 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAGILOped: Agile Open-Source Humanoid Robot for Research
Sep 11, 2025With academic and commercial interest for humanoid robots peaking, multiple platforms are being developed. Through a high level of customization, they showcase impressive performance. Most of these systems remain closed-source or have high acquisition and maintenance costs, however. In this work, we present AGILOped - an open-source humanoid robot that closes the gap between high performance and accessibility. Our robot is driven by off-the-shelf backdrivable actuators with high power density and uses standard electronic components. With a height of 110 cm and weighing only 14.5 kg, AGILOped can be operated without a gantry by a single person. Experiments in walking, jumping, impact mitigation and getting-up demonstrate its viability for use in research.
CamContextI2V: Context-aware Controllable Video Generation
Apr 08, 2025Recently, image-to-video (I2V) diffusion models have demonstrated impressive scene understanding and generative quality, incorporating image conditions to guide generation. However, these models primarily animate static images without extending beyond their provided context. Introducing additional constraints, such as camera trajectories, can enhance diversity but often degrades visual quality, limiting their applicability for tasks requiring faithful scene representation. We propose CamContextI2V, an I2V model that integrates multiple image conditions with 3D constraints alongside camera control to enrich both global semantics and fine-grained visual details. This enables more coherent and context-aware video generation. Moreover, we motivate the necessity of temporal awareness for an effective context representation. Our comprehensive study on the RealEstate10K dataset demonstrates improvements in visual quality and camera controllability. We make our code and models publicly available at: https://github.com/LDenninger/CamContextI2V.
RoboCup 2023 Humanoid AdultSize Winner NimbRo: NimbRoNet3 Visual Perception and Responsive Gait with Waveform In-walk Kicks
Jan 11, 2024



The RoboCup Humanoid League holds annual soccer robot world championships towards the long-term objective of winning against the FIFA world champions by 2050. The participating teams continuously improve their systems. This paper presents the upgrades to our humanoid soccer system, leading our team NimbRo to win the Soccer Tournament in the Humanoid AdultSize League at RoboCup 2023 in Bordeaux, France. The mentioned upgrades consist of: an updated model architecture for visual perception, extended fused angles feedback mechanisms and an additional COM-ZMP controller for walking robustness, and parametric in-walk kicks through waveforms.
Learning Implicit Probability Distribution Functions for Symmetric Orientation Estimation from RGB Images Without Pose Labels
Nov 21, 2022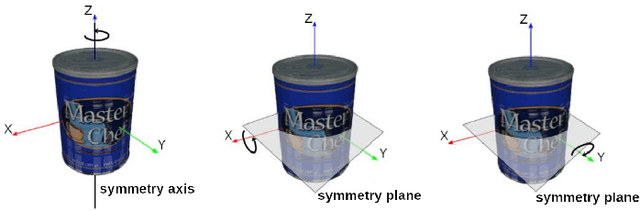
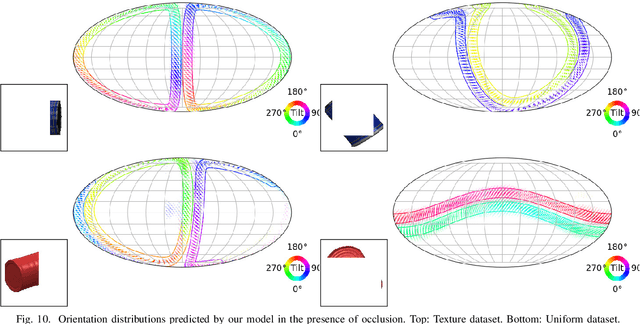
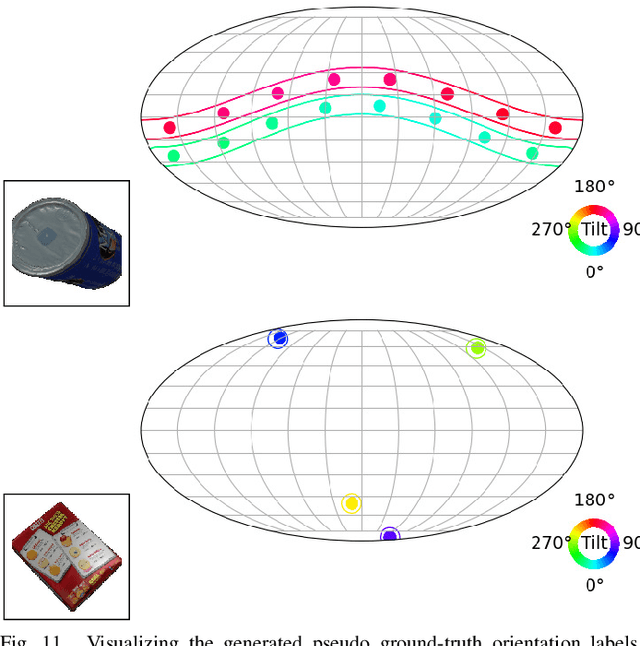

Object pose estimation is a necessary prerequisite for autonomous robotic manipulation, but the presence of symmetry increases the complexity of the pose estimation task. Existing methods for object pose estimation output a single 6D pose. Thus, they lack the ability to reason about symmetries. Lately, modeling object orientation as a non-parametric probability distribution on the SO(3) manifold by neural networks has shown impressive results. However, acquiring large-scale datasets to train pose estimation models remains a bottleneck. To address this limitation, we introduce an automatic pose labeling scheme. Given RGB-D images without object pose annotations and 3D object models, we design a two-stage pipeline consisting of point cloud registration and render-and-compare validation to generate multiple symmetrical pseudo-ground-truth pose labels for each image. Using the generated pose labels, we train an ImplicitPDF model to estimate the likelihood of an orientation hypothesis given an RGB image. An efficient hierarchical sampling of the SO(3) manifold enables tractable generation of the complete set of symmetries at multiple resolutions. During inference, the most likely orientation of the target object is estimated using gradient ascent. We evaluate the proposed automatic pose labeling scheme and the ImplicitPDF model on a photorealistic dataset and the T-Less dataset, demonstrating the advantages of the proposed method.