 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeArtificial Prediction Markets for Online Prediction of Continuous Variables-A Preliminary Report
Aug 11, 2015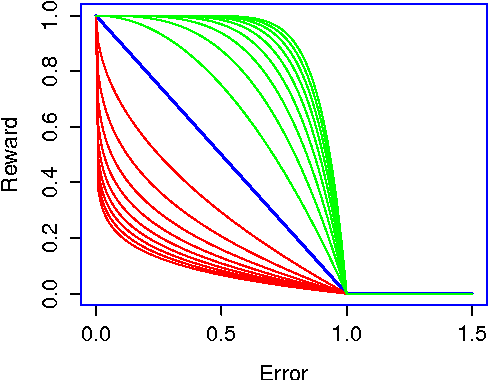
