 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMOTPose: Multi-object 6D Pose Estimation for Dynamic Video Sequences using Attention-based Temporal Fusion
Mar 14, 2024Cluttered bin-picking environments are challenging for pose estimation models. Despite the impressive progress enabled by deep learning, single-view RGB pose estimation models perform poorly in cluttered dynamic environments. Imbuing the rich temporal information contained in the video of scenes has the potential to enhance models ability to deal with the adverse effects of occlusion and the dynamic nature of the environments. Moreover, joint object detection and pose estimation models are better suited to leverage the co-dependent nature of the tasks for improving the accuracy of both tasks. To this end, we propose attention-based temporal fusion for multi-object 6D pose estimation that accumulates information across multiple frames of a video sequence. Our MOTPose method takes a sequence of images as input and performs joint object detection and pose estimation for all objects in one forward pass. It learns to aggregate both object embeddings and object parameters over multiple time steps using cross-attention-based fusion modules. We evaluate our method on the physically-realistic cluttered bin-picking dataset SynPick and the YCB-Video dataset and demonstrate improved pose estimation accuracy as well as better object detection accuracy
Efficient Multi-Object Pose Estimation using Multi-Resolution Deformable Attention and Query Aggregation
Dec 13, 2023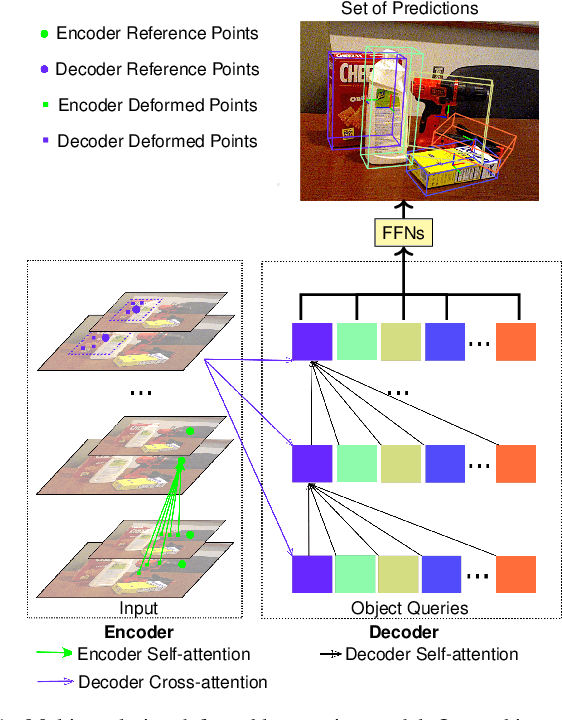
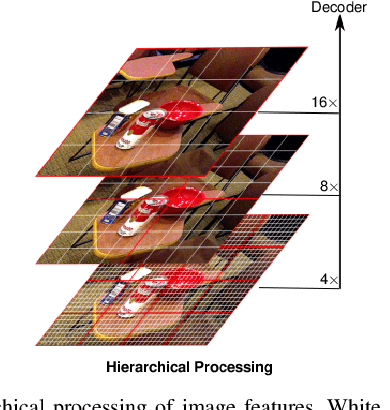
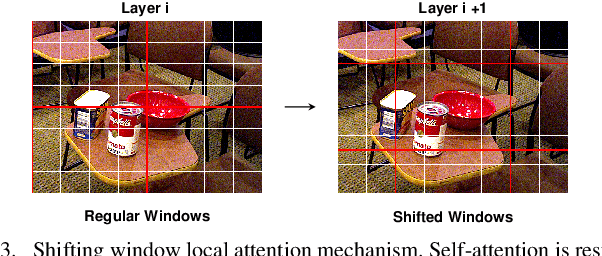
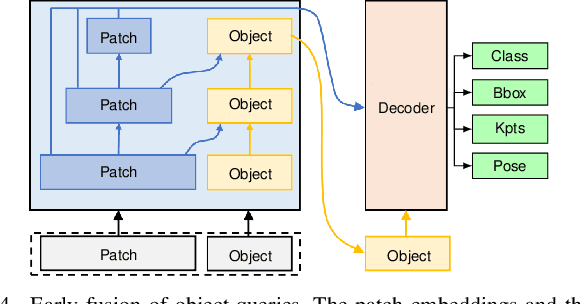
Object pose estimation is a long-standing problem in computer vision. Recently, attention-based vision transformer models have achieved state-of-the-art results in many computer vision applications. Exploiting the permutation-invariant nature of the attention mechanism, a family of vision transformer models formulate multi-object pose estimation as a set prediction problem. However, existing vision transformer models for multi-object pose estimation rely exclusively on the attention mechanism. Convolutional neural networks, on the other hand, hard-wire various inductive biases into their architecture. In this paper, we investigate incorporating inductive biases in vision transformer models for multi-object pose estimation, which facilitates learning long-range dependencies while circumventing the costly global attention. In particular, we use multi-resolution deformable attention, where the attention operation is performed only between a few deformed reference points. Furthermore, we propose a query aggregation mechanism that enables increasing the number of object queries without increasing the computational complexity. We evaluate the proposed model on the challenging YCB-Video dataset and report state-of-the-art results.
