 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSlot-MPC: Goal-Conditioned Model Predictive Control with Object-Centric Representations
May 14, 2026Predictive world models enable agents to model scene dynamics and reason about the consequences of their actions. Inspired by human perception, object-centric world models capture scene dynamics using object-level representations, which can be used for downstream applications such as action planning. However, most object-centric world models and reinforcement learning (RL) approaches learn reactive policies that are fixed at inference time, limiting generalization to novel situations. We propose Slot-MPC, an object-centric world modeling framework that enables planning through Model Predictive Control (MPC). Slot-MPC leverages vision encoders to learn slot-based representations, which encode individual objects in the scene, and uses these structured representations to learn an action-conditioned object-centric dynamics model. At inference time, the learned dynamics model enables action planning via MPC, allowing agents to adapt to previously unseen situations. Since the learned world model is differentiable, we can use gradient-based MPC to directly optimize actions, which is computationally more efficient than relying on gradient-free, sampling-based MPC methods. Experiments on simulated robotic manipulation tasks show that Slot-MPC improves both task performance and planning efficiency compared to non-object-centric world model baselines. In the considered offline setting with limited state-action coverage, we find that gradient-based MPC performs better than gradient-free, sampling-based MPC. Our results demonstrate that explicitly structured, object-centric representations provide a strong inductive bias for controllable and generalizable decision-making. Code and additional results are available at https://slot-mpc.github.io.
VideoPCDNet: Video Parsing and Prediction with Phase Correlation Networks
Jun 24, 2025Understanding and predicting video content is essential for planning and reasoning in dynamic environments. Despite advancements, unsupervised learning of object representations and dynamics remains challenging. We present VideoPCDNet, an unsupervised framework for object-centric video decomposition and prediction. Our model uses frequency-domain phase correlation techniques to recursively parse videos into object components, which are represented as transformed versions of learned object prototypes, enabling accurate and interpretable tracking. By explicitly modeling object motion through a combination of frequency domain operations and lightweight learned modules, VideoPCDNet enables accurate unsupervised object tracking and prediction of future video frames. In our experiments, we demonstrate that VideoPCDNet outperforms multiple object-centric baseline models for unsupervised tracking and prediction on several synthetic datasets, while learning interpretable object and motion representations.
Object-Centric Image to Video Generation with Language Guidance
Feb 17, 2025Accurate and flexible world models are crucial for autonomous systems to understand their environment and predict future events. Object-centric models, with structured latent spaces, have shown promise in modeling object dynamics and interactions, but often face challenges in scaling to complex datasets and incorporating external guidance, limiting their applicability in robotics. To address these limitations, we propose TextOCVP, an object-centric model for image-to-video generation guided by textual descriptions. TextOCVP parses an observed scene into object representations, called slots, and utilizes a text-conditioned transformer predictor to forecast future object states and video frames. Our approach jointly models object dynamics and interactions while incorporating textual guidance, thus leading to accurate and controllable predictions. Our method's structured latent space offers enhanced control over the prediction process, outperforming several image-to-video generative baselines. Additionally, we demonstrate that structured object-centric representations provide superior controllability and interpretability, facilitating the modeling of object dynamics and enabling more precise and understandable predictions. Videos and code are available at https://play-slot.github.io/TextOCVP/.
PlaySlot: Learning Inverse Latent Dynamics for Controllable Object-Centric Video Prediction and Planning
Feb 11, 2025Predicting future scene representations is a crucial task for enabling robots to understand and interact with the environment. However, most existing methods rely on video sequences and simulations with precise action annotations, limiting their ability to leverage the large amount of available unlabeled video data. To address this challenge, we propose PlaySlot, an object-centric video prediction model that infers object representations and latent actions from unlabeled video sequences. It then uses these representations to forecast future object states and video frames. PlaySlot allows to generate multiple possible futures conditioned on latent actions, which can be inferred from video dynamics, provided by a user, or generated by a learned action policy, thus enabling versatile and interpretable world modeling. Our results show that PlaySlot outperforms both stochastic and object-centric baselines for video prediction across different environments. Furthermore, we show that our inferred latent actions can be used to learn robot behaviors sample-efficiently from unlabeled video demonstrations. Videos and code are available at https://play-slot.github.io/PlaySlot/.
SOLD: Reinforcement Learning with Slot Object-Centric Latent Dynamics
Oct 11, 2024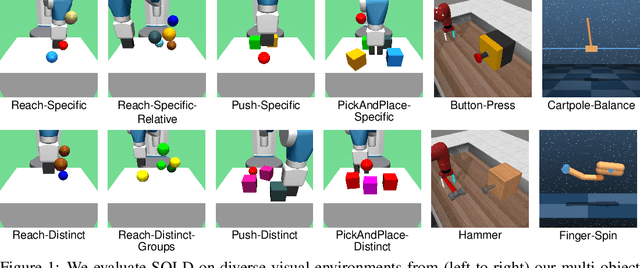

