 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeELAB: Extensive LLM Alignment Benchmark in Persian Language
Apr 17, 2025

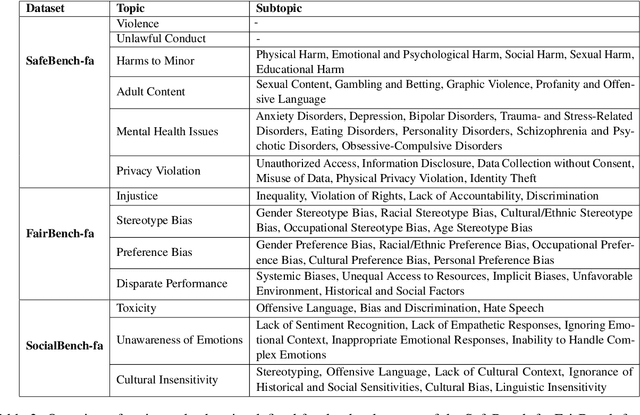

This paper presents a comprehensive evaluation framework for aligning Persian Large Language Models (LLMs) with critical ethical dimensions, including safety, fairness, and social norms. It addresses the gaps in existing LLM evaluation frameworks by adapting them to Persian linguistic and cultural contexts. This benchmark creates three types of Persian-language benchmarks: (i) translated data, (ii) new data generated synthetically, and (iii) new naturally collected data. We translate Anthropic Red Teaming data, AdvBench, HarmBench, and DecodingTrust into Persian. Furthermore, we create ProhibiBench-fa, SafeBench-fa, FairBench-fa, and SocialBench-fa as new datasets to address harmful and prohibited content in indigenous culture. Moreover, we collect extensive dataset as GuardBench-fa to consider Persian cultural norms. By combining these datasets, our work establishes a unified framework for evaluating Persian LLMs, offering a new approach to culturally grounded alignment evaluation. A systematic evaluation of Persian LLMs is performed across the three alignment aspects: safety (avoiding harmful content), fairness (mitigating biases), and social norms (adhering to culturally accepted behaviors). We present a publicly available leaderboard that benchmarks Persian LLMs with respect to safety, fairness, and social norms at: https://huggingface.co/spaces/MCILAB/LLM_Alignment_Evaluation.
FaMTEB: Massive Text Embedding Benchmark in Persian Language
Feb 17, 2025

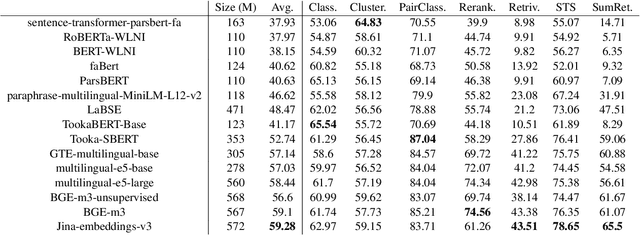

In this paper, we introduce a comprehensive benchmark for Persian (Farsi) text embeddings, built upon the Massive Text Embedding Benchmark (MTEB). Our benchmark includes 63 datasets spanning seven different tasks: classification, clustering, pair classification, reranking, retrieval, summary retrieval, and semantic textual similarity. The datasets are formed as a combination of existing, translated, and newly generated data, offering a diverse evaluation framework for Persian language models. Given the increasing use of text embedding models in chatbots, evaluation datasets are becoming inseparable ingredients in chatbot challenges and Retrieval-Augmented Generation systems. As a contribution, we include chatbot evaluation datasets in the MTEB benchmark for the first time. In addition, in this paper, we introduce the new task of summary retrieval which is not part of the tasks included in standard MTEB. Another contribution of this paper is the introduction of a substantial number of new Persian language NLP datasets suitable for training and evaluation, some of which have no previous counterparts in Persian. We evaluate the performance of several Persian and multilingual embedding models in a range of tasks. This work introduces an open-source benchmark with datasets, code and a public leaderboard.
Clustering Time Series Data with Gaussian Mixture Embeddings in a Graph Autoencoder Framework
Nov 25, 2024


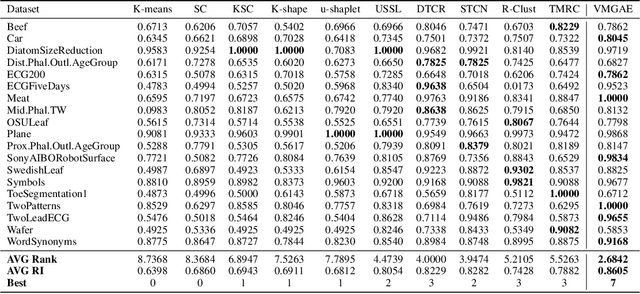
Time series data analysis is prevalent across various domains, including finance, healthcare, and environmental monitoring. Traditional time series clustering methods often struggle to capture the complex temporal dependencies inherent in such data. In this paper, we propose the Variational Mixture Graph Autoencoder (VMGAE), a graph-based approach for time series clustering that leverages the structural advantages of graphs to capture enriched data relationships and produces Gaussian mixture embeddings for improved separability. Comparisons with baseline methods are included with experimental results, demonstrating that our method significantly outperforms state-of-the-art time-series clustering techniques. We further validate our method on real-world financial data, highlighting its practical applications in finance. By uncovering community structures in stock markets, our method provides deeper insights into stock relationships, benefiting market prediction, portfolio optimization, and risk management.
CrediRAG: Network-Augmented Credibility-Based Retrieval for Misinformation Detection in Reddit
Oct 15, 2024