YOLOPose V2: Understanding and Improving Transformer-based 6D Pose Estimation
Jul 21, 2023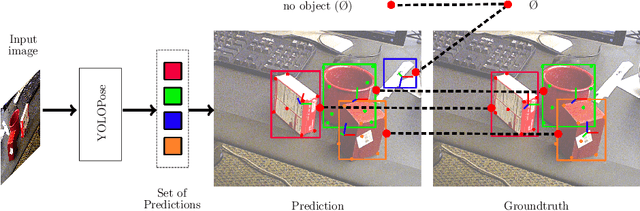
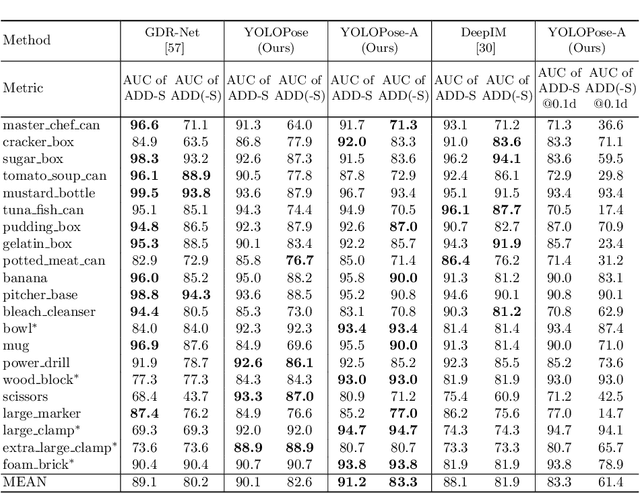
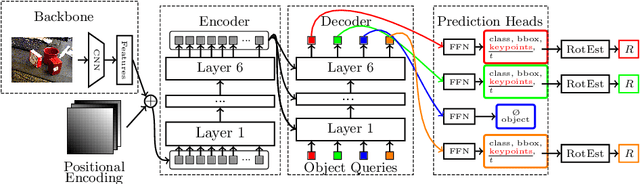
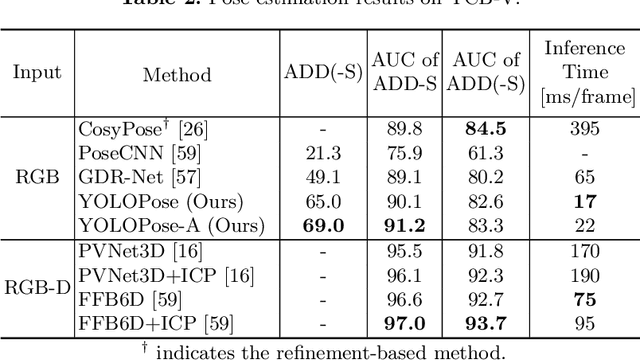
6D object pose estimation is a crucial prerequisite for autonomous robot manipulation applications. The state-of-the-art models for pose estimation are convolutional neural network (CNN)-based. Lately, Transformers, an architecture originally proposed for natural language processing, is achieving state-of-the-art results in many computer vision tasks as well. Equipped with the multi-head self-attention mechanism, Transformers enable simple single-stage end-to-end architectures for learning object detection and 6D object pose estimation jointly. In this work, we propose YOLOPose (short form for You Only Look Once Pose estimation), a Transformer-based multi-object 6D pose estimation method based on keypoint regression and an improved variant of the YOLOPose model. In contrast to the standard heatmaps for predicting keypoints in an image, we directly regress the keypoints. Additionally, we employ a learnable orientation estimation module to predict the orientation from the keypoints. Along with a separate translation estimation module, our model is end-to-end differentiable. Our method is suitable for real-time applications and achieves results comparable to state-of-the-art methods. We analyze the role of object queries in our architecture and reveal that the object queries specialize in detecting objects in specific image regions. Furthermore, we quantify the accuracy trade-off of using datasets of smaller sizes to train our model.
