 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient Multi-Object Pose Estimation using Multi-Resolution Deformable Attention and Query Aggregation
Dec 13, 2023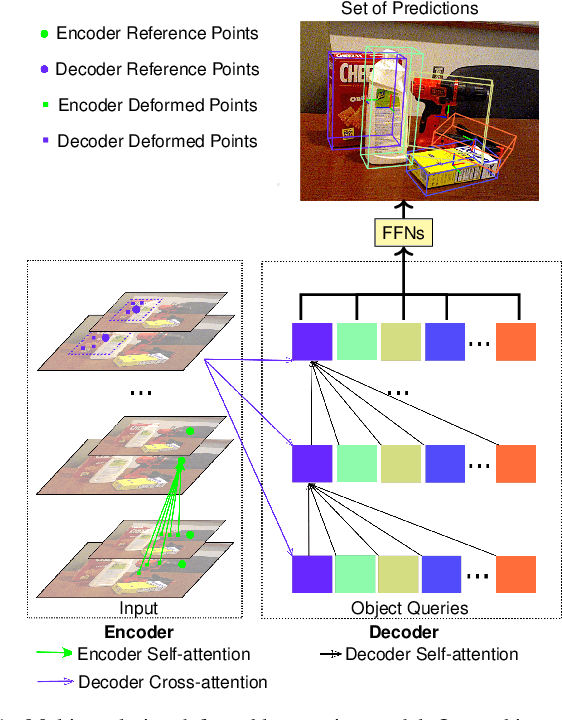
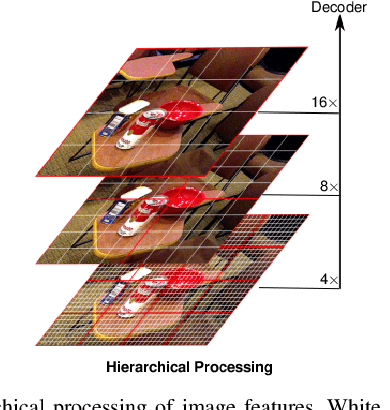
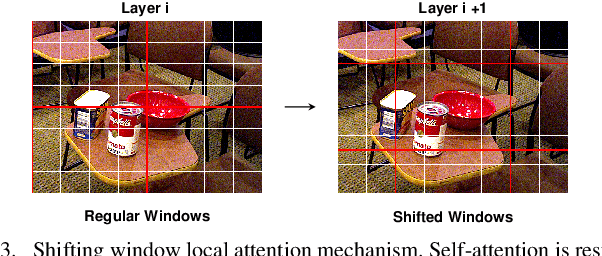
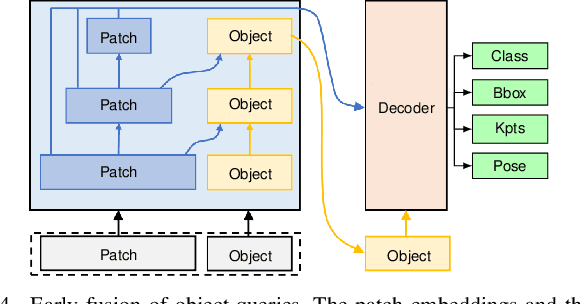
Object pose estimation is a long-standing problem in computer vision. Recently, attention-based vision transformer models have achieved state-of-the-art results in many computer vision applications. Exploiting the permutation-invariant nature of the attention mechanism, a family of vision transformer models formulate multi-object pose estimation as a set prediction problem. However, existing vision transformer models for multi-object pose estimation rely exclusively on the attention mechanism. Convolutional neural networks, on the other hand, hard-wire various inductive biases into their architecture. In this paper, we investigate incorporating inductive biases in vision transformer models for multi-object pose estimation, which facilitates learning long-range dependencies while circumventing the costly global attention. In particular, we use multi-resolution deformable attention, where the attention operation is performed only between a few deformed reference points. Furthermore, we propose a query aggregation mechanism that enables increasing the number of object queries without increasing the computational complexity. We evaluate the proposed model on the challenging YCB-Video dataset and report state-of-the-art results.
