 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBlood lactate concentration prediction in critical care patients: handling missing values
Oct 03, 2019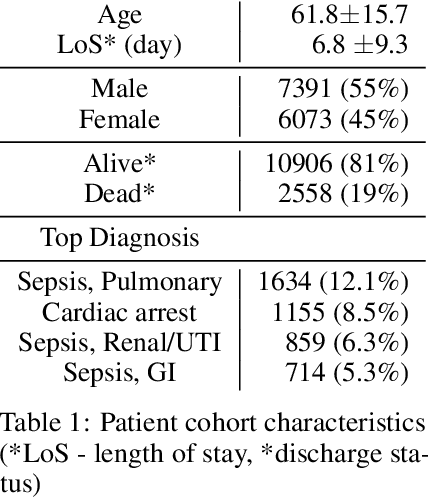
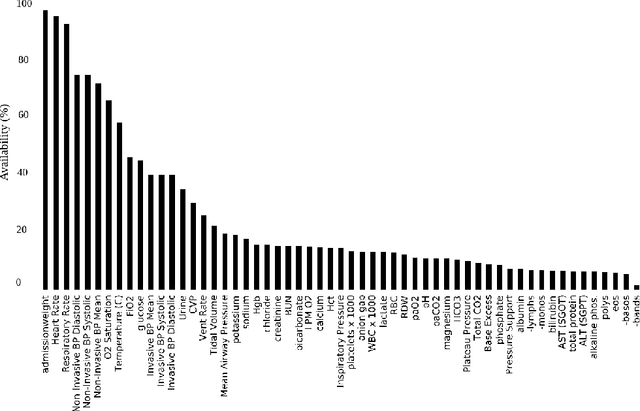
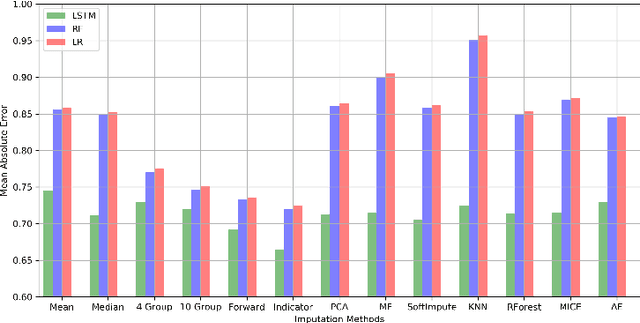
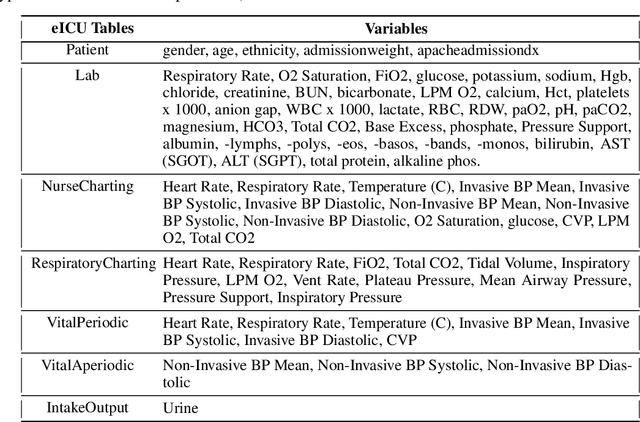
Blood lactate concentration is a strong indicator of mortality risk in critically ill patients. While frequent lactate measurements are necessary to assess patient's health state, the measurement is an invasive procedure that can increase risk of hospital-acquired infections. For this reason we formally define the problem of lactate prediction as a clinically relevant benchmark problem for machine learning community so as to assist clinical decision making in blood lactate testing. Accordingly, we demonstrate the relevant challenges of the problem and its data in addition to the adopted solutions. Also, we evaluate the performance of different prediction algorithms on a large dataset of ICU patients from the multi-centre eICU database. More specifically, we focus on investigating the impact of missing value imputation methods in lactate prediction for each algorithm. The experimental analysis shows promising prediction results that encourages further investigation of this problem.
