 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHakim: Farsi Text Embedding Model
May 14, 2025Recent advancements in text embedding have significantly improved natural language understanding across many languages, yet Persian remains notably underrepresented in large-scale embedding research. In this paper, we present Hakim, a novel state-of-the-art Persian text embedding model that achieves a 8.5% performance improvement over existing approaches on the FaMTEB benchmark, outperforming all previously developed Persian language models. As part of this work, we introduce three new datasets - Corpesia, Pairsia-sup, and Pairsia-unsup - to support supervised and unsupervised training scenarios. Additionally, Hakim is designed for applications in chatbots and retrieval-augmented generation (RAG) systems, particularly addressing retrieval tasks that require incorporating message history within these systems. We also propose a new baseline model built on the BERT architecture. Our language model consistently achieves higher accuracy across various Persian NLP tasks, while the RetroMAE-based model proves particularly effective for textual information retrieval applications. Together, these contributions establish a new foundation for advancing Persian language understanding.
ELAB: Extensive LLM Alignment Benchmark in Persian Language
Apr 17, 2025

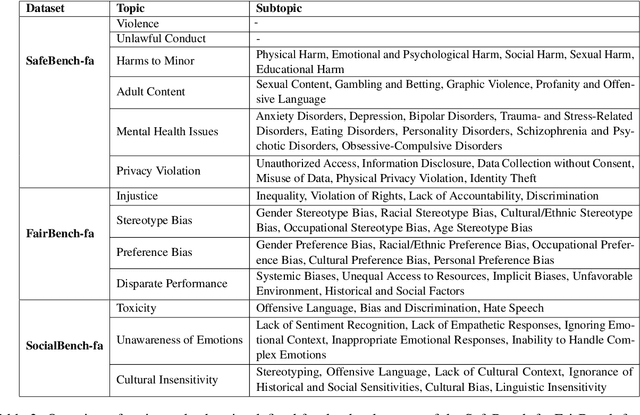

This paper presents a comprehensive evaluation framework for aligning Persian Large Language Models (LLMs) with critical ethical dimensions, including safety, fairness, and social norms. It addresses the gaps in existing LLM evaluation frameworks by adapting them to Persian linguistic and cultural contexts. This benchmark creates three types of Persian-language benchmarks: (i) translated data, (ii) new data generated synthetically, and (iii) new naturally collected data. We translate Anthropic Red Teaming data, AdvBench, HarmBench, and DecodingTrust into Persian. Furthermore, we create ProhibiBench-fa, SafeBench-fa, FairBench-fa, and SocialBench-fa as new datasets to address harmful and prohibited content in indigenous culture. Moreover, we collect extensive dataset as GuardBench-fa to consider Persian cultural norms. By combining these datasets, our work establishes a unified framework for evaluating Persian LLMs, offering a new approach to culturally grounded alignment evaluation. A systematic evaluation of Persian LLMs is performed across the three alignment aspects: safety (avoiding harmful content), fairness (mitigating biases), and social norms (adhering to culturally accepted behaviors). We present a publicly available leaderboard that benchmarks Persian LLMs with respect to safety, fairness, and social norms at: https://huggingface.co/spaces/MCILAB/LLM_Alignment_Evaluation.
FaMTEB: Massive Text Embedding Benchmark in Persian Language
Feb 17, 2025

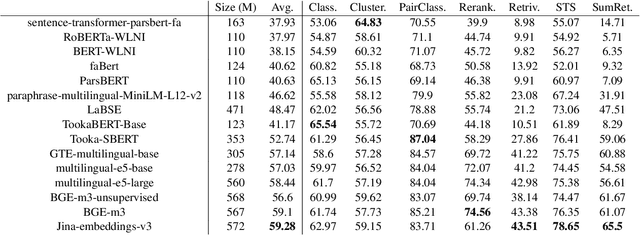

In this paper, we introduce a comprehensive benchmark for Persian (Farsi) text embeddings, built upon the Massive Text Embedding Benchmark (MTEB). Our benchmark includes 63 datasets spanning seven different tasks: classification, clustering, pair classification, reranking, retrieval, summary retrieval, and semantic textual similarity. The datasets are formed as a combination of existing, translated, and newly generated data, offering a diverse evaluation framework for Persian language models. Given the increasing use of text embedding models in chatbots, evaluation datasets are becoming inseparable ingredients in chatbot challenges and Retrieval-Augmented Generation systems. As a contribution, we include chatbot evaluation datasets in the MTEB benchmark for the first time. In addition, in this paper, we introduce the new task of summary retrieval which is not part of the tasks included in standard MTEB. Another contribution of this paper is the introduction of a substantial number of new Persian language NLP datasets suitable for training and evaluation, some of which have no previous counterparts in Persian. We evaluate the performance of several Persian and multilingual embedding models in a range of tasks. This work introduces an open-source benchmark with datasets, code and a public leaderboard.
OPSD: an Offensive Persian Social media Dataset and its baseline evaluations
Apr 08, 2024



