 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStructure-Enhanced DRL for Optimal Transmission Scheduling
Dec 24, 2022



Remote state estimation of large-scale distributed dynamic processes plays an important role in Industry 4.0 applications. In this paper, we focus on the transmission scheduling problem of a remote estimation system. First, we derive some structural properties of the optimal sensor scheduling policy over fading channels. Then, building on these theoretical guidelines, we develop a structure-enhanced deep reinforcement learning (DRL) framework for optimal scheduling of the system to achieve the minimum overall estimation mean-square error (MSE). In particular, we propose a structure-enhanced action selection method, which tends to select actions that obey the policy structure. This explores the action space more effectively and enhances the learning efficiency of DRL agents. Furthermore, we introduce a structure-enhanced loss function to add penalties to actions that do not follow the policy structure. The new loss function guides the DRL to converge to the optimal policy structure quickly. Our numerical experiments illustrate that the proposed structure-enhanced DRL algorithms can save the training time by 50% and reduce the remote estimation MSE by 10% to 25% when compared to benchmark DRL algorithms. In addition, we show that the derived structural properties exist in a wide range of dynamic scheduling problems that go beyond remote state estimation.
Structure-Enhanced Deep Reinforcement Learning for Optimal Transmission Scheduling
Nov 20, 2022Remote state estimation of large-scale distributed dynamic processes plays an important role in Industry 4.0 applications. In this paper, by leveraging the theoretical results of structural properties of optimal scheduling policies, we develop a structure-enhanced deep reinforcement learning (DRL) framework for optimal scheduling of a multi-sensor remote estimation system to achieve the minimum overall estimation mean-square error (MSE). In particular, we propose a structure-enhanced action selection method, which tends to select actions that obey the policy structure. This explores the action space more effectively and enhances the learning efficiency of DRL agents. Furthermore, we introduce a structure-enhanced loss function to add penalty to actions that do not follow the policy structure. The new loss function guides the DRL to converge to the optimal policy structure quickly. Our numerical results show that the proposed structure-enhanced DRL algorithms can save the training time by 50% and reduce the remote estimation MSE by 10% to 25%, when compared to benchmark DRL algorithms.
Deep Learning for Wireless Networked Systems: a joint Estimation-Control-Scheduling Approach