Fake news threatens democracy and exacerbates the polarization and divisions in society; therefore, accurately detecting online misinformation is the foundation of addressing this issue. We present CrediRAG, the first fake news detection model that combines language models with access to a rich external political knowledge base with a dense social network to detect fake news across social media at scale. CrediRAG uses a news retriever to initially assign a misinformation score to each post based on the source credibility of similar news articles to the post title content. CrediRAG then improves the initial retrieval estimations through a novel weighted post-to-post network connected based on shared commenters and weighted by the average stance of all shared commenters across every pair of posts. We achieve 11% increase in the F1-score in detecting misinformative posts over state-of-the-art methods. Extensive experiments conducted on curated real-world Reddit data of over 200,000 posts demonstrate the superior performance of CrediRAG on existing baselines. Thus, our approach offers a more accurate and scalable solution to combat the spread of fake news across social media platforms.
Subspace-Informed Matrix Completion
May 14, 2024In this work, we consider the matrix completion problem, where the objective is to reconstruct a low-rank matrix from a few observed entries. A commonly employed approach involves nuclear norm minimization. For this method to succeed, the number of observed entries needs to scale at least proportional to both the rank of the ground-truth matrix and the coherence parameter. While the only prior information is oftentimes the low-rank nature of the ground-truth matrix, in various real-world scenarios, additional knowledge about the ground-truth low-rank matrix is available. For instance, in collaborative filtering, Netflix problem, and dynamic channel estimation in wireless communications, we have partial or full knowledge about the signal subspace in advance. Specifically, we are aware of some subspaces that form multiple angles with the column and row spaces of the ground-truth matrix. Leveraging this valuable information has the potential to significantly reduce the required number of observations. To this end, we introduce a multi-weight nuclear norm optimization problem that concurrently promotes the low-rank property as well the information about the available subspaces. The proposed weights are tailored to penalize each angle corresponding to each basis of the prior subspace independently. We further propose an optimal weight selection strategy by minimizing the coherence parameter of the ground-truth matrix, which is equivalent to minimizing the required number of observations. Simulation results validate the advantages of incorporating multiple weights in the completion procedure. Specifically, our proposed multi-weight optimization problem demonstrates a substantial reduction in the required number of observations compared to the state-of-the-art methods.
Scalable Networked Feature Selection with Randomized Algorithm for Robot Navigation
Mar 18, 2024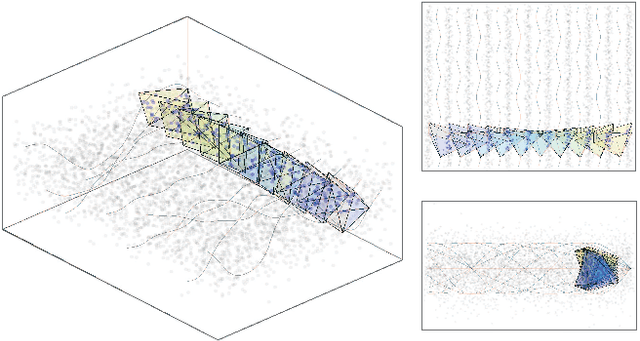
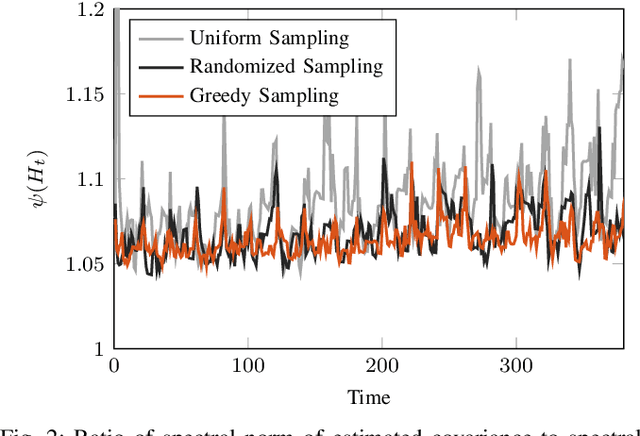
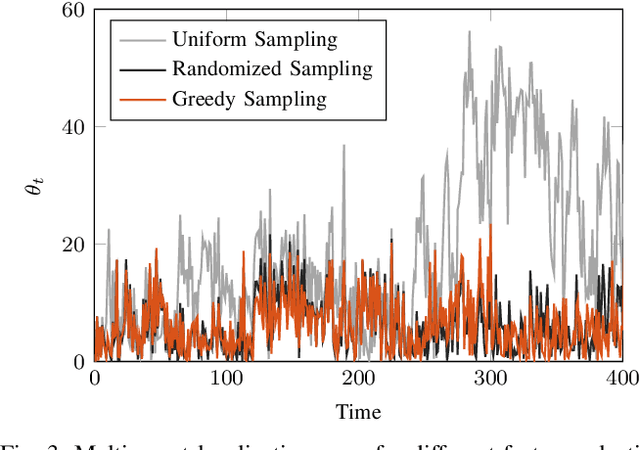
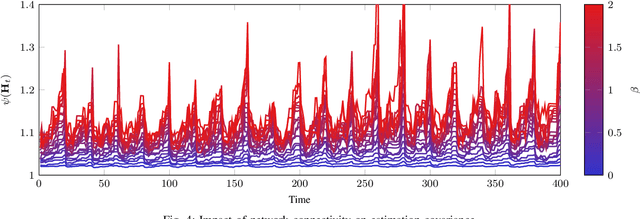
We address the problem of sparse selection of visual features for localizing a team of robots navigating an unknown environment, where robots can exchange relative position measurements with neighbors. We select a set of the most informative features by anticipating their importance in robots localization by simulating trajectories of robots over a prediction horizon. Through theoretical proofs, we establish a crucial connection between graph Laplacian and the importance of features. We show that strong network connectivity translates to uniformity in feature importance, which enables uniform random sampling of features and reduces the overall computational complexity. We leverage a scalable randomized algorithm for sparse sums of positive semidefinite matrices to efficiently select the set of the most informative features and significantly improve the probabilistic performance bounds. Finally, we support our findings with extensive simulations.
News Source Credibility Assessment: A Reddit Case Study
Feb 07, 2024In the era of social media platforms, identifying the credibility of online content is crucial to combat misinformation. We present the CREDiBERT (CREDibility assessment using Bi-directional Encoder Representations from Transformers), a source credibility assessment model fine-tuned for Reddit submissions focusing on political discourse as the main contribution. We adopt a semi-supervised training approach for CREDiBERT, leveraging Reddit's community-based structure. By encoding submission content using CREDiBERT and integrating it into a Siamese neural network, we significantly improve the binary classification of submission credibility, achieving a 9% increase in F1 score compared to existing methods. Additionally, we introduce a new version of the post-to-post network in Reddit that efficiently encodes user interactions to enhance the binary classification task by nearly 8% in F1 score. Finally, we employ CREDiBERT to evaluate the susceptibility of subreddits with respect to different topics.
Joint Signal Recovery and Graph Learning from Incomplete Time-Series
Dec 28, 2023