Novel Adaptive Genetic Algorithm Sample Consensus
Nov 26, 2017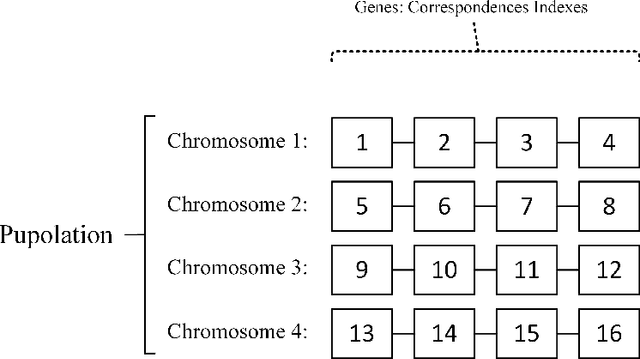

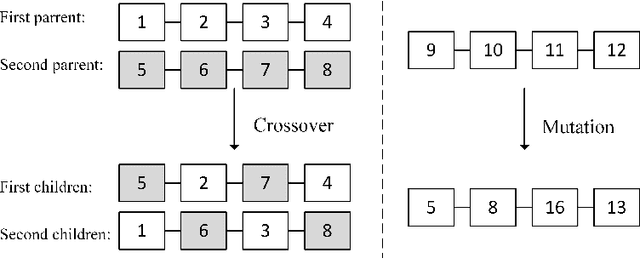
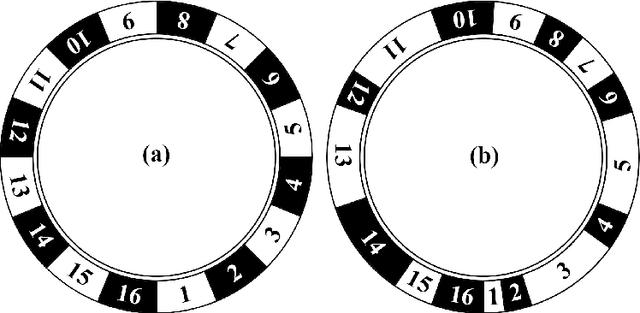
Random sample consensus (RANSAC) is a successful algorithm in model fitting applications. It is vital to have strong exploration phase when there are an enormous amount of outliers within the dataset. Achieving a proper model is guaranteed by pure exploration strategy of RANSAC. However, finding the optimum result requires exploitation. GASAC is an evolutionary paradigm to add exploitation capability to the algorithm. Although GASAC improves the results of RANSAC, it has a fixed strategy for balancing between exploration and exploitation. In this paper, a new paradigm is proposed based on genetic algorithm with an adaptive strategy. We utilize an adaptive genetic operator to select high fitness individuals as parents and mutate low fitness ones. In the mutation phase, a training method is used to gradually learn which gene is the best replacement for the mutated gene. The proposed method adaptively balance between exploration and exploitation by learning about genes. During the final Iterations, the algorithm draws on this information to improve the final results. The proposed method is extensively evaluated on two set of experiments. In all tests, our method outperformed the other methods in terms of both the number of inliers found and the speed of the algorithm.
Knowledge Representation in Learning Classifier Systems: A Review
Jun 12, 2015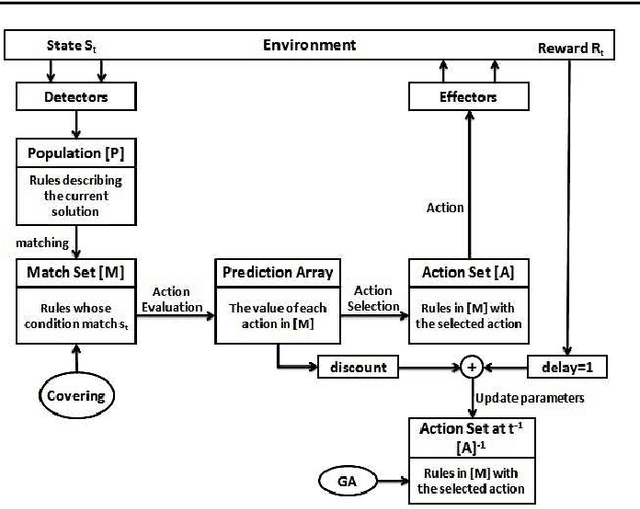
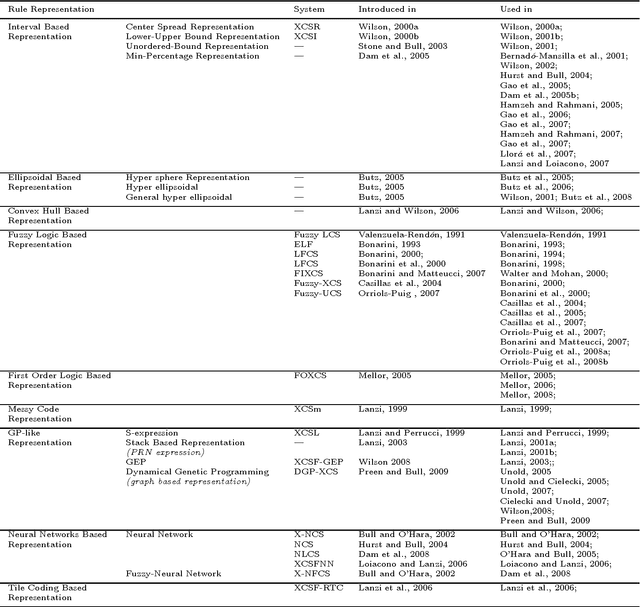