Oct 03, 2022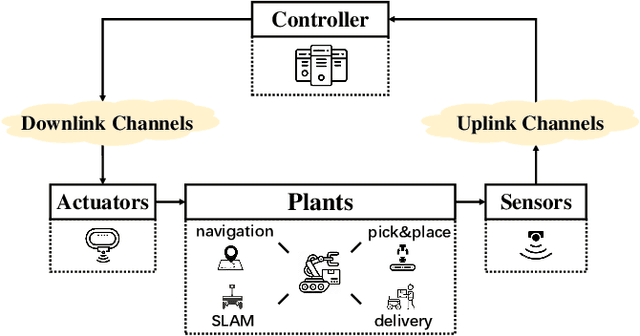
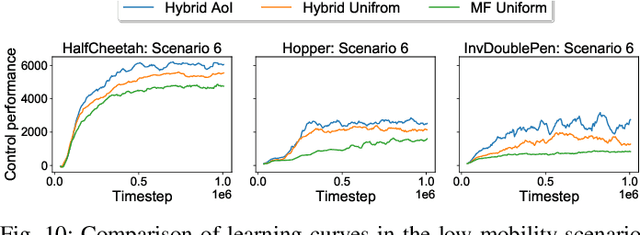
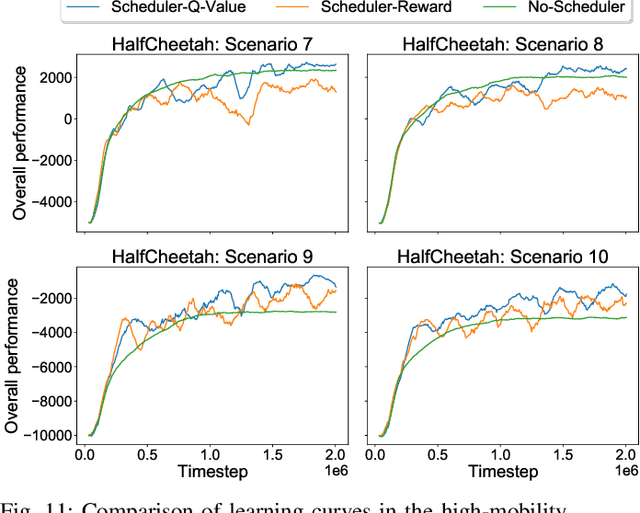
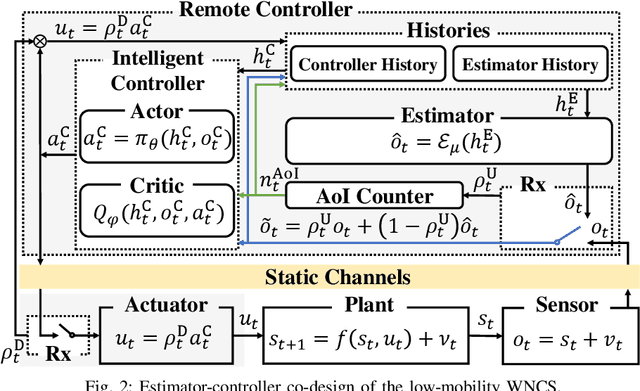
Wireless networked control system (WNCS) connecting sensors, controllers, and actuators via wireless communications is a key enabling technology for highly scalable and low-cost deployment of control systems in the Industry 4.0 era. Despite the tight interaction of control and communications in WNCSs, most existing works adopt separative design approaches. This is mainly because the co-design of control-communication policies requires large and hybrid state and action spaces, making the optimal problem mathematically intractable and difficult to be solved effectively by classic algorithms. In this paper, we systematically investigate deep learning (DL)-based estimator-control-scheduler co-design for a model-unknown nonlinear WNCS over wireless fading channels. In particular, we propose a co-design framework with the awareness of the sensor's age-of-information (AoI) states and dynamic channel states. We propose a novel deep reinforcement learning (DRL)-based algorithm for controller and scheduler optimization utilizing both model-free and model-based data. An AoI-based importance sampling algorithm that takes into account the data accuracy is proposed for enhancing learning efficiency. We also develop novel schemes for enhancing the stability of joint training. Extensive experiments demonstrate that the proposed joint training algorithm can effectively solve the estimation-control-scheduling co-design problem in various scenarios and provide significant performance gain compared to separative design and some benchmark policies.
Bayesian Quickest Change Detection of an Intruder in Acknowledgments for Private Remote State Estimation
Jul 18, 2022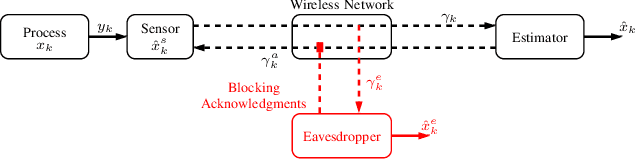


For geographically separated cyber-physical systems, state estimation at a remote monitoring or control site is important to ensure stability and reliability of the system. Often for safety or commercial reasons it is necessary to ensure confidentiality of the process state and control information. A current topic of interest is the private transmission of confidential state information. Many transmission encoding schemes rely on acknowledgments, which may be susceptible to interference from an adversary. We consider a stealthy intruder that selectively blocks acknowledgments allowing an eavesdropper to obtain a reliable state estimate defeating an encoding scheme. We utilize Bayesian Quickest Change Detection techniques to quickly detect online the presence of an intruder at both the remote transmitter and receiver.
