 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAMBER: Adaptive Mesh Generation by Iterative Mesh Resolution Prediction
May 29, 2025The cost and accuracy of simulating complex physical systems using the Finite Element Method (FEM) scales with the resolution of the underlying mesh. Adaptive meshes improve computational efficiency by refining resolution in critical regions, but typically require task-specific heuristics or cumbersome manual design by a human expert. We propose Adaptive Meshing By Expert Reconstruction (AMBER), a supervised learning approach to mesh adaptation. Starting from a coarse mesh, AMBER iteratively predicts the sizing field, i.e., a function mapping from the geometry to the local element size of the target mesh, and uses this prediction to produce a new intermediate mesh using an out-of-the-box mesh generator. This process is enabled through a hierarchical graph neural network, and relies on data augmentation by automatically projecting expert labels onto AMBER-generated data during training. We evaluate AMBER on 2D and 3D datasets, including classical physics problems, mechanical components, and real-world industrial designs with human expert meshes. AMBER generalizes to unseen geometries and consistently outperforms multiple recent baselines, including ones using Graph and Convolutional Neural Networks, and Reinforcement Learning-based approaches.
Learning Sub-Second Routing Optimization in Computer Networks requires Packet-Level Dynamics
Oct 14, 2024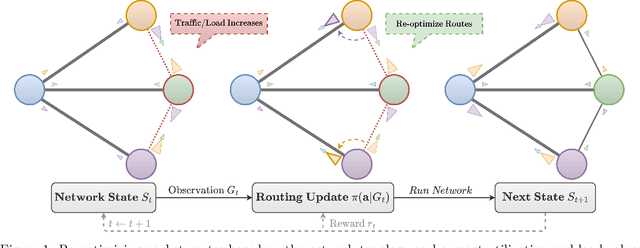
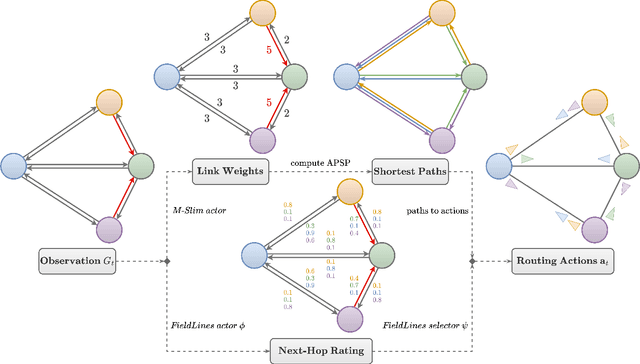
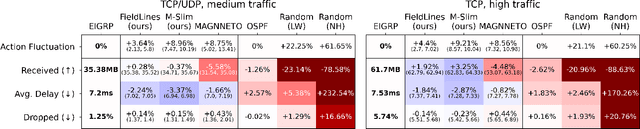
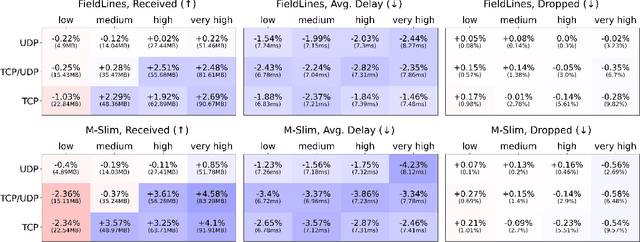
Finding efficient routes for data packets is an essential task in computer networking. The optimal routes depend greatly on the current network topology, state and traffic demand, and they can change within milliseconds. Reinforcement Learning can help to learn network representations that provide routing decisions for possibly novel situations. So far, this has commonly been done using fluid network models. We investigate their suitability for millisecond-scale adaptations with a range of traffic mixes and find that packet-level network models are necessary to capture true dynamics, in particular in the presence of TCP traffic. To this end, we present $\textit{PackeRL}$, the first packet-level Reinforcement Learning environment for routing in generic network topologies. Our experiments confirm that learning-based strategies that have been trained in fluid environments do not generalize well to this more realistic, but more challenging setup. Hence, we also introduce two new algorithms for learning sub-second Routing Optimization. We present $\textit{M-Slim}$, a dynamic shortest-path algorithm that excels at high traffic volumes but is computationally hard to scale to large network topologies, and $\textit{FieldLines}$, a novel next-hop policy design that re-optimizes routing for any network topology within milliseconds without requiring any re-training. Both algorithms outperform current learning-based approaches as well as commonly used static baseline protocols in scenarios with high-traffic volumes. All findings are backed by extensive experiments in realistic network conditions in our fast and versatile training and evaluation framework.
