 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Sub-Second Routing Optimization in Computer Networks requires Packet-Level Dynamics
Oct 14, 2024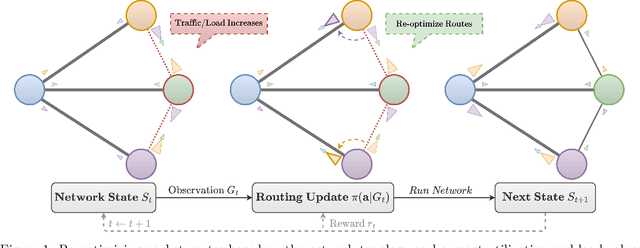
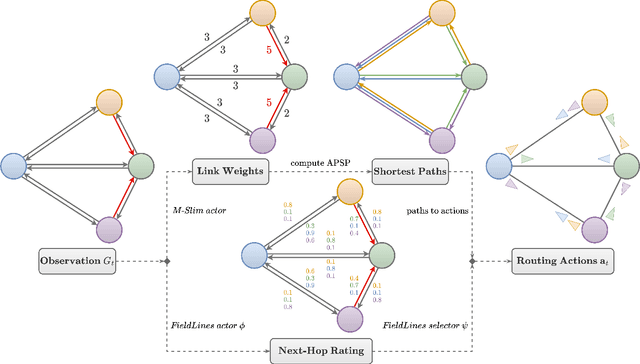
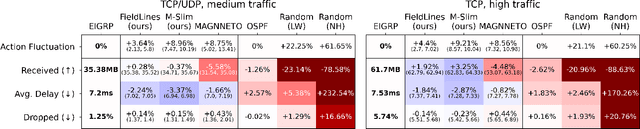
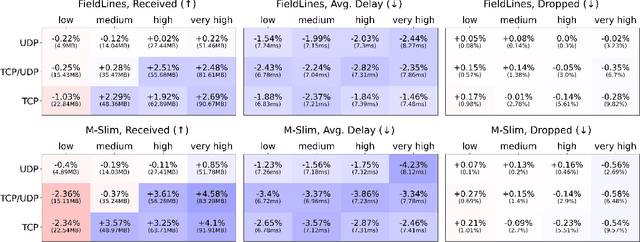
Finding efficient routes for data packets is an essential task in computer networking. The optimal routes depend greatly on the current network topology, state and traffic demand, and they can change within milliseconds. Reinforcement Learning can help to learn network representations that provide routing decisions for possibly novel situations. So far, this has commonly been done using fluid network models. We investigate their suitability for millisecond-scale adaptations with a range of traffic mixes and find that packet-level network models are necessary to capture true dynamics, in particular in the presence of TCP traffic. To this end, we present $\textit{PackeRL}$, the first packet-level Reinforcement Learning environment for routing in generic network topologies. Our experiments confirm that learning-based strategies that have been trained in fluid environments do not generalize well to this more realistic, but more challenging setup. Hence, we also introduce two new algorithms for learning sub-second Routing Optimization. We present $\textit{M-Slim}$, a dynamic shortest-path algorithm that excels at high traffic volumes but is computationally hard to scale to large network topologies, and $\textit{FieldLines}$, a novel next-hop policy design that re-optimizes routing for any network topology within milliseconds without requiring any re-training. Both algorithms outperform current learning-based approaches as well as commonly used static baseline protocols in scenarios with high-traffic volumes. All findings are backed by extensive experiments in realistic network conditions in our fast and versatile training and evaluation framework.