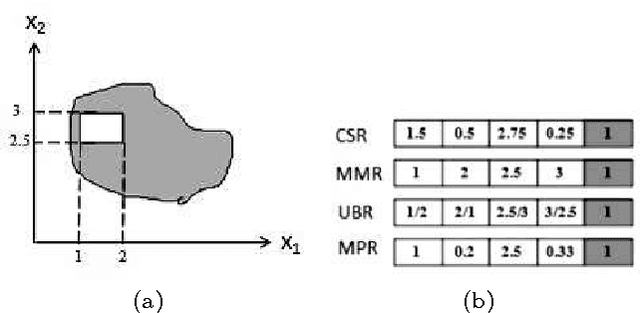
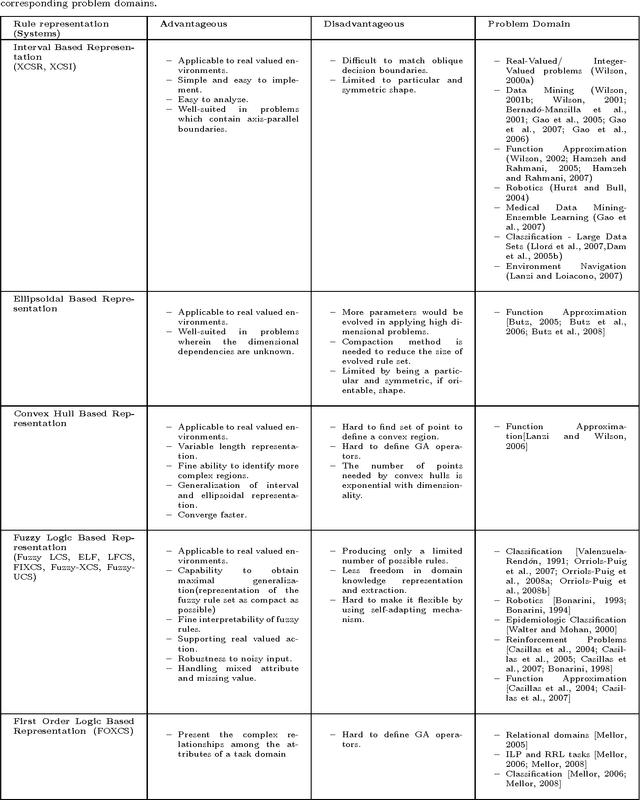
Knowledge representation is a key component to the success of all rule based systems including learning classifier systems (LCSs). This component brings insight into how to partition the problem space what in turn seeks prominent role in generalization capacity of the system as a whole. Recently, knowledge representation component has received great deal of attention within data mining communities due to its impacts on rule based systems in terms of efficiency and efficacy. The current work is an attempt to find a comprehensive and yet elaborate view into the existing knowledge representation techniques in LCS domain in general and XCS in specific. To achieve the objectives, knowledge representation techniques are grouped into different categories based on the classification approach in which they are incorporated. In each category, the underlying rule representation schema and the format of classifier condition to support the corresponding representation are presented. Furthermore, a precise explanation on the way that each technique partitions the problem space along with the extensive experimental results is provided. To have an elaborated view on the functionality of each technique, a comparative analysis of existing techniques on some conventional problems is provided. We expect this survey to be of interest to the LCS researchers and practitioners since it provides a guideline for choosing a proper knowledge representation technique for a given problem and also opens up new streams of research on this topic.