Stability Enforced Bandit Algorithms for Channel Selection in Remote State Estimation
May 20, 2022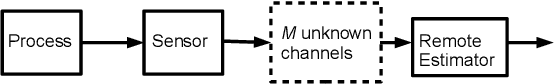

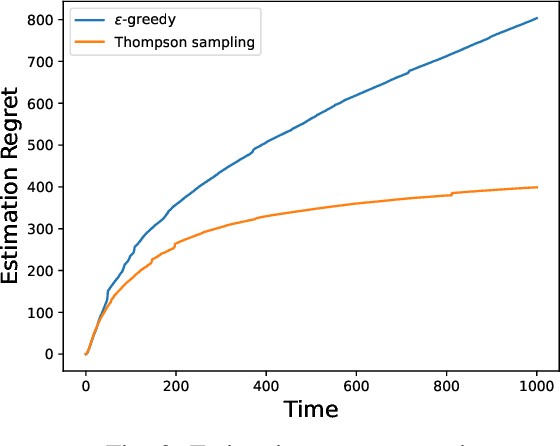
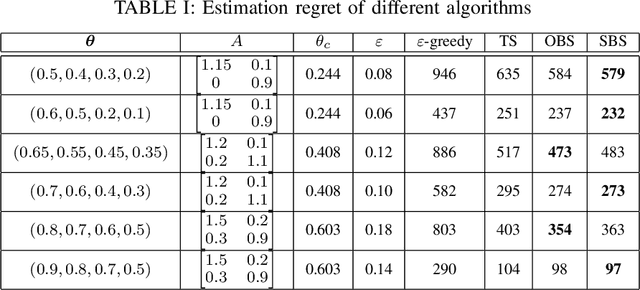
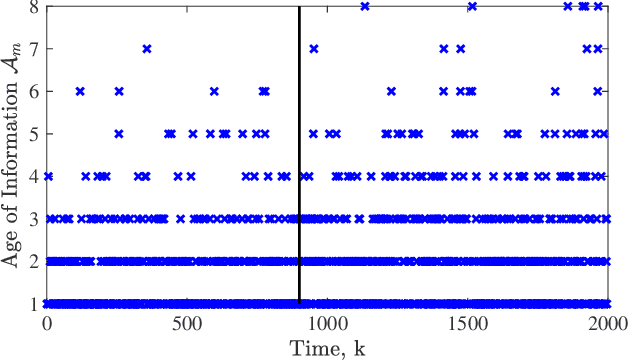
In this paper we consider a remote state estimation problem where a sensor can, at each discrete time instant, transmit on one out of M different communication channels. A key difficulty of the situation at hand is that the channel statistics are unknown. We study the case where both learning of the channel reception probabilities and state estimation is carried out simultaneously. Methods for choosing the channels based on techniques for multi-armed bandits are presented, and shown to provide stability of the remote estimator. Furthermore, we define the performance notion of estimation regret, and derive bounds on how it scales with time for the considered algorithms.
Remote State Estimation of Multiple Systems over Semi-Markov Wireless Fading Channels
Mar 31, 2022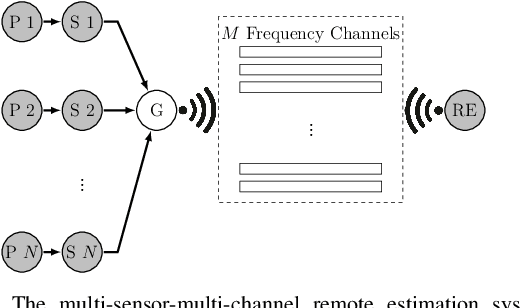
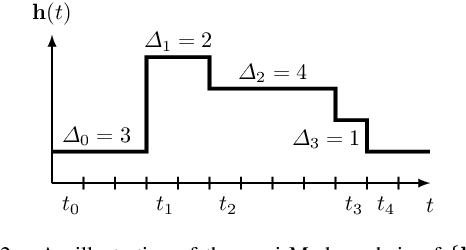
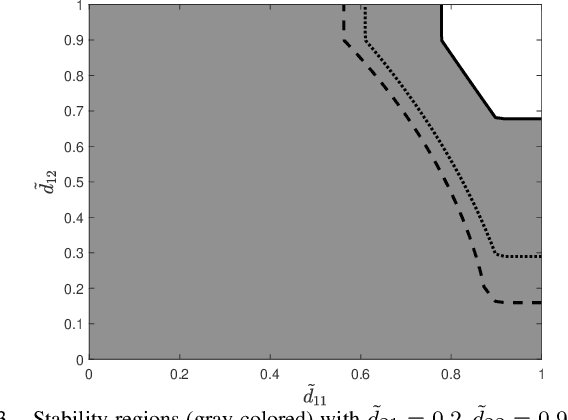

This work studies remote state estimation of multiple linear time-invariant systems over shared wireless time-varying communication channels. We model the channel states by a semi-Markov process which captures both the random holding period of each channel state and the state transitions. The model is sufficiently general to be used in both fast and slow fading scenarios. We derive necessary and sufficient stability conditions of the multi-sensor-multi-channel system in terms of the system parameters. We further investigate how the delay of the channel state information availability and the holding period of channel states affect the stability. In particular, we show that, from a system stability perspective, fast fading channels may be preferable to slow fading ones.