Learning Implicit Probability Distribution Functions for Symmetric Orientation Estimation from RGB Images Without Pose Labels
Nov 21, 2022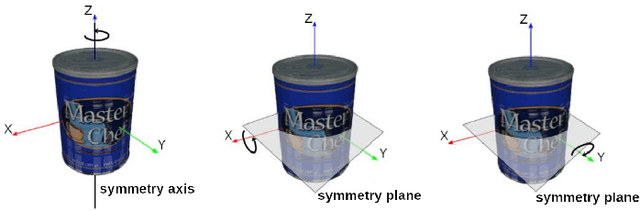
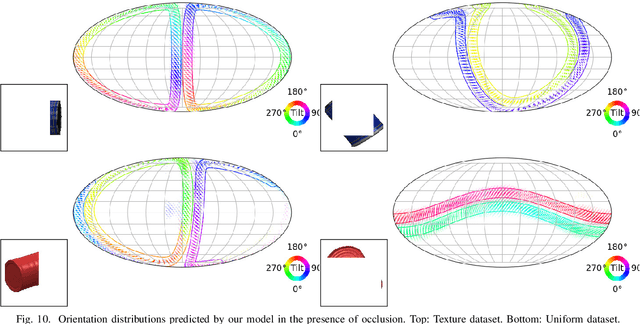
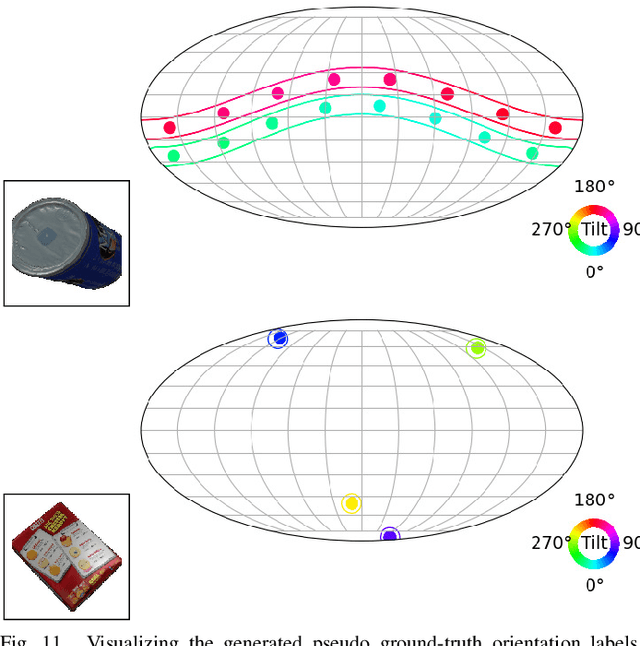

Object pose estimation is a necessary prerequisite for autonomous robotic manipulation, but the presence of symmetry increases the complexity of the pose estimation task. Existing methods for object pose estimation output a single 6D pose. Thus, they lack the ability to reason about symmetries. Lately, modeling object orientation as a non-parametric probability distribution on the SO(3) manifold by neural networks has shown impressive results. However, acquiring large-scale datasets to train pose estimation models remains a bottleneck. To address this limitation, we introduce an automatic pose labeling scheme. Given RGB-D images without object pose annotations and 3D object models, we design a two-stage pipeline consisting of point cloud registration and render-and-compare validation to generate multiple symmetrical pseudo-ground-truth pose labels for each image. Using the generated pose labels, we train an ImplicitPDF model to estimate the likelihood of an orientation hypothesis given an RGB image. An efficient hierarchical sampling of the SO(3) manifold enables tractable generation of the complete set of symmetries at multiple resolutions. During inference, the most likely orientation of the target object is estimated using gradient ascent. We evaluate the proposed automatic pose labeling scheme and the ImplicitPDF model on a photorealistic dataset and the T-Less dataset, demonstrating the advantages of the proposed method.
