 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLBCIM: Loyalty Based Competitive Influence Maximization with epsilon-greedy MCTS strategy
Mar 03, 2023Competitive influence maximization has been studied for several years, and various frameworks have been proposed to model different aspects of information diffusion under the competitive environment. This work presents a new gameboard for two competing parties with some new features representing loyalty in social networks and reflecting the attitude of not completely being loyal to a party when the opponent offers better suggestions. This behavior can be observed in most political occasions where each party tries to attract people by making better suggestions than the opponent and even seeks to impress the fans of the opposition party to change their minds. In order to identify the best move in each step of the game framework, an improved Monte Carlo tree search is developed, which uses some predefined heuristics to apply them on the simulation step of the algorithm and takes advantage of them to search among child nodes of the current state and pick the best one using an epsilon-greedy way instead of choosing them at random. Experimental results on synthetic and real datasets indicate the outperforming of the proposed strategy against some well-known and benchmark strategies like general MCTS, minimax algorithm with alpha-beta pruning, random nodes, nodes with maximum threshold and nodes with minimum threshold.
Screening COVID-19 Based on CT/CXR Images & Building a Publicly Available CT-scan Dataset of COVID-19
Dec 29, 2020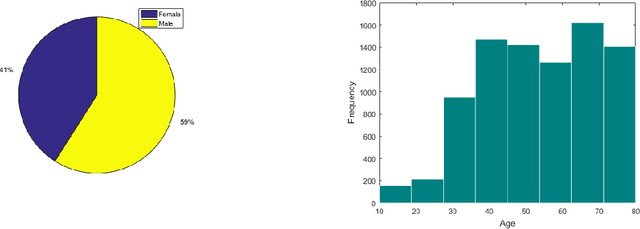
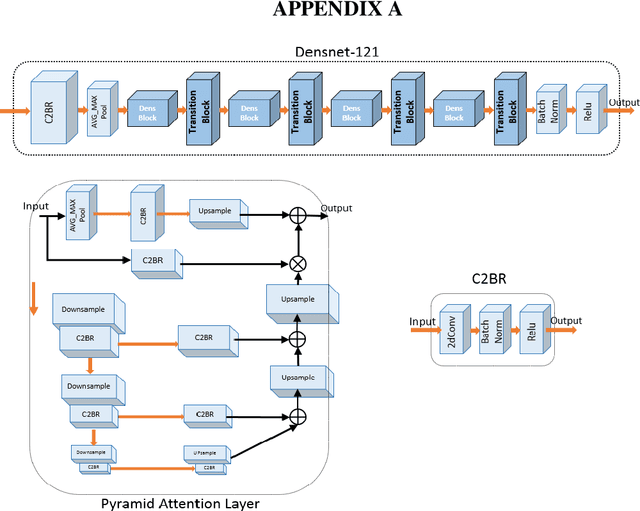
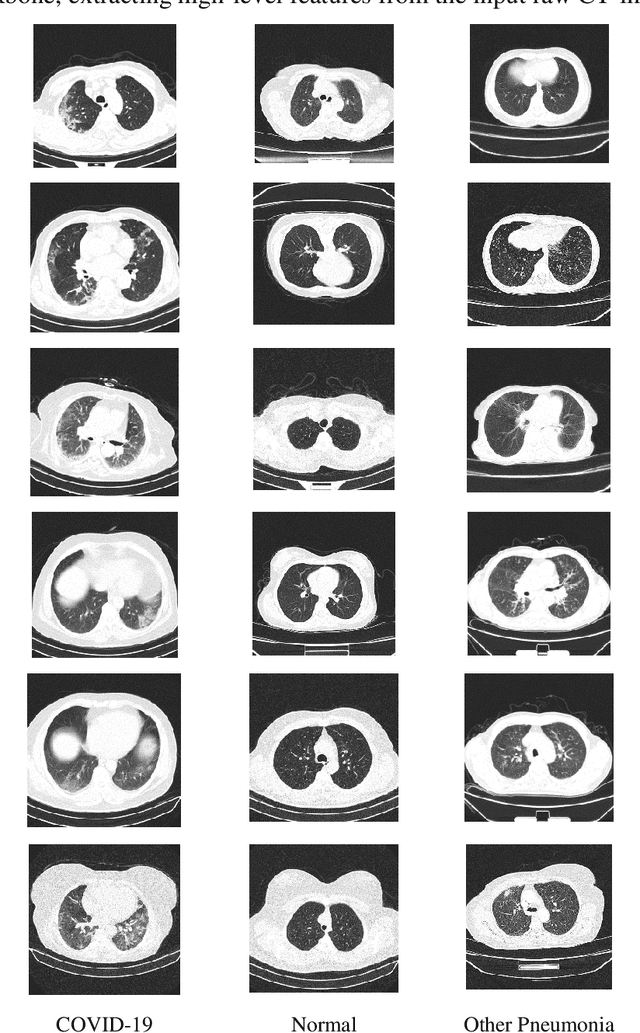
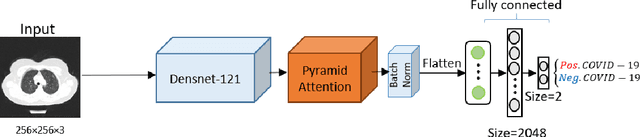
The rapid outbreak of COVID-19 threatens humans life all around the world. Due to insufficient diagnostic infrastructures, developing an accurate, efficient, inexpensive, and quick diagnostic tool is of great importance. As chest radiography, such as chest X-ray (CXR) and CT computed tomography (CT), is a possible way for screening COVID-19, developing an automatic image classification tool is immensely helpful for detecting the patients with COVID-19. To date, researchers have proposed several different screening