Multi-Objective Optimization Using Adaptive Distributed Reinforcement Learning
Mar 13, 2024



The Intelligent Transportation System (ITS) environment is known to be dynamic and distributed, where participants (vehicle users, operators, etc.) have multiple, changing and possibly conflicting objectives. Although Reinforcement Learning (RL) algorithms are commonly applied to optimize ITS applications such as resource management and offloading, most RL algorithms focus on single objectives. In many situations, converting a multi-objective problem into a single-objective one is impossible, intractable or insufficient, making such RL algorithms inapplicable. We propose a multi-objective, multi-agent reinforcement learning (MARL) algorithm with high learning efficiency and low computational requirements, which automatically triggers adaptive few-shot learning in a dynamic, distributed and noisy environment with sparse and delayed reward. We test our algorithm in an ITS environment with edge cloud computing. Empirical results show that the algorithm is quick to adapt to new environments and performs better in all individual and system metrics compared to the state-of-the-art benchmark. Our algorithm also addresses various practical concerns with its modularized and asynchronous online training method. In addition to the cloud simulation, we test our algorithm on a single-board computer and show that it can make inference in 6 milliseconds.
Stability and Convergence of Distributed Stochastic Approximations with large Unbounded Stochastic Information Delays
May 11, 2023We generalize the Borkar-Meyn stability Theorem (BMT) to distributed stochastic approximations (SAs) with information delays that possess an arbitrary moment bound. To model the delays, we introduce Age of Information Processes (AoIPs): stochastic processes on the non-negative integers with a unit growth property. We show that AoIPs with an arbitrary moment bound cannot exceed any fraction of time infinitely often. In combination with a suitably chosen stepsize, this property turns out to be sufficient for the stability of distributed SAs. Compared to the BMT, our analysis requires crucial modifications and a new line of argument to handle the SA errors caused by AoI. In our analysis, we show that these SA errors satisfy a recursive inequality. To evaluate this recursion, we propose a new Gronwall-type inequality for time-varying lower limits of summations. As applications to our distributed BMT, we discuss distributed gradient-based optimization and a new approach to analyzing SAs with momentum.
Multi-Agent Reinforcement Learning for Long-Term Network Resource Allocation through Auction: a V2X Application
Jul 29, 2022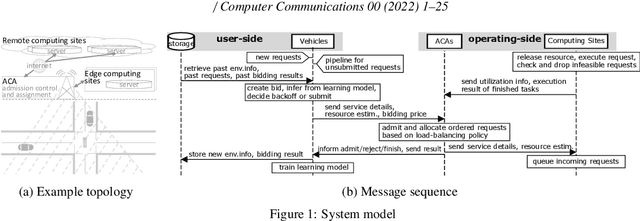



We formulate offloading of computational tasks from a dynamic group of mobile agents (e.g., cars) as decentralized decision making among autonomous agents. We design an interaction mechanism that incentivizes such agents to align private and system goals by balancing between competition and cooperation. In the static case, the mechanism provably has Nash equilibria with optimal resource allocation. In a dynamic environment, this mechanism's requirement of complete information is impossible to achieve. For such environments, we propose a novel multi-agent online learning algorithm that learns with partial, delayed and noisy state information, thus greatly reducing information need. Our algorithm is also capable of learning from long-term and sparse reward signals with varying delay. Empirical results from the simulation of a V2X application confirm that through learning, agents with the learning algorithm significantly improve both system and individual performance, reducing up to 30% of offloading failure rate, communication overhead and load variation, increasing computation resource utilization and fairness. Results also confirm the algorithm's good convergence and generalization property in different environments.