ConvPoseCNN2: Prediction and Refinement of Dense 6D Object Poses
May 23, 2022Object pose estimation is a key perceptual capability in robotics. We propose a fully-convolutional extension of the PoseCNN method, which densely predicts object translations and orientations. This has several advantages such as improving the spatial resolution of the orientation predictions -- useful in highly-cluttered arrangements, significant reduction in parameters by avoiding full connectivity, and fast inference. We propose and discuss several aggregation methods for dense orientation predictions that can be applied as a post-processing step, such as averaging and clustering techniques. We demonstrate that our method achieves the same accuracy as PoseCNN on the challenging YCB-Video dataset and provide a detailed ablation study of several variants of our method. Finally, we demonstrate that the model can be further improved by inserting an iterative refinement module into the middle of the network, which enforces consistency of the prediction.
YOLOPose: Transformer-based Multi-Object 6D Pose Estimation using Keypoint Regression
May 05, 2022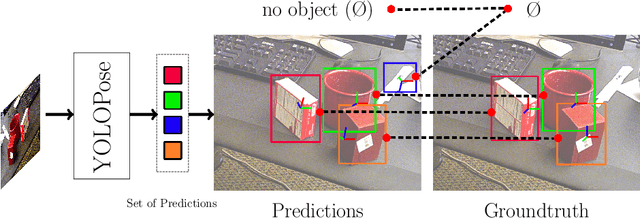
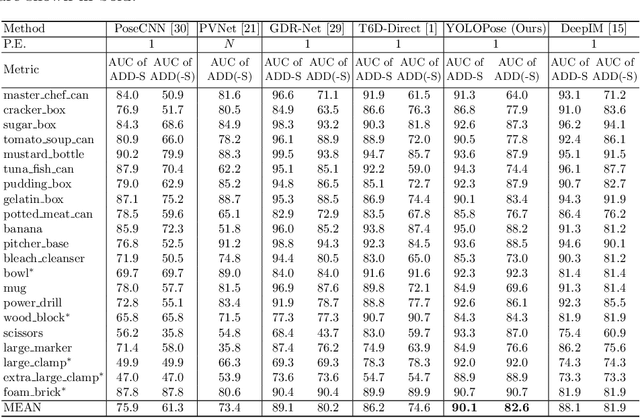
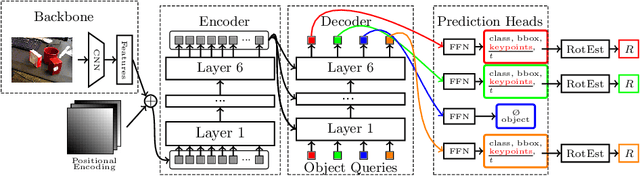
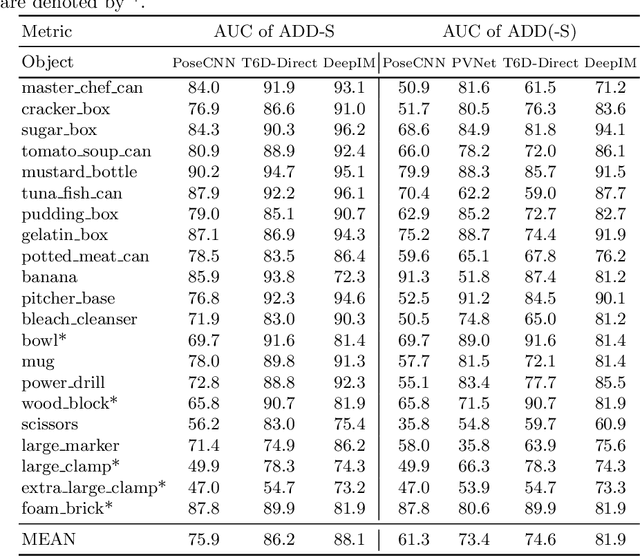
6D object pose estimation is a crucial prerequisite for autonomous robot manipulation applications. The state-of-the-art models for pose estimation are convolutional neural network (CNN)-based. Lately, Transformers, an architecture originally proposed for natural language processing, is achieving state-of-the-art results in many computer vision tasks as well. Equipped with the multi-head self-attention mechanism, Transformers enable simple single-stage end-to-end architectures for learning object detection and 6D object pose estimation jointly. In this work, we propose YOLOPose (short form for You Only Look Once Pose estimation), a Transformer-based multi-object 6D pose estimation method based on keypoint regression. In contrast to the standard heatmaps for predicting keypoints in an image, we directly regress the keypoints. Additionally, we employ a learnable orientation estimation module to predict the orientation from the keypoints. Along with a separate translation estimation module, our model is end-to-end differentiable. Our method is suitable for real-time applications and achieves results comparable to state-of-the-art methods.