methods; however, none of them could achieve a reliable and highly sensitive performance yet. The main drawbacks of current methods are the lack of having enough training data, low generalization performance, and a high rate of false-positive detection. To tackle such limitations, this study firstly builds a large-size publicly available CT-scan dataset, consisting of more than 13k CT-images of more than 1000 individuals, in which 8k images are taken from 500 patients infected with COVID-19. Secondly, we propose a deep learning model for screening COVID-19 using our proposed CT dataset and report the baseline results. Finally, we extend the proposed CT model for screening COVID-19 from CXR images using a transfer learning approach. The experimental results show that the proposed CT and CXR methods achieve the AUC scores of 0.886 and 0.984 respectively.
DL-Reg: A Deep Learning Regularization Technique using Linear Regression
Nov 03, 2020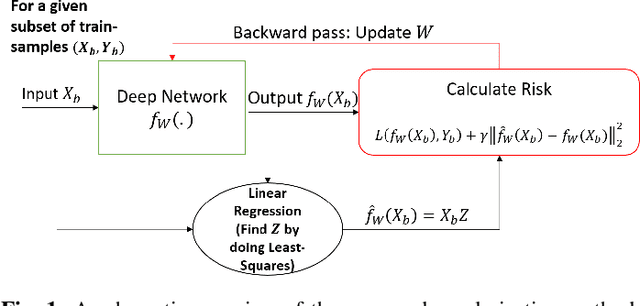
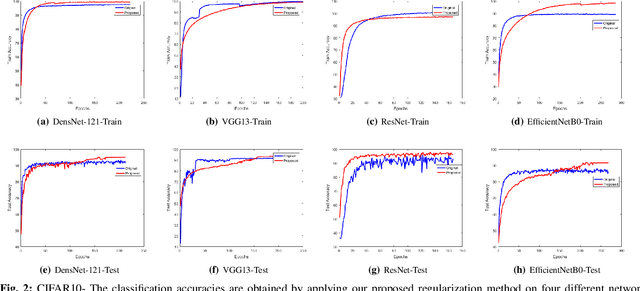
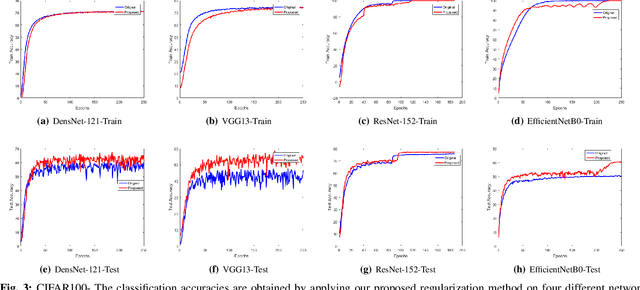
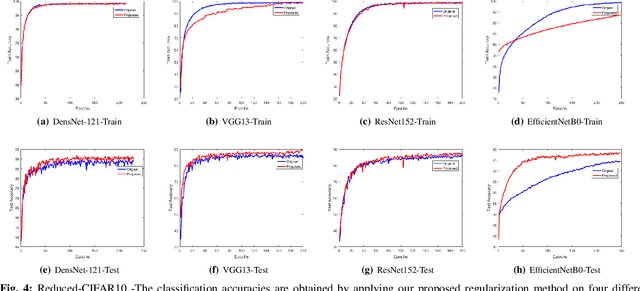
Regularization plays a vital role in the context of deep learning by preventing deep neural networks from the danger of overfitting. This paper proposes a novel deep learning regularization method named as DL-Reg, which carefully reduces the nonlinearity of deep networks to a certain extent by explicitly enforcing the network to behave as much linear as possible. The key idea is to add a linear constraint to the objective function of the deep neural networks, which is simply the error of a linear mapping from the inputs to the outputs of the model. More precisely, the proposed DL-Reg carefully forces the network to behave in a linear manner. This linear constraint, which is further adjusted by a regularization factor, prevents the network from the risk of overfitting. The performance of DL-Reg is evaluated by training state-of-the-art deep network models on several benchmark datasets. The experimental results show that the proposed regularization method: 1) gives major improvements over the existing regularization techniques, and 2) significantly improves the performance of deep neural networks, especially in the case of small-sized training datasets.