Deep Reinforcement Learning for Wireless Scheduling in Distributed Networked Control
Sep 26, 2021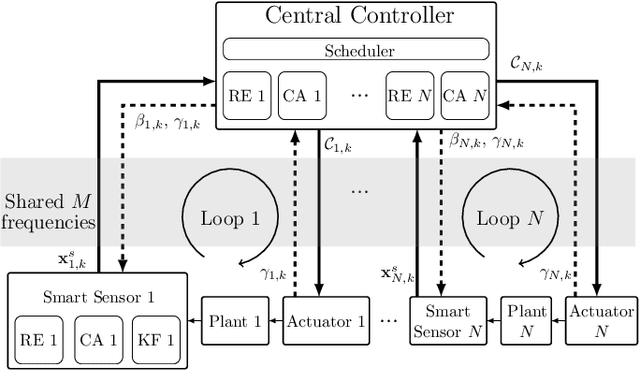

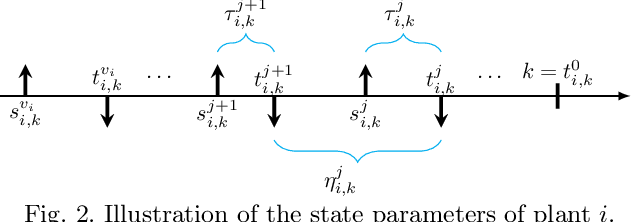
In the literature of transmission scheduling in wireless networked control systems (WNCSs) over shared wireless resources, most research works have focused on partially distributed settings, i.e., where either the controller and actuator, or the sensor and controller are co-located. To overcome this limitation, the present work considers a fully distributed WNCS with distributed plants, sensors, actuators and a controller, sharing a limited number of frequency channels. To overcome communication limitations, the controller schedules the transmissions and generates sequential predictive commands for control. Using elements of stochastic systems theory, we derive a sufficient stability condition of the WNCS, which is stated in terms of both the control and communication system parameters. Once the condition is satisfied, there exists at least one stationary and deterministic scheduling policy that can stabilize all plants of the WNCS. By analyzing and representing the per-step cost function of the WNCS in terms of a finite-length countable vector