T6D-Direct: Transformers for Multi-Object 6D Pose Direct Regression
Sep 22, 2021
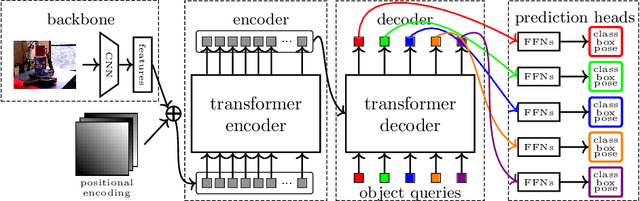
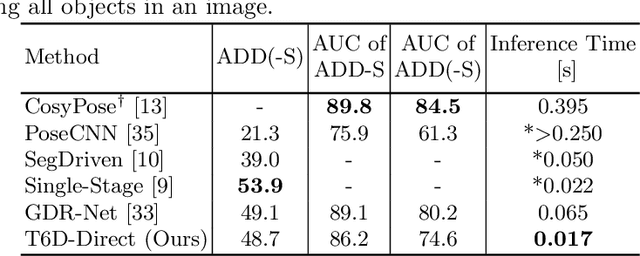
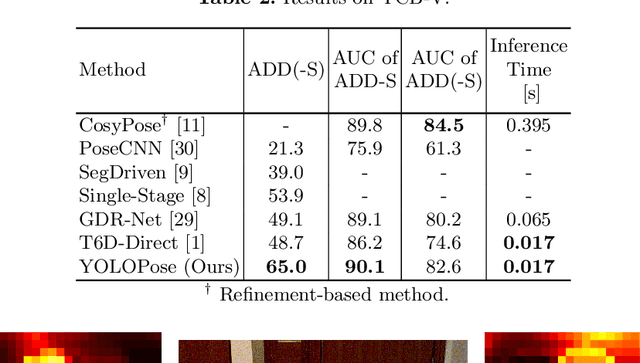
6D pose estimation is the task of predicting the translation and orientation of objects in a given input image, which is a crucial prerequisite for many robotics and augmented reality applications. Lately, the Transformer Network architecture, equipped with a multi-head self-attention mechanism, is emerging to achieve state-of-the-art results in many computer vision tasks. DETR, a Transformer-based model, formulated object detection as a set prediction problem and achieved impressive results without standard components like region of interest pooling, non-maximal suppression, and bounding box proposals. In this work, we propose T6D-Direct, a real-time single-stage direct method with a transformer-based architecture built on DETR to perform 6D multi-object pose direct estimation. We evaluate the performance of our method on the YCB-Video dataset. Our method achieves the fastest inference time, and the pose estimation accuracy is comparable to state-of-the-art methods.
SynPick: A Dataset for Dynamic Bin Picking Scene Understanding
Jul 10, 2021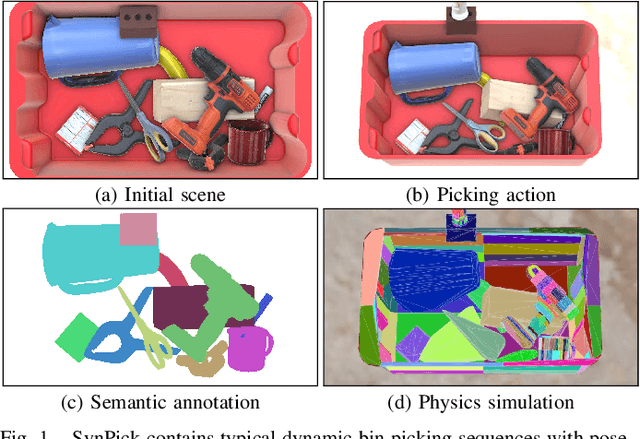



We present SynPick, a synthetic dataset for dynamic scene understanding in bin-picking scenarios. In contrast to existing datasets, our dataset is both situated in a realistic industrial application domain -- inspired by the well-known Amazon Robotics Challenge (ARC) -- and features dynamic scenes with authentic picking actions as chosen by our picking heuristic developed for the ARC 2017. The dataset is compatible with the popular BOP dataset format. We describe the dataset generation process in detail, including object arrangement generation and manipulation simulation using the NVIDIA PhysX physics engine. To cover a large action space, we perform untargeted and targeted picking actions, as well as random moving actions. To establish a baseline for object perception, a state-of-the-art pose estimation approach is evaluated on the dataset. We demonstrate the usefulness of tracking poses during manipulation instead of single-shot estimation even with a naive filtering approach. The generator source code and dataset are publicly available.
