 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVideoPCDNet: Video Parsing and Prediction with Phase Correlation Networks
Jun 24, 2025Understanding and predicting video content is essential for planning and reasoning in dynamic environments. Despite advancements, unsupervised learning of object representations and dynamics remains challenging. We present VideoPCDNet, an unsupervised framework for object-centric video decomposition and prediction. Our model uses frequency-domain phase correlation techniques to recursively parse videos into object components, which are represented as transformed versions of learned object prototypes, enabling accurate and interpretable tracking. By explicitly modeling object motion through a combination of frequency domain operations and lightweight learned modules, VideoPCDNet enables accurate unsupervised object tracking and prediction of future video frames. In our experiments, we demonstrate that VideoPCDNet outperforms multiple object-centric baseline models for unsupervised tracking and prediction on several synthetic datasets, while learning interpretable object and motion representations.
Leveraging Vision-Language Models for Open-Vocabulary Instance Segmentation and Tracking
Mar 18, 2025This paper introduces a novel approach that leverages the capabilities of vision-language models (VLMs) by integrating them with established approaches for open-vocabulary detection (OVD), instance segmentation, and tracking. We utilize VLM-generated structured descriptions to identify visible object instances, collect application-relevant attributes, and inform an open-vocabulary detector to extract corresponding bounding boxes that are passed to a video segmentation model providing precise segmentation masks and tracking capabilities. Once initialized, this model can then directly extract segmentation masks, allowing processing of image streams in real time with minimal computational overhead. Tracks can be updated online as needed by generating new structured descriptions and corresponding open-vocabulary detections. This combines the descriptive power of VLMs with the grounding capability of OVD and the pixel-level understanding and speed of video segmentation. Our evaluation across datasets and robotics platforms demonstrates the broad applicability of this approach, showcasing its ability to extract task-specific attributes from non-standard objects in dynamic environments.
RoboCup@Home 2024 OPL Winner NimbRo: Anthropomorphic Service Robots using Foundation Models for Perception and Planning
Dec 19, 2024
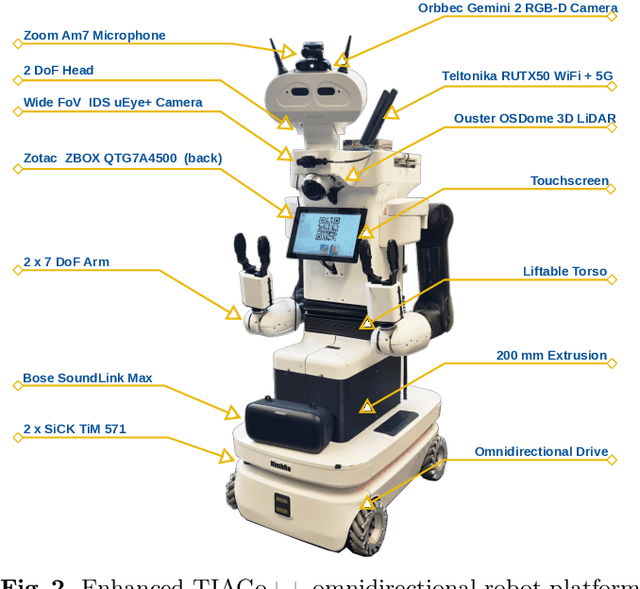


We present the approaches and contributions of the winning team NimbRo@Home at the RoboCup@Home 2024 competition in the Open Platform League held in Eindhoven, NL. Further, we describe our hardware setup and give an overview of the results for the task stages and the final demonstration. For this year's competition, we put a special emphasis on open-vocabulary object segmentation and grasping approaches that overcome the labeling overhead of supervised vision approaches, commonly used in RoboCup@Home. We successfully demonstrated that we can segment and grasp non-labeled objects by text descriptions. Further, we extensively employed LLMs for natural language understanding and task planning. Throughout the competition, our approaches showed robustness and generalization capabilities. A video of our performance can be found online.