Learning to Bid Long-Term: Multi-Agent Reinforcement Learning with Long-Term and Sparse Reward in Repeated Auction Games
Apr 05, 2022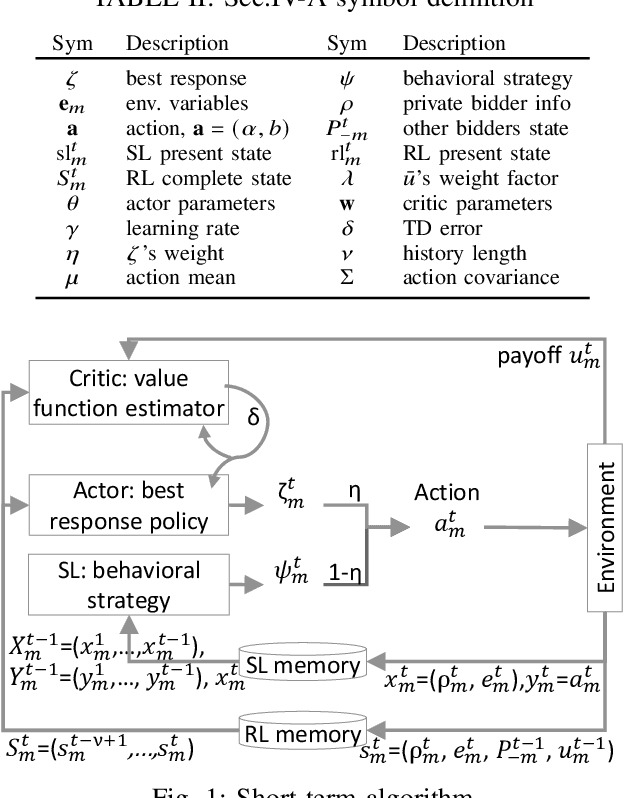
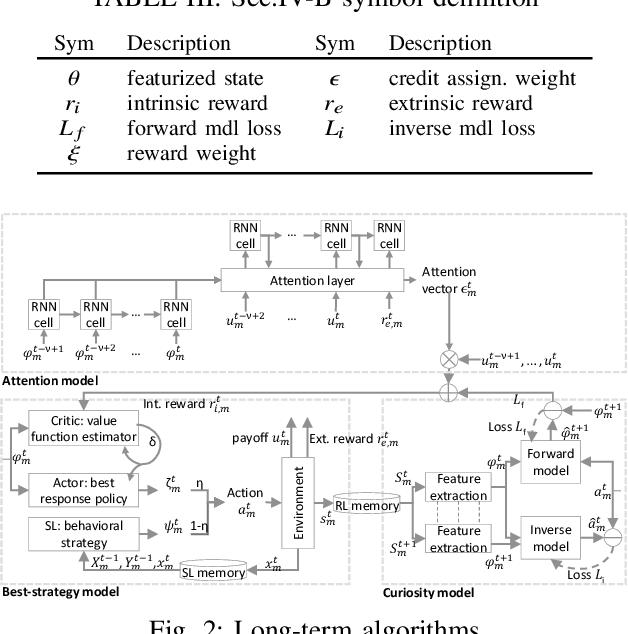
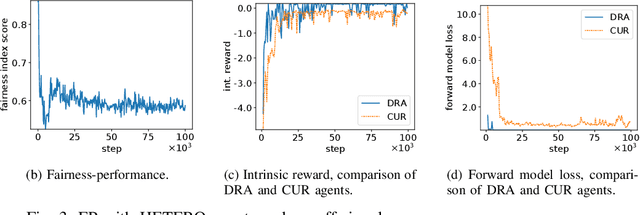
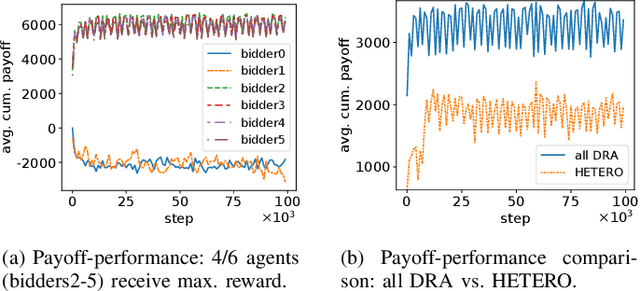
We propose a multi-agent distributed reinforcement learning algorithm that balances between potentially conflicting short-term reward and sparse, delayed long-term reward, and learns with partial information in a dynamic environment. We compare different long-term rewards to incentivize the algorithm to maximize individual payoff and overall social welfare. We test the algorithm in two simulated auction games, and demonstrate that 1) our algorithm outperforms two benchmark algorithms in a direct competition, with cost to social welfare, and 2) our algorithm's aggressive competitive behavior can be guided with the long-term reward signal to maximize both individual payoff and overall social welfare.