state, we formulate the optimal transmission scheduling problem into a Markov decision process problem and develop a deep-reinforcement-learning-based algorithm for solving it. Numerical results show that the proposed algorithm significantly outperforms the benchmark policies.
Deep reinforcement learning for scheduling in large-scale networked control systems
May 15, 2019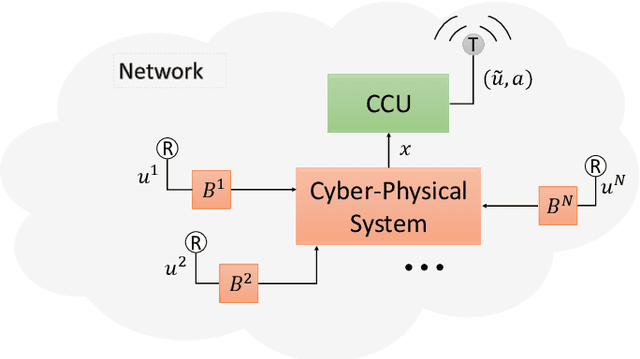

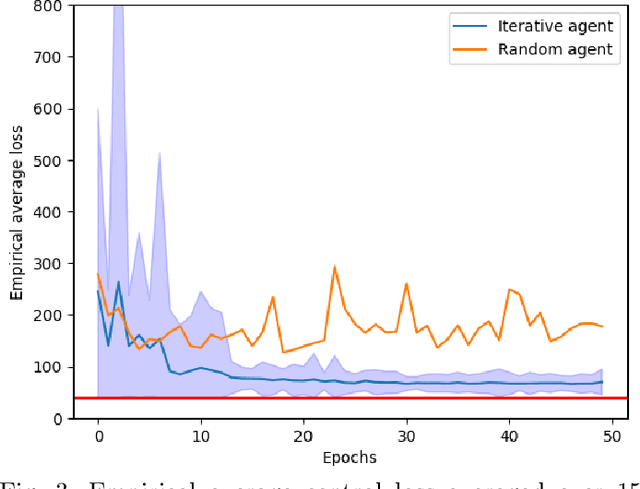
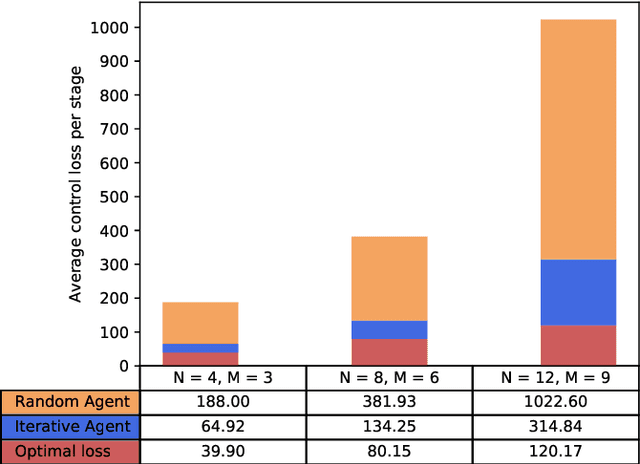
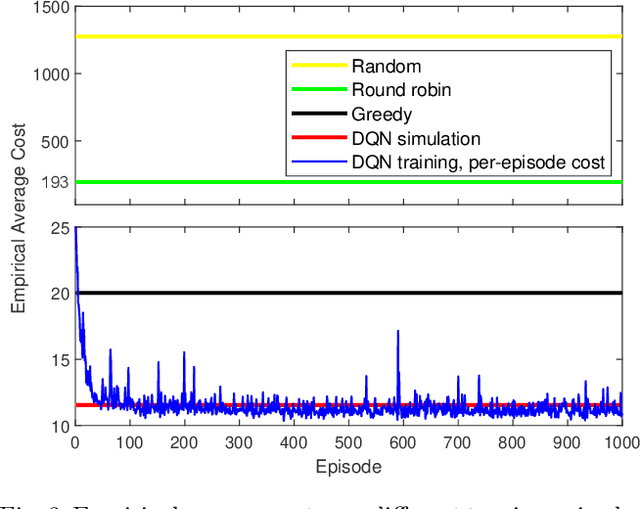
This work considers the problem of control and resource scheduling in networked systems. We present DIRA, a Deep reinforcement learning based Iterative Resource Allocation algorithm, which is scalable and control-aware. Our algorithm is tailored towards large-scale problems where control and scheduling need to act jointly to optimize performance. DIRA can be used to schedule general time-domain optimization based controllers. In the present work, we focus on control designs based on suitably adapted linear quadratic regulators. We apply our algorithm to networked systems with correlated fading communication channels. Our simulations show that DIRA scales well to large scheduling problems.