YOLOPose V2: Understanding and Improving Transformer-based 6D Pose Estimation
Jul 21, 2023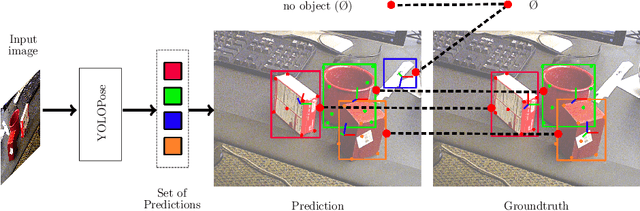
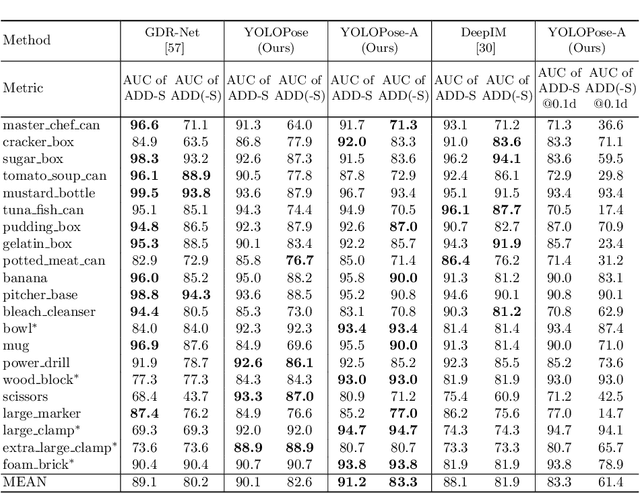
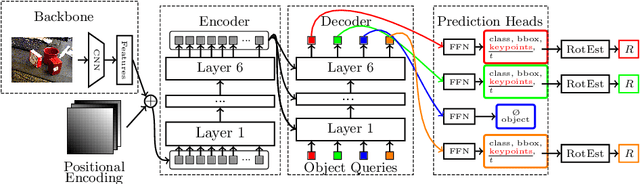
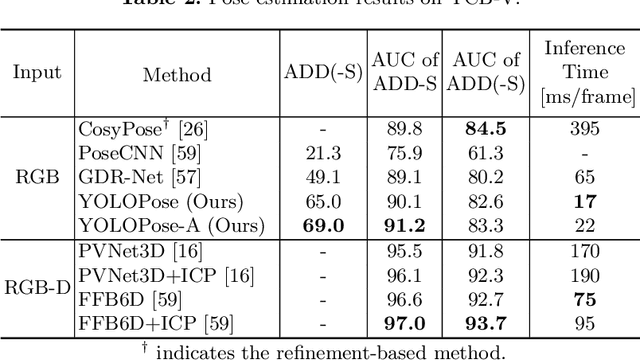
6D object pose estimation is a crucial prerequisite for autonomous robot manipulation applications. The state-of-the-art models for pose estimation are convolutional neural network (CNN)-based. Lately, Transformers, an architecture originally proposed for natural language processing, is achieving state-of-the-art results in many computer vision tasks as well. Equipped with the multi-head self-attention mechanism, Transformers enable simple single-stage end-to-end architectures for learning object detection and 6D object pose estimation jointly. In this work, we propose YOLOPose (short form for You Only Look Once Pose estimation), a Transformer-based multi-object 6D pose estimation method based on keypoint regression and an improved variant of the YOLOPose model. In contrast to the standard heatmaps for predicting keypoints in an image, we directly regress the keypoints. Additionally, we employ a learnable orientation estimation module to predict the orientation from the keypoints. Along with a separate translation estimation module, our model is end-to-end differentiable. Our method is suitable for real-time applications and achieves results comparable to state-of-the-art methods. We analyze the role of object queries in our architecture and reveal that the object queries specialize in detecting objects in specific image regions. Furthermore, we quantify the accuracy trade-off of using datasets of smaller sizes to train our model.