Multi-Agent Distributed Reinforcement Learning for Making Decentralized Offloading Decisions
Apr 05, 2022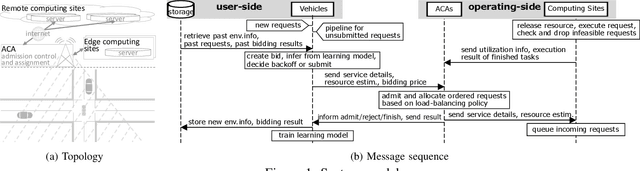
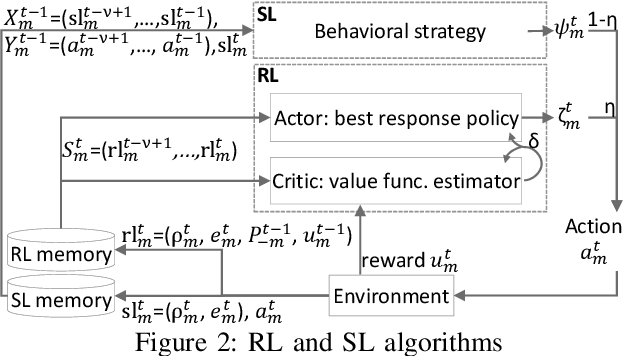
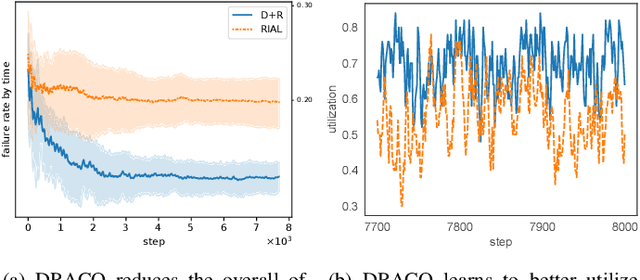

We formulate computation offloading as a decentralized decision-making problem with autonomous agents. We design an interaction mechanism that incentivizes agents to align private and system goals by balancing between competition and cooperation. The mechanism provably has Nash equilibria with optimal resource allocation in the static case. For a dynamic environment, we propose a novel multi-agent online learning algorithm that learns with partial, delayed and noisy state information, and a reward signal that reduces information need to a great extent. Empirical results confirm that through learning, agents significantly improve both system and individual performance, e.g., 40% offloading failure rate reduction, 32% communication overhead reduction, up to 38% computation resource savings in low contention, 18% utilization increase with reduced load variation in high contention, and improvement in fairness. Results also confirm the algorithm's good convergence and generalization property in significantly different environments.
Distributed gradient-based optimization in the presence of dependent aperiodic communication
Jan 27, 2022Iterative distributed optimization algorithms involve multiple agents that communicate with each other, over time, in order to minimize/maximize a global objective. In the presence of unreliable communication networks, the Age-of-Information (AoI), which measures the freshness of data received, may be large and hence hinder algorithmic convergence. In this paper, we study the convergence of general distributed gradient-based optimization algorithms in the presence of communication that neither happens periodically nor at stochastically independent points in time. We show that convergence is guaranteed provided the random variables associated with the AoI processes are stochastically dominated by a random variable with finite first moment. This improves on previous requirements of boundedness of more than the first moment. We then introduce stochastically strongly connected (SSC) networks, a new stochastic form of strong connectedness for time-varying networks. We show: If for any $p \ge0$ the processes that describe the success of communication between agents in a SSC network are $\alpha$-mixing with $n^{p-1}\alpha(n)$ summable, then the associated AoI processes are stochastically dominated by a random variable with finite $p$-th moment. In combination with our first contribution, this implies that distributed stochastic gradient descend converges in the presence of AoI, if $\alpha(n)$ is summable.