Team NimbRo's UGV Solution for Autonomous Wall Building and Fire Fighting at MBZIRC 2020
May 27, 2021
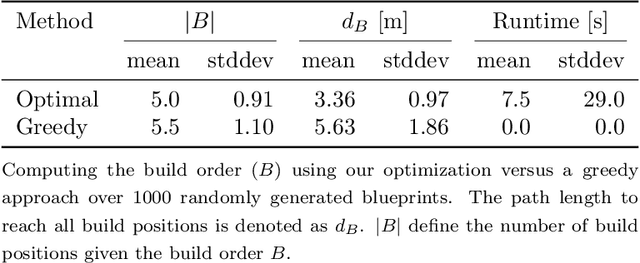

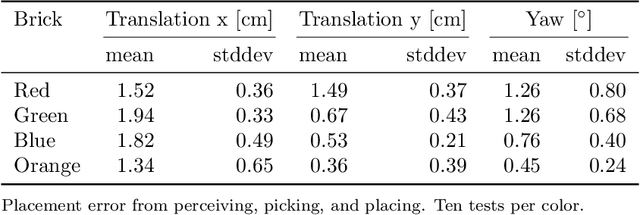
Autonomous robotic systems for various applications including transport, mobile manipulation, and disaster response are becoming more and more complex. Evaluating and analyzing such systems is challenging. Robotic competitions are designed to benchmark complete robotic systems on complex state-of-the-art tasks. Participants compete in defined scenarios under equal conditions. We present our UGV solution developed for the Mohamed Bin Zayed International Robotics Challenge 2020. Our hard- and software components to address the challenge tasks of wall building and fire fighting are integrated into a fully autonomous system. The robot consists of a wheeled omnidirectional base, a 6 DoF manipulator arm equipped with a magnetic gripper, a highly efficient storage system to transport box-shaped objects, and a water spraying system to fight fires. The robot perceives its environment using 3D LiDAR as well as RGB and thermal camera-based perception modules, is capable of picking box-shaped objects and constructing a pre-defined wall structure, as well as detecting and localizing heat sources in order to extinguish potential fires. A high-level planner solves the challenge tasks using the robot skills. We analyze and discuss our successful participation during the MBZIRC 2020 finals, present further experiments, and provide insights to our lessons learned.
Autonomous Wall Building with a UGV-UAV Team at MBZIRC 2020
Nov 03, 2020

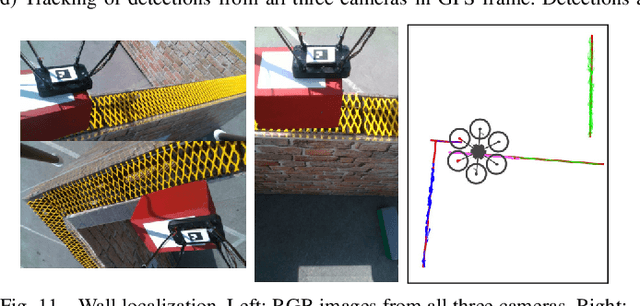
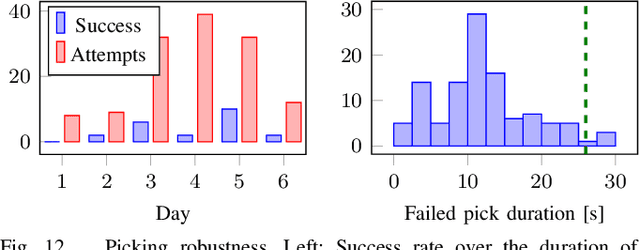
Constructing large structures with robots is a challenging task with many potential applications that requires mobile manipulation capabilities. We present two systems for autonomous wall building that we developed for the Mohamed Bin Zayed International Robotics Challenge 2020. Both systems autonomously perceive their environment, find bricks, and build a predefined wall structure. While the UGV uses a 3D LiDAR-based perception system which measures brick poses with high precision, the UAV employs a real-time camera-based system for visual servoing. We report results and insights from our successful participation at the MBZIRC 2020 Finals, additional lab experiments, and discuss the lessons learned from the competition.