DeepCAS: A Deep Reinforcement Learning Algorithm for Control-Aware Scheduling
Jun 13, 2018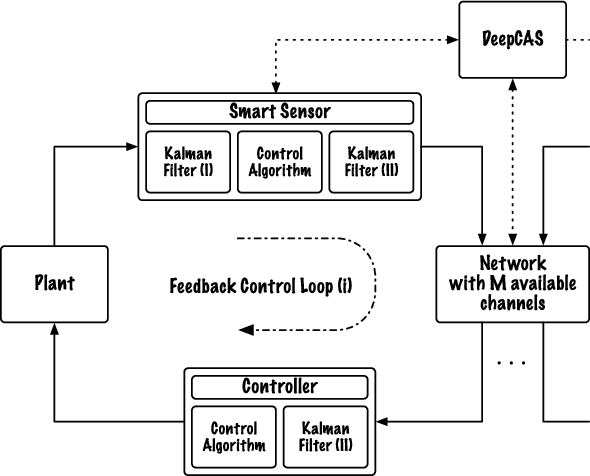
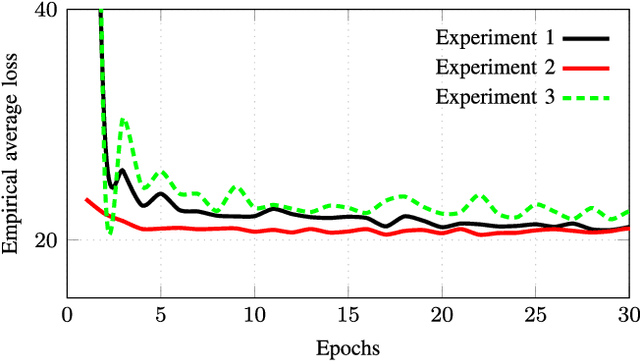
We consider networked control systems consisting of multiple independent controlled subsystems, operating over a shared communication network. Such systems are ubiquitous in cyber-physical systems, Internet of Things, and large-scale industrial systems. In many large-scale settings, the size of the communication network is smaller than the size of the system. In consequence, scheduling issues arise. The main contribution of this paper is to develop a deep reinforcement learning-based \emph{control-aware} scheduling (\textsc{DeepCAS}) algorithm to tackle these issues. We use the following (optimal) design strategy: First, we synthesize an optimal controller for each subsystem; next, we design a learning algorithm that adapts to the chosen subsystems (plants) and controllers. As a consequence of this adaptation, our algorithm finds a schedule that minimizes the \emph{control loss}. We present empirical results to show that \textsc{DeepCAS} finds schedules with better performance than periodic ones.
Asynchronous stochastic approximations with asymptotically biased errors and deep multi-agent learning
Feb 22, 2018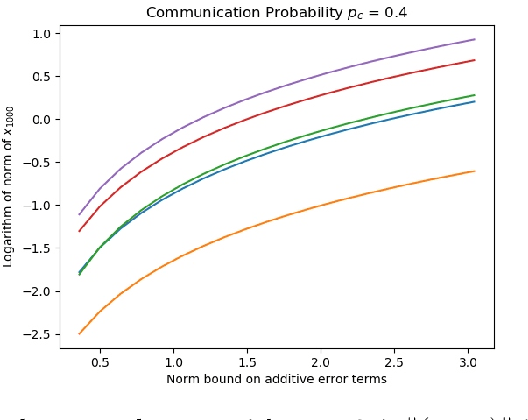
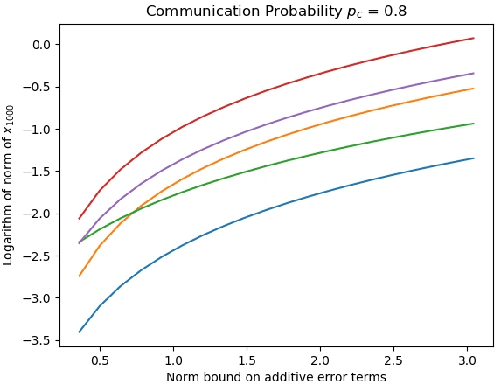
Asynchronous stochastic approximations are an important class of model-free algorithms that are readily applicable to multi-agent reinforcement learning (RL) and distributed control applications. When the system size is large, the aforementioned algorithms are used in conjunction with function approximations. In this paper, we present a complete analysis, including stability (almost sure boundedness) and convergence, of asynchronous stochastic approximations with asymptotically bounded biased errors, under easily verifiable sufficient conditions. As an application, we analyze the Policy Gradient algorithms and the more general Value Iteration based algorithms with noise. These are popular reinforcement learning algorithms due to their simplicity and effectiveness. Specifically, we analyze the asynchronous approximate counterpart of policy gradient (A2PG) and value iteration (A2VI) schemes. It is shown that the stability of these algorithms remains unaffected when the approximation errors are guaranteed to be asymptotically bounded, although possibly biased. Regarding convergence of A2VI, it is shown to converge to a fixed point of the perturbed Bellman operator when balanced step-sizes are used. Further, a relationship between these fixed points and the approximation errors is established. A similar analysis for A2PG is also presented.