A Novel Hybrid Approach for Cephalometric Landmark Detection
Jun 12, 2015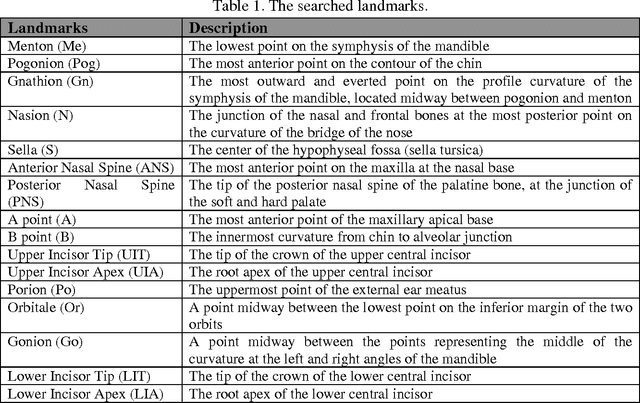
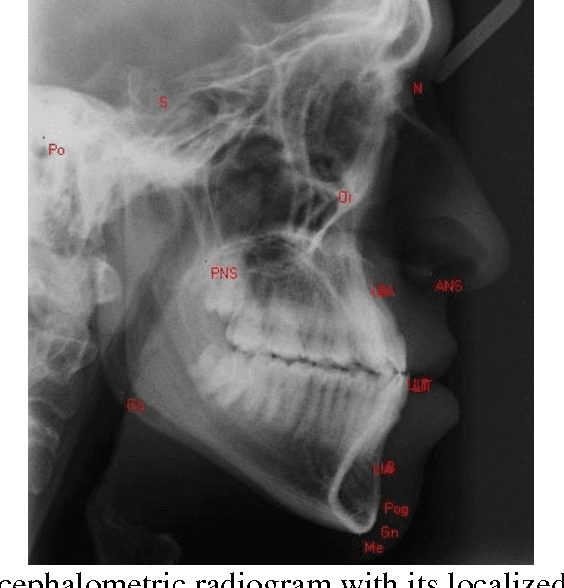
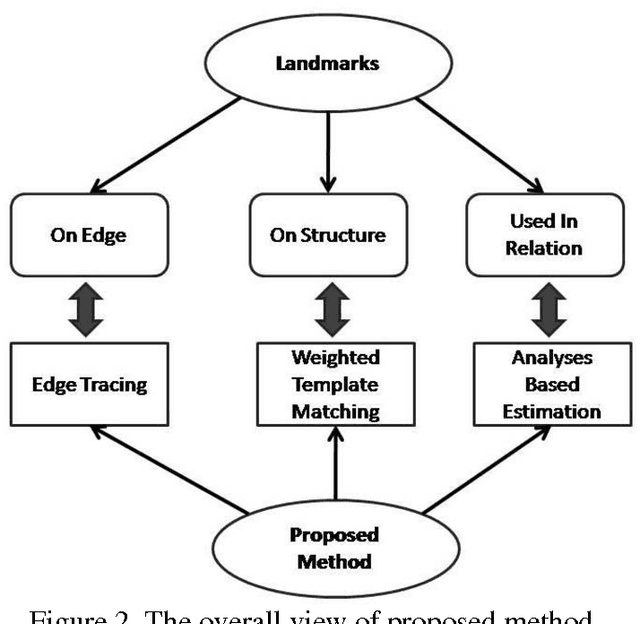

Cephalometric analysis has an important role in dentistry and especially in orthodontics as a treatment planning tool to gauge the size and special relationships of the teeth, jaws and cranium. The first step of using such analyses is localizing some important landmarks known as cephalometric landmarks on craniofacial in x-ray image. The past decade has seen a growing interest in automating this process. In this paper, a novel hybrid approach is proposed for automatic detection of cephalometric landmarks. Here, the landmarks are categorized into three main sets according to their anatomical characteristics and usage in well-known cephalometric analyses. Consequently, to have a reliable and accurate detection system, three methods named edge tracing, weighted template matching, and analysis based estimation are designed, each of which is consistent and well-suited for one category. Edge tracing method is suggested to predict those landmarks which are located on edges. Weighted template matching method is well-suited for landmarks located in an obvious and specific structure which can be extracted or searchable in a given x-ray image. The last but not the least method is named analysis based estimation. This method is based on the fact that in cephalometric analyses the relations between landmarks are used and the locations of some landmarks are never used individually. Therefore the third suggested method has a novelty in estimating the desired relations directly. The effectiveness of the proposed approach is compared with the state of the art methods and the results were promising especially in real world applications.