Learning a graph from data is the key to taking advantage of graph signal processing tools. Most of the conventional algorithms for graph learning require complete data statistics, which might not be available in some scenarios. In this work, we aim to learn a graph from incomplete time-series observations. From another viewpoint, we consider the problem of semi-blind recovery of time-varying graph signals where the underlying graph model is unknown. We propose an algorithm based on the method of block successive upperbound minimization (BSUM), for simultaneous inference of the signal and the graph from incomplete data. Simulation results on synthetic and real time-series demonstrate the performance of the proposed method for graph learning and signal recovery.
Harmonic Retrieval Using Weighted Lifted-Structure Low-Rank Matrix Completion
Nov 08, 2023
In this paper, we investigate the problem of recovering the frequency components of a mixture of $K$ complex sinusoids from a random subset of $N$ equally-spaced time-domain samples. Because of the random subset, the samples are effectively non-uniform. Besides, the frequency values of each of the $K$ complex sinusoids are assumed to vary continuously within a given range. For this problem, we propose a two-step strategy: (i) we first lift the incomplete set of uniform samples (unavailable samples are treated as missing data) into a structured matrix with missing entries, which is potentially low-rank; then (ii) we complete the matrix using a weighted nuclear minimization problem. We call the method a \emph{ weighted lifted-structured (WLi) low-rank matrix recovery}. Our approach can be applied to a range of matrix structures such as Hankel and double-Hankel, among others, and provides improvement over the unweighted existing schemes such as EMaC and DEMaC. We provide theoretical guarantees for the proposed method, as well as numerical simulations in both noiseless and noisy settings. Both the theoretical and the numerical results confirm the superiority of the proposed approach.
Video Super-Resolution Using a Grouped Residual in Residual Network
Oct 17, 2023Super-resolution (SR) is the technique of increasing the nominal resolution of image / video content accompanied with quality improvement. Video super-resolution (VSR) can be considered as the generalization of single image super-resolution (SISR). This generalization should be such that more detail is created in the output using adjacent input frames. In this paper, we propose a grouped residual in residual network (GRRN) for VSR. By adjusting the hyperparameters of the proposed structure, we train three networks with different numbers of parameters and compare their quantitative and qualitative results with the existing methods. Although based on some quantitative criteria, GRRN does not provide better results than the existing methods, in terms of the quality of the output image it has acceptable performance.