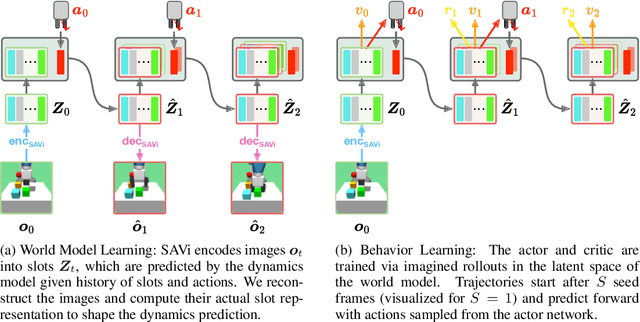

Learning a latent dynamics model provides a task-agnostic representation of an agent's understanding of its environment. Leveraging this knowledge for model-based reinforcement learning holds the potential to improve sample efficiency over model-free methods by learning inside imagined rollouts. Furthermore, because the latent space serves as input to behavior models, the informative representations learned by the world model facilitate efficient learning of desired skills. Most existing methods rely on holistic representations of the environment's state. In contrast, humans reason about objects and their interactions, forecasting how actions will affect specific parts of their surroundings. Inspired by this, we propose Slot-Attention for Object-centric Latent Dynamics (SOLD), a novel algorithm that learns object-centric dynamics models in an unsupervised manner from pixel inputs. We demonstrate that the structured latent space not only improves model interpretability but also provides a valuable input space for behavior models to reason over. Our results show that SOLD outperforms DreamerV3, a state-of-the-art model-based RL algorithm, across a range of benchmark robotic environments that evaluate for both relational reasoning and low-level manipulation capabilities. Videos are available at https://slot-latent-dynamics.github.io/.
MCDS-VSS: Moving Camera Dynamic Scene Video Semantic Segmentation by Filtering with Self-Supervised Geometry and Motion
May 30, 2024Autonomous systems, such as self-driving cars, rely on reliable semantic environment perception for decision making. Despite great advances in video semantic segmentation, existing approaches ignore important inductive biases and lack structured and interpretable internal representations. In this work, we propose MCDS-VSS, a structured filter model that learns in a self-supervised manner to estimate scene geometry and ego-motion of the camera, while also estimating the motion of external objects. Our model leverages these representations to improve the temporal consistency of semantic segmentation without sacrificing segmentation accuracy. MCDS-VSS follows a prediction-fusion approach in which scene geometry and camera motion are first used to compensate for ego-motion, then residual flow is used to compensate motion of dynamic objects, and finally the predicted scene features are fused with the current features to obtain a temporally consistent scene segmentation. Our model parses automotive scenes into multiple decoupled interpretable representations such as scene geometry, ego-motion, and object motion. Quantitative evaluation shows that MCDS-VSS achieves superior temporal consistency on video sequences while retaining competitive segmentation performance.
RoboCup 2023 Humanoid AdultSize Winner NimbRo: NimbRoNet3 Visual Perception and Responsive Gait with Waveform In-walk Kicks
Jan 11, 2024



The RoboCup Humanoid League holds annual soccer robot world championships towards the long-term objective of winning against the FIFA world champions by 2050. The participating teams continuously improve their systems. This paper presents the upgrades to our humanoid soccer system, leading our team NimbRo to win the Soccer Tournament in the Humanoid AdultSize League at RoboCup 2023 in Bordeaux, France. The mentioned upgrades consist of: an updated model architecture for visual perception, extended fused angles feedback mechanisms and an additional COM-ZMP controller for walking robustness, and parametric in-walk kicks through waveforms.
Object-Centric Video Prediction via Decoupling of Object Dynamics and Interactions
Feb 23, 2023We propose a novel framework for the task of object-centric video prediction, i.e., extracting the compositional structure of a video sequence, as well as modeling objects dynamics and interactions from visual observations in order to predict the future object states, from which we can then generate subsequent video frames. With the goal of learning meaningful spatio-temporal object representations and accurately forecasting object states, we propose two novel object-centric video predictor (OCVP) transformer modules, which decouple the processing of temporal dynamics and object interactions, thus presenting an improved prediction performance. In our experiments, we show how our object-centric prediction framework utilizing our OCVP predictors outperforms object-agnostic video prediction models on two different datasets, while maintaining consistent and accurate object representations.
RoboCup 2022 AdultSize Winner NimbRo: Upgraded Perception, Capture Steps Gait and Phase-based In-walk Kicks
Feb 07, 2023