Video Prediction at Multiple Scales with Hierarchical Recurrent Networks
Mar 17, 2022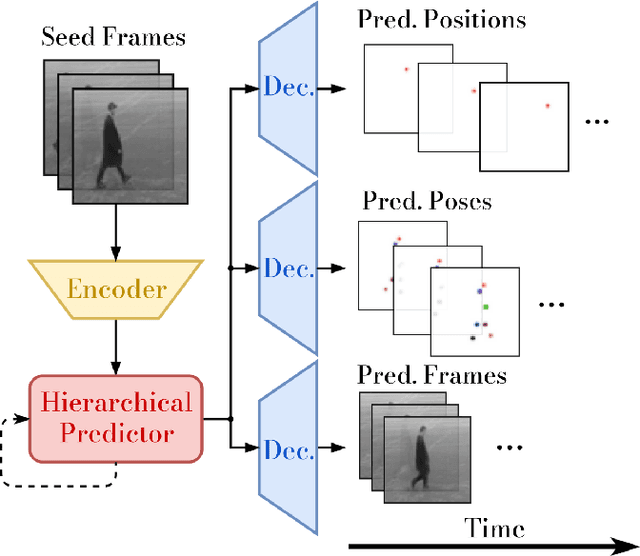
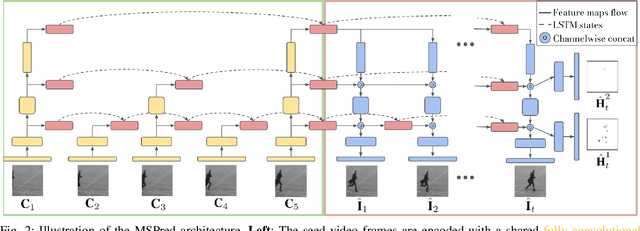
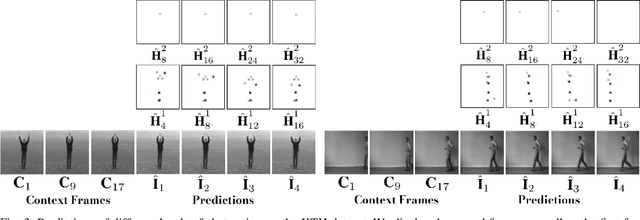

Autonomous systems not only need to understand their current environment, but should also be able to predict future actions conditioned on past states, for instance based on captured camera frames. For certain tasks, detailed predictions such as future video frames are required in the near future, whereas for others it is beneficial to also predict more abstract representations for longer time horizons. However, existing video prediction models mainly focus on forecasting detailed possible outcomes for short time-horizons, hence being of limited use for robot perception and spatial reasoning. We propose Multi-Scale Hierarchical Prediction (MSPred), a novel video prediction model able to forecast future possible outcomes of different levels of granularity at different time-scales simultaneously. By combining spatial and temporal downsampling, MSPred is able to efficiently predict abstract representations such as human poses or object locations over long time horizons, while still maintaining a competitive performance for video frame prediction. In our experiments, we demonstrate that our proposed model accurately predicts future video frames as well as other representations (e.g. keypoints or positions) on various scenarios, including bin-picking scenes or action recognition datasets, consistently outperforming popular approaches for video frame prediction. Furthermore, we conduct an ablation study to investigate the importance of the different modules and design choices in MSPred. In the spirit of reproducible research, we open-source VP-Suite, a general framework for deep-learning-based video prediction, as well as pretrained models to reproduce our results.