 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVideo Prediction at Multiple Scales with Hierarchical Recurrent Networks
Paper and Code
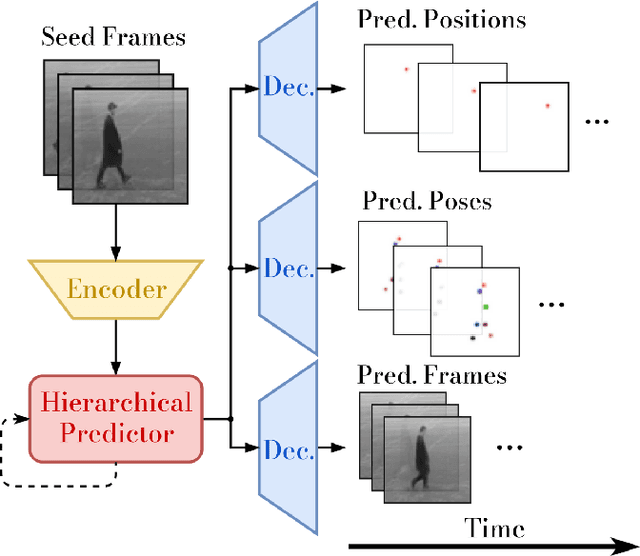
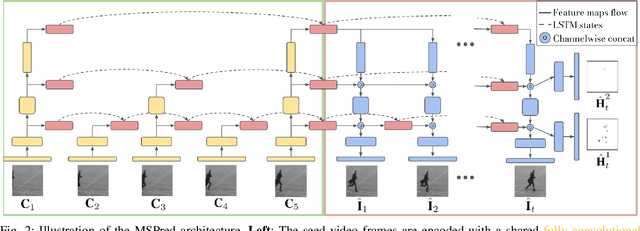
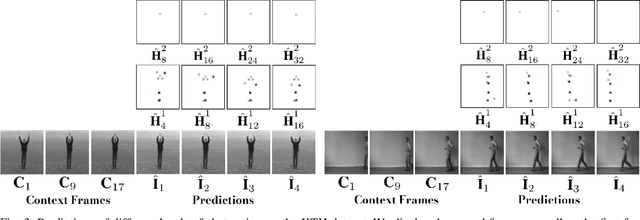

Autonomous systems not only need to understand their current environment, but should also be able to predict future actions conditioned on past states, for instance based on captured camera frames. For certain tasks, detailed predictions such as future video frames are required in the near future, whereas for others it is beneficial to also predict more abstract representations for longer time horizons. However, existing video prediction models mainly focus on forecasting detailed possible outcomes for short time-horizons, hence being of limited use for robot perception and spatial reasoning. We propose Multi-Scale Hierarchical Prediction (MSPred), a novel video prediction model able to forecast future possible outcomes of different levels of granularity at different time-scales simultaneously. By combining spatial and temporal downsampling, MSPred is able to efficiently predict abstract representations such as human poses or object locations over long time horizons, while still maintaining a competitive performance for video frame prediction. In our experiments, we demonstrate that our proposed model accurately predicts future video frames as well as other representations (e.g. keypoints or positions) on various scenarios, including bin-picking scenes or action recognition datasets, consistently outperforming popular approaches for video frame prediction. Furthermore, we conduct an ablation study to investigate the importance of the different modules and design choices in MSPred. In the spirit of reproducible research, we open-source VP-Suite, a general framework for deep-learning-based video prediction, as well as pretrained models to reproduce our results.