Knowledge Representation in Learning Classifier Systems: A Review
Jun 12, 2015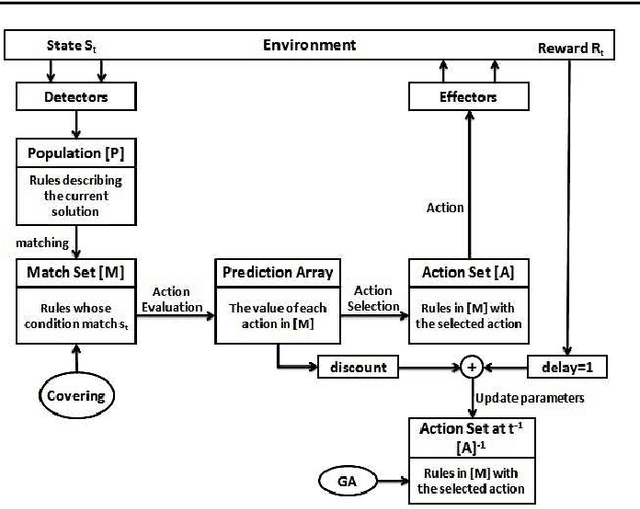
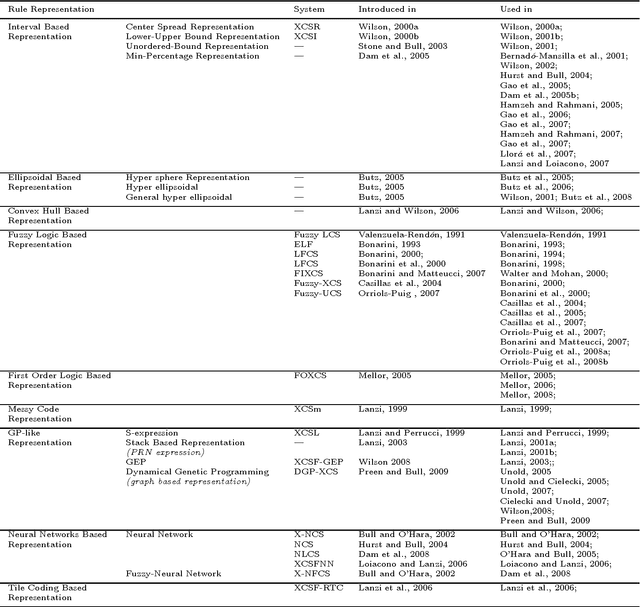
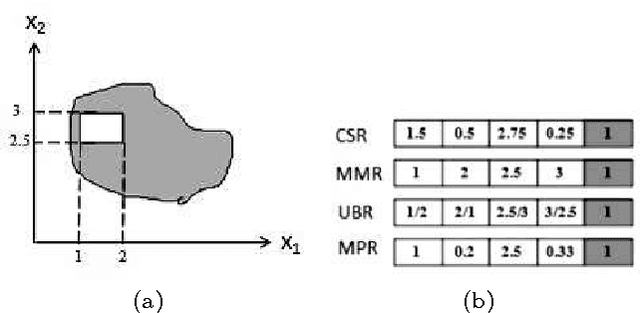
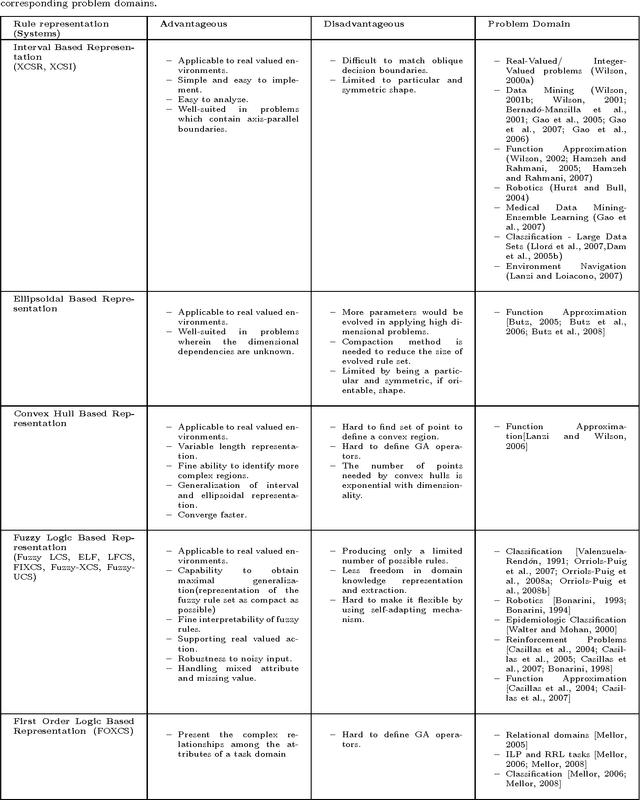
Knowledge representation is a key component to the success of all rule based systems including learning classifier systems (LCSs). This component brings insight into how to partition the problem space what in turn seeks prominent role in generalization capacity of the system as a whole. Recently, knowledge representation component has received great deal of attention within data mining communities due to its impacts on rule based systems in terms of efficiency and efficacy. The current work is an attempt to find a comprehensive and yet elaborate view into the existing knowledge representation techniques in LCS domain in general and XCS in specific. To achieve the objectives, knowledge representation techniques are grouped into different categories based on the classification approach in which they are incorporated. In each category, the underlying rule representation schema and the format of classifier condition to support the corresponding representation are presented. Furthermore, a precise explanation on the way that each technique partitions the problem space along with the extensive experimental results is provided. To have an elaborated view on the functionality of each