 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeC-STEP: Continuous Space-Time Empowerment for Physics-informed Safe Reinforcement Learning of Mobile Agents
Mar 25, 2026Safe navigation in complex environments remains a central challenge for reinforcement learning (RL) in robotics. This paper introduces Continuous Space-Time Empowerment for Physics-informed (C-STEP) safe RL, a novel measure of agent-centric safety tailored to deterministic, continuous domains. This measure can be used to design physics-informed intrinsic rewards by augmenting positive navigation reward functions. The reward incorporates the agents internal states (e.g., initial velocity) and forward dynamics to differentiate safe from risky behavior. By integrating C-STEP with navigation rewards, we obtain an intrinsic reward function that jointly optimizes task completion and collision avoidance. Numerical results demonstrate fewer collisions, reduced proximity to obstacles, and only marginal increases in travel time. Overall, C-STEP offers an interpretable, physics-informed approach to reward shaping in RL, contributing to safety for agentic mobile robotic systems.
Stability and Convergence of Distributed Stochastic Approximations with large Unbounded Stochastic Information Delays
May 11, 2023We generalize the Borkar-Meyn stability Theorem (BMT) to distributed stochastic approximations (SAs) with information delays that possess an arbitrary moment bound. To model the delays, we introduce Age of Information Processes (AoIPs): stochastic processes on the non-negative integers with a unit growth property. We show that AoIPs with an arbitrary moment bound cannot exceed any fraction of time infinitely often. In combination with a suitably chosen stepsize, this property turns out to be sufficient for the stability of distributed SAs. Compared to the BMT, our analysis requires crucial modifications and a new line of argument to handle the SA errors caused by AoI. In our analysis, we show that these SA errors satisfy a recursive inequality. To evaluate this recursion, we propose a new Gronwall-type inequality for time-varying lower limits of summations. As applications to our distributed BMT, we discuss distributed gradient-based optimization and a new approach to analyzing SAs with momentum.
Distributed gradient-based optimization in the presence of dependent aperiodic communication
Jan 27, 2022Iterative distributed optimization algorithms involve multiple agents that communicate with each other, over time, in order to minimize/maximize a global objective. In the presence of unreliable communication networks, the Age-of-Information (AoI), which measures the freshness of data received, may be large and hence hinder algorithmic convergence. In this paper, we study the convergence of general distributed gradient-based optimization algorithms in the presence of communication that neither happens periodically nor at stochastically independent points in time. We show that convergence is guaranteed provided the random variables associated with the AoI processes are stochastically dominated by a random variable with finite first moment. This improves on previous requirements of boundedness of more than the first moment. We then introduce stochastically strongly connected (SSC) networks, a new stochastic form of strong connectedness for time-varying networks. We show: If for any $p \ge0$ the processes that describe the success of communication between agents in a SSC network are $\alpha$-mixing with $n^{p-1}\alpha(n)$ summable, then the associated AoI processes are stochastically dominated by a random variable with finite $p$-th moment. In combination with our first contribution, this implies that distributed stochastic gradient descend converges in the presence of AoI, if $\alpha(n)$ is summable.
Asymptotic Convergence of Deep Multi-Agent Actor-Critic Algorithms
Jan 03, 2022
We present sufficient conditions that ensure convergence of the multi-agent Deep Deterministic Policy Gradient (DDPG) algorithm. It is an example of one of the most popular paradigms of Deep Reinforcement Learning (DeepRL) for tackling continuous action spaces: the actor-critic paradigm. In the setting considered herein, each agent observes a part of the global state space in order to take local actions, for which it receives local rewards. For every agent, DDPG trains a local actor (policy) and a local critic (Q-function). The analysis shows that multi-agent DDPG using neural networks to approximate the local policies and critics converge to limits with the following properties: The critic limits minimize the average squared Bellman loss; the actor limits parameterize a policy that maximizes the local critic's approximation of $Q_i^*$, where $i$ is the agent index. The averaging is with respect to a probability distribution over the global state-action space. It captures the asymptotics of all local training processes. Finally, we extend the analysis to a fully decentralized setting where agents communicate over a wireless network prone to delays and losses; a typical scenario in, e.g., robotic applications.
Deep reinforcement learning for scheduling in large-scale networked control systems
May 15, 2019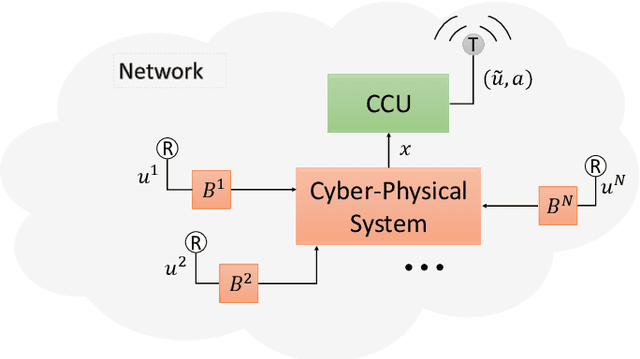

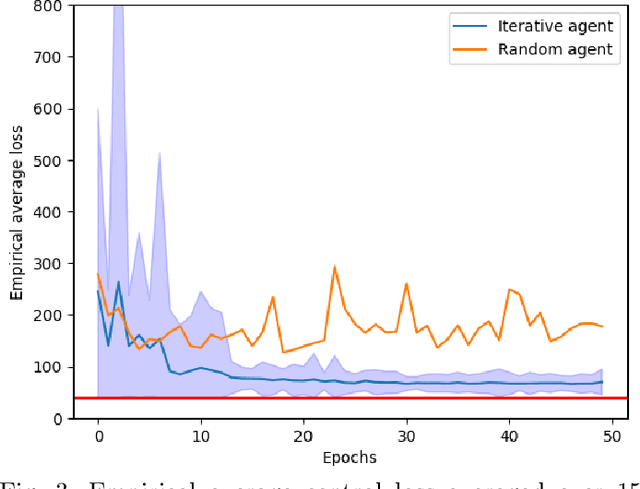
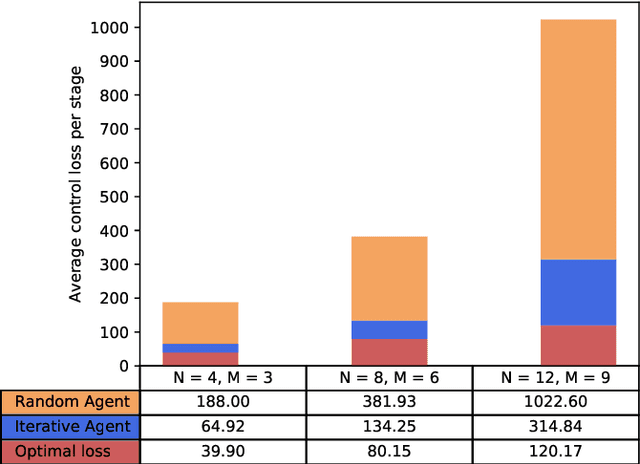
This work considers the problem of control and resource scheduling in networked systems. We present DIRA, a Deep reinforcement learning based Iterative Resource Allocation algorithm, which is scalable and control-aware. Our algorithm is tailored towards large-scale problems where control and scheduling need to act jointly to optimize performance. DIRA can be used to schedule general time-domain optimization based controllers. In the present work, we focus on control designs based on suitably adapted linear quadratic regulators. We apply our algorithm to networked systems with correlated fading communication channels. Our simulations show that DIRA scales well to large scheduling problems.