The proliferation of hate speech and offensive comments on social media has become increasingly prevalent due to user activities. Such comments can have detrimental effects on individuals' psychological well-being and social behavior. While numerous datasets in the English language exist in this domain, few equivalent resources are available for Persian language. To address this gap, this paper introduces two offensive datasets. The first dataset comprises annotations provided by domain experts, while the second consists of a large collection of unlabeled data obtained through web crawling for unsupervised learning purposes. To ensure the quality of the former dataset, a meticulous three-stage labeling process was conducted, and kappa measures were computed to assess inter-annotator agreement. Furthermore, experiments were performed on the dataset using state-of-the-art language models, both with and without employing masked language modeling techniques, as well as machine learning algorithms, in order to establish the baselines for the dataset using contemporary cutting-edge approaches. The obtained F1-scores for the three-class and two-class versions of the dataset were 76.9% and 89.9% for XLM-RoBERTa, respectively.
Reducing the Computational Cost in Multi-objective Evolutionary Algorithms by Filtering Worthless Individuals
Jan 02, 2014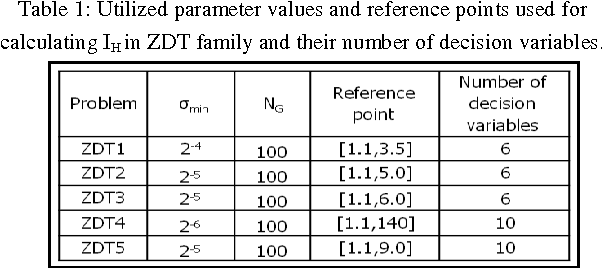
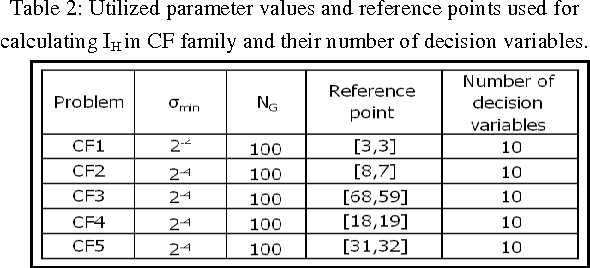
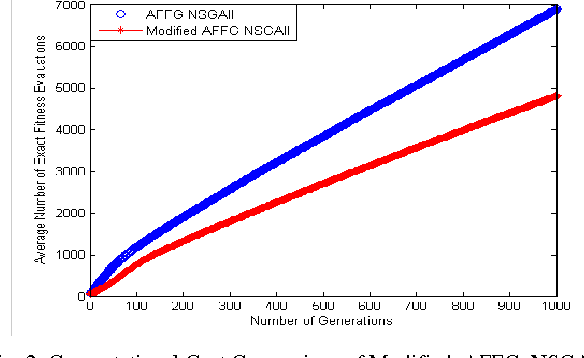
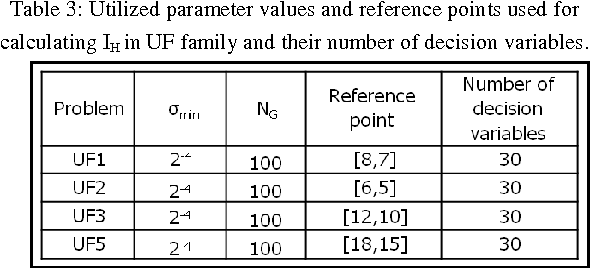
The large number of exact fitness function evaluations makes evolutionary algorithms to have computational cost. In some real-world problems, reducing number of these evaluations is much more valuable even by increasing computational complexity and spending more time. To fulfill this target, we introduce an effective factor, in spite of applied factor in Adaptive Fuzzy Fitness Granulation with Non-dominated Sorting Genetic Algorithm-II, to filter out worthless individuals more precisely. Our proposed approach is compared with respect to Adaptive Fuzzy Fitness Granulation with Non-dominated Sorting Genetic Algorithm-II, using the Hyper volume and the Inverted Generational Distance performance measures. The proposed method is applied to 1 traditional and 1 state-of-the-art benchmarks with considering 3 different dimensions. From an average performance view, the results indicate that although decreasing the number of fitness evaluations leads to have performance reduction but it is not tangible compared to what we gain.