehicles
Aug 14, 2021



Unmanned aerial vehicles (UAVs) equipped with multiple complementary sensors have tremendous potential for fast autonomous or remote-controlled semantic scene analysis, e.g., for disaster examination. In this work, we propose a UAV system for real-time semantic inference and fusion of multiple sensor modalities. Semantic segmentation of LiDAR scans and RGB images, as well as object detection on RGB and thermal images, run online onboard the UAV computer using lightweight CNN architectures and embedded inference accelerators. We follow a late fusion approach where semantic information from multiple modalities augments 3D point clouds and image segmentation masks while also generating an allocentric semantic map. Our system provides augmented semantic images and point clouds with $\approx\,$9$\,$Hz. We evaluate the integrated system in real-world experiments in an urban environment.