technique, a comparative analysis of existing techniques on some conventional problems is provided. We expect this survey to be of interest to the LCS researchers and practitioners since it provides a guideline for choosing a proper knowledge representation technique for a given problem and also opens up new streams of research on this topic.
Reducing the Computational Cost in Multi-objective Evolutionary Algorithms by Filtering Worthless Individuals
Jan 02, 2014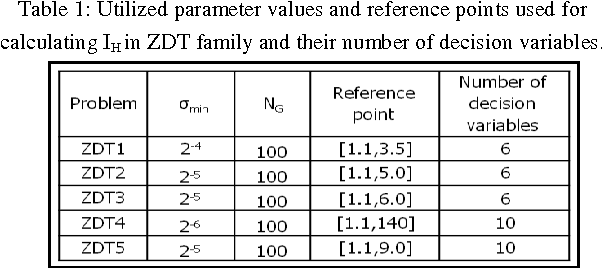
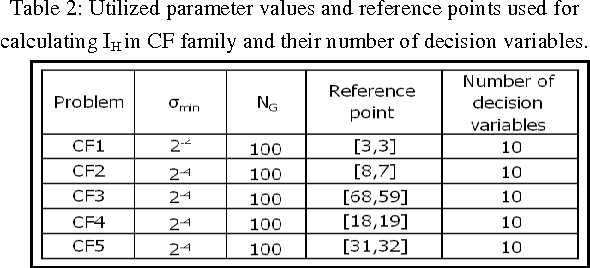
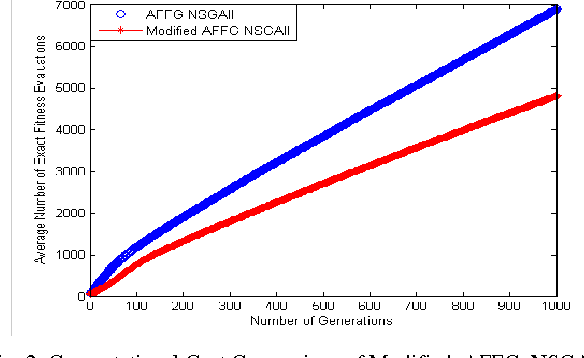
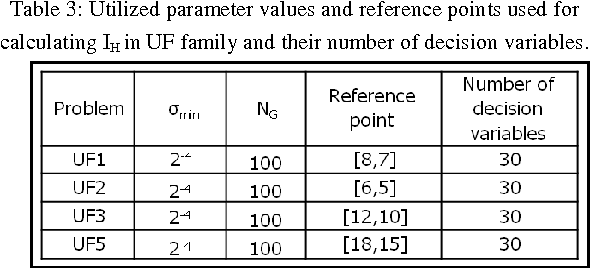
The large number of exact fitness function evaluations makes evolutionary algorithms to have computational cost. In some real-world problems, reducing number of these evaluations is much more valuable even by increasing computational complexity and spending more time. To fulfill this target, we introduce an effective factor, in spite of applied factor in Adaptive Fuzzy Fitness Granulation with Non-dominated Sorting Genetic Algorithm-II, to filter out worthless individuals more precisely. Our proposed approach is compared with respect to Adaptive Fuzzy Fitness Granulation with Non-dominated Sorting Genetic Algorithm-II, using the Hyper volume and the Inverted Generational Distance performance measures. The proposed method is applied to 1 traditional and 1 state-of-the-art benchmarks with