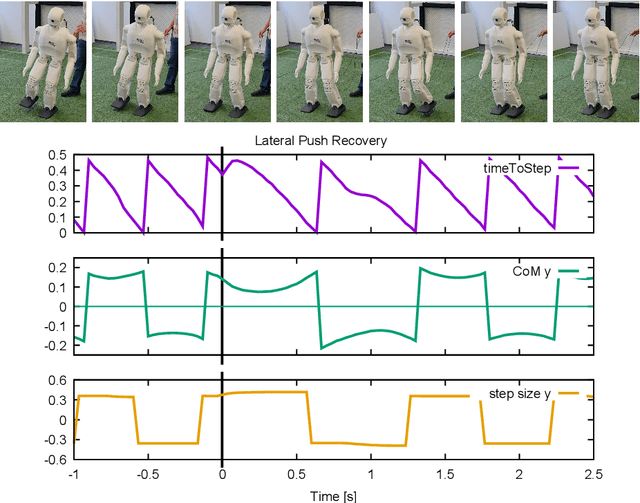

Beating the human world champions by 2050 is an ambitious goal of the Humanoid League that provides a strong incentive for RoboCup teams to further improve and develop their systems. In this paper, we present upgrades of our system which enabled our team NimbRo to win the Soccer Tournament, the Drop-in Games, and the Technical Challenges in the Humanoid AdultSize League of RoboCup 2022. Strong performance in these competitions resulted in the Best Humanoid award in the Humanoid League. The mentioned upgrades include: hardware upgrade of the vision module, balanced walking with Capture Steps, and the introduction of phase-based in-walk kicks.
Video Prediction at Multiple Scales with Hierarchical Recurrent Networks
Mar 17, 2022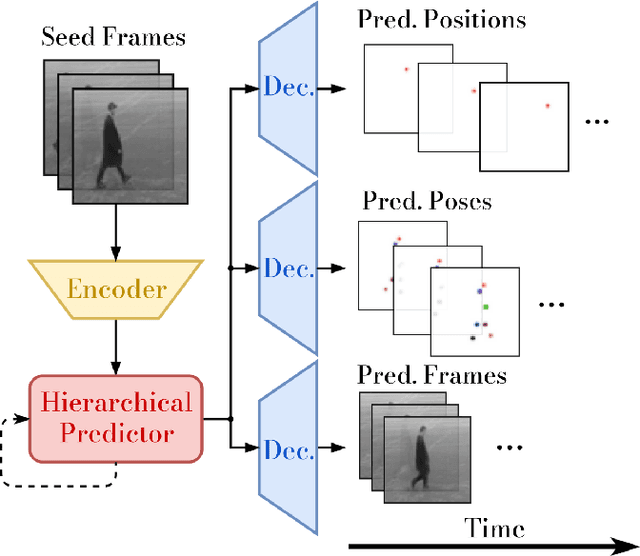
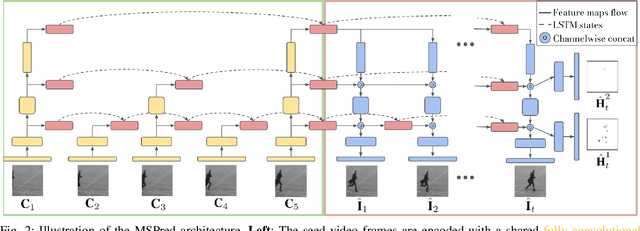
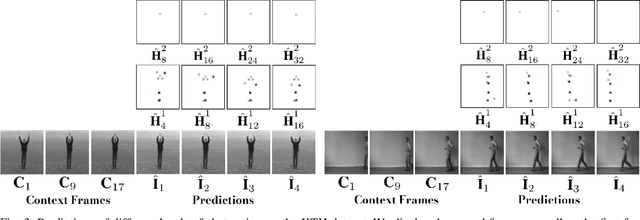

Autonomous systems not only need to understand their current environment, but should also be able to predict future actions conditioned on past states, for instance based on captured camera frames. For certain tasks, detailed predictions such as future video frames are required in the near future, whereas for others it is beneficial to also predict more abstract representations for longer time horizons. However, existing video prediction models mainly focus on forecasting detailed possible outcomes for short time-horizons, hence being of limited use for robot perception and spatial reasoning. We propose Multi-Scale Hierarchical Prediction (MSPred), a novel video prediction model able to forecast future possible outcomes of different levels of granularity at different time-scales simultaneously. By combining spatial and temporal downsampling, MSPred is able to efficiently predict abstract representations such as human poses or object locations over long time horizons, while still maintaining a competitive performance for video frame prediction. In our experiments, we demonstrate that our proposed model accurately predicts future video frames as well as other representations (e.g. keypoints or positions) on various scenarios, including bin-picking scenes or action recognition datasets, consistently outperforming popular approaches for video frame prediction. Furthermore, we conduct an ablation study to investigate the importance of the different modules and design choices in MSPred. In the spirit of reproducible research, we open-source VP-Suite, a general framework for deep-learning-based video prediction, as well as pretrained models to reproduce our results.