Asymptotic Convergence of Deep Multi-Agent Actor-Critic Algorithms
Jan 03, 2022
We present sufficient conditions that ensure convergence of the multi-agent Deep Deterministic Policy Gradient (DDPG) algorithm. It is an example of one of the most popular paradigms of Deep Reinforcement Learning (DeepRL) for tackling continuous action spaces: the actor-critic paradigm. In the setting considered herein, each agent observes a part of the global state space in order to take local actions, for which it receives local rewards. For every agent, DDPG trains a local actor (policy) and a local critic (Q-function). The analysis shows that multi-agent DDPG using neural networks to approximate the local policies and critics converge to limits with the following properties: The critic limits minimize the average squared Bellman loss; the actor limits parameterize a policy that maximizes the local critic's approximation of $Q_i^*$, where $i$ is the agent index. The averaging is with respect to a probability distribution over the global state-action space. It captures the asymptotics of all local training processes. Finally, we extend the analysis to a fully decentralized setting where agents communicate over a wireless network prone to delays and losses; a typical scenario in, e.g., robotic applications.
Reinforcement Learning for Admission Control in Wireless Virtual Network Embedding
Oct 04, 2021


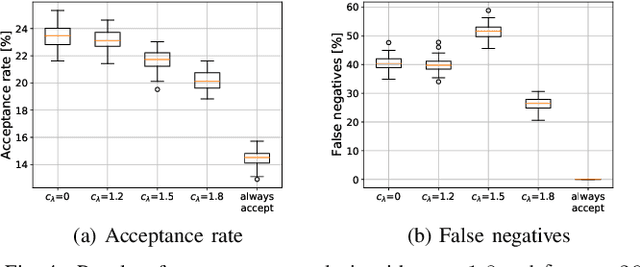
Using Service Function Chaining (SFC) in wireless networks became popular in many domains like networking and multimedia. It relies on allocating network resources to incoming SFCs requests, via a Virtual Network Embedding (VNE) algorithm, so that it optimizes the performance of the SFC. When the load of incoming requests -- competing for the limited network resources - increases, it becomes challenging to decide which requests should be admitted and which one should be rejected. In this work, we propose a deep Reinforcement learning (RL) solution that can learn the admission policy for different dependencies, such as the service lifetime and the priority of incoming requests. We compare the deep RL solution to a first-come-first-serve baseline that admits a request whenever there are available resources. We show that deep RL outperforms the baseline and provides higher acceptance rate with low rejections even when there are enough resources.
DeepCAS: A Deep Reinforcement Learning Algorithm for Control-Aware Scheduling
Jun 13, 2018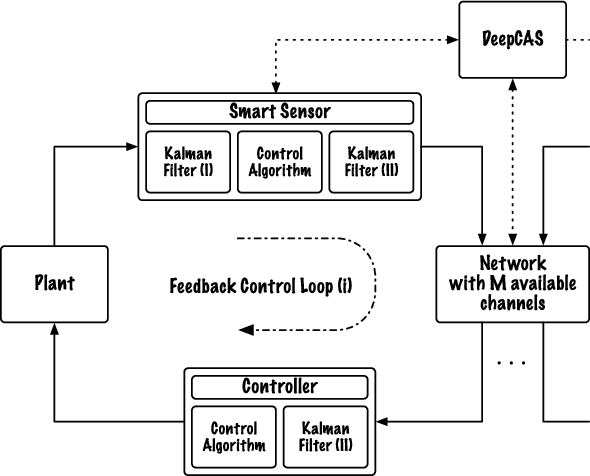
We consider networked control systems consisting of multiple independent controlled subsystems, operating over a shared communication network. Such systems are ubiquitous in cyber-physical systems, Internet of Things, and large-scale industrial systems. In many large-scale settings, the size of the communication network is smaller than the size of the system. In consequence, scheduling issues arise. The main contribution of this paper is to develop a deep reinforcement learning-based \emph{control-aware} scheduling (\textsc{DeepCAS}) algorithm to tackle these issues. We use the following (optimal) design strategy: First, we synthesize an optimal controller for each subsystem; next, we design a learning algorithm that adapts to the chosen subsystems (plants) and controllers. As a consequence of this adaptation, our algorithm finds a schedule that minimizes the \emph{control loss}. We present empirical results to show that \textsc{DeepCAS} finds schedules with better performance than periodic ones.