considering 3 different dimensions. From an average performance view, the results indicate that although decreasing the number of fitness evaluations leads to have performance reduction but it is not tangible compared to what we gain.
A Novel Strategy Selection Method for Multi-Objective Clustering Algorithms Using Game Theory
Aug 15, 2012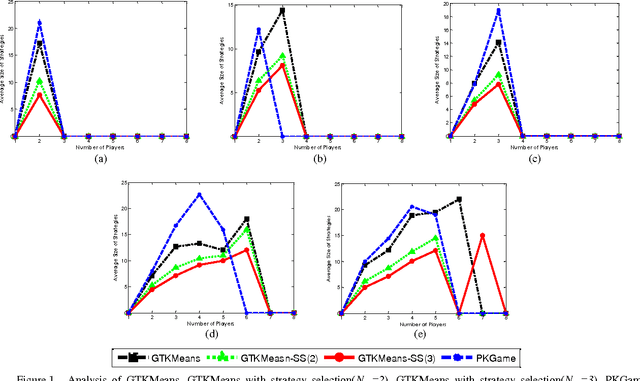

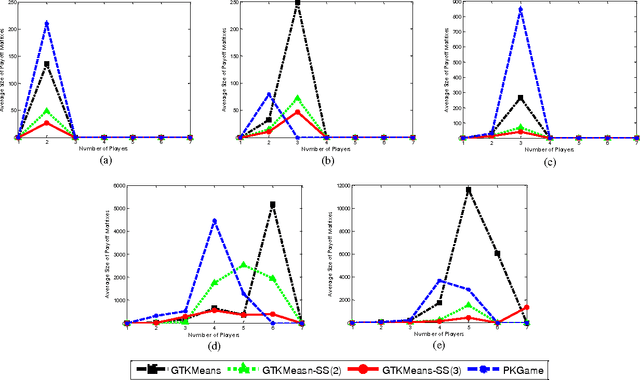
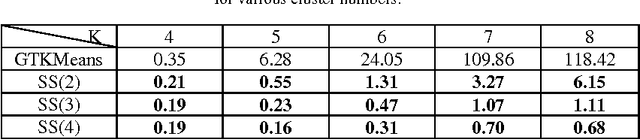
The most important factors which contribute to the efficiency of game-theoretical algorithms are time and game complexity. In this study, we have offered an elegant method to deal with high complexity of game theoretic multi-objective clustering methods in large-sized data sets. Here, we have developed a method which selects a subset of strategies from strategies profile for each player. In this case, the size of payoff matrices reduces significantly which has a remarkable impact on time complexity. Therefore, practical problems with more data are tractable with less computational complexity. Although strategies set may grow with increasing the number of data points, the presented model of strategy selection reduces the strategy space, considerably, where clusters are subdivided into several sub-clusters in each local game. The remarkable results demonstrate the efficiency of the presented approach in reducing computational complexity of the problem of concern.