Anticipating Human Behavior for Safe Navigation and Efficient Collaborative Manipulation with Mobile Service Robots
Oct 07, 2024
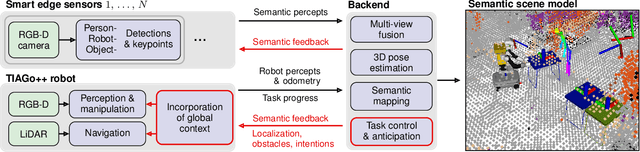
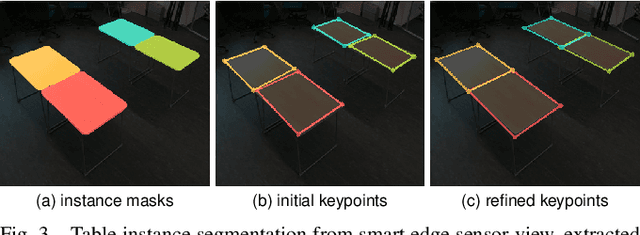
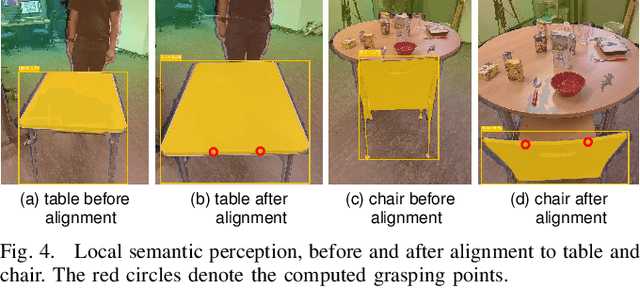
The anticipation of human behavior is a crucial capability for robots to interact with humans safely and efficiently. We employ a smart edge sensor network to provide global observations along with future predictions and goal information to integrate anticipatory behavior for the control of a mobile manipulation robot. We present approaches to anticipate human behavior in the context of safe navigation and a collaborative mobile manipulation task. First, we anticipate human motion by employing projections of human trajectories from smart edge sensor network observations into the planning map of a mobile robot. Second, we anticipate human intentions in a collaborative furniture-carrying task to achieve a given goal. Our experiments indicate that anticipating human behavior allows for safer navigation and more efficient collaboration. Finally, we showcase an integrated system that anticipates human behavior and collaborates with a human to achieve a target room layout, including the placement of tables and chairs.
Semantic Prediction: Which One Should Come First, Recognition or Prediction?
Oct 06, 2021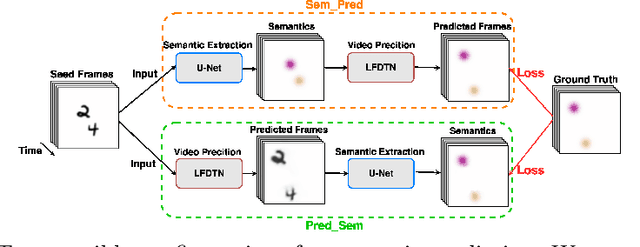
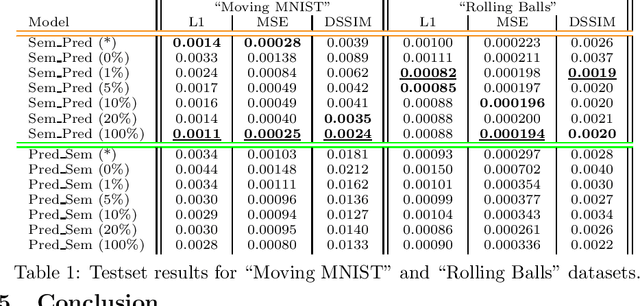
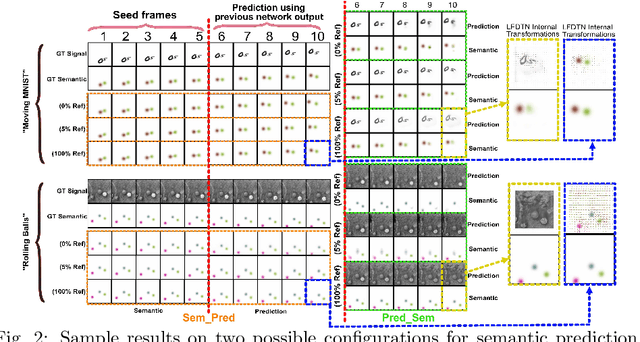
The ultimate goal of video prediction is not forecasting future pixel-values given some previous frames. Rather, the end goal of video prediction is to discover valuable internal representations from the vast amount of available unlabeled video data in a self-supervised fashion for downstream tasks. One of the primary downstream tasks is interpreting the scene's semantic composition and using it for decision-making. For example, by predicting human movements, an observer can anticipate human activities and collaborate in a shared workspace. There are two main ways to achieve the same outcome, given a pre-trained video prediction and pre-trained semantic extraction model; one can first apply predictions and then extract semantics or first extract semantics and then predict. We investigate these configurations using the Local Frequency Domain Transformer Network (LFDTN) as the video prediction model and U-Net as the semantic extraction model on synthetic and real datasets.
Local Frequency Domain Transformer Networks for Video Prediction
May 10, 2021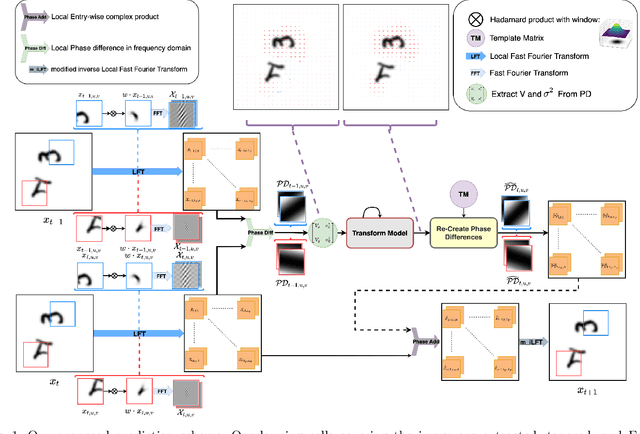

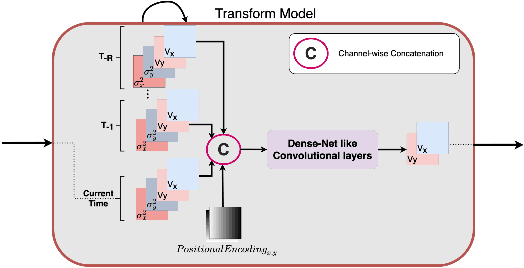
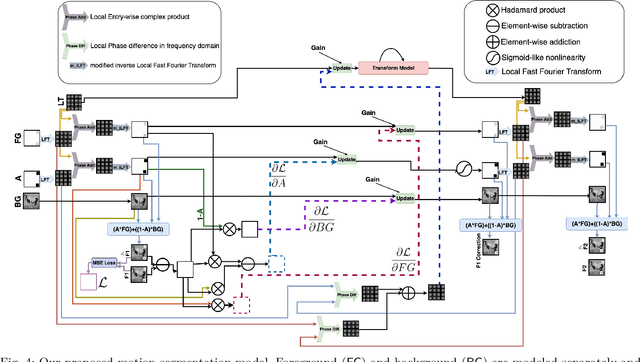
Video prediction is commonly referred to as forecasting future frames of a video sequence provided several past frames thereof. It remains a challenging domain as visual scenes evolve according to complex underlying dynamics, such as the camera's egocentric motion or the distinct motility per individual object viewed. These are mostly hidden from the observer and manifest as often highly non-linear transformations between consecutive video frames. Therefore, video prediction is of interest not only in anticipating visual changes in the real world but has, above all, emerged as an unsupervised learning rule targeting the formation and dynamics of the observed environment. Many of the deep learning-based state-of-the-art models for video prediction utilize some form of recurrent layers like Long Short-Term Memory (LSTMs) or Gated Recurrent Units (GRUs) at the core of their models. Although these models can predict the future frames, they rely entirely on these recurrent structures to simultaneously perform three distinct tasks: extracting transformations, projecting them into the future, and transforming the current frame. In order to completely interpret the formed internal representations, it is crucial to disentangle these tasks. This paper proposes a fully differentiable building block that can perform all of those tasks separately while maintaining interpretability. We derive the relevant theoretical foundations and showcase results on synthetic as well as real data. We demonstrate that our method is readily extended to perform motion segmentation and account for the scene's composition, and learns to produce reliable predictions in an entirely interpretable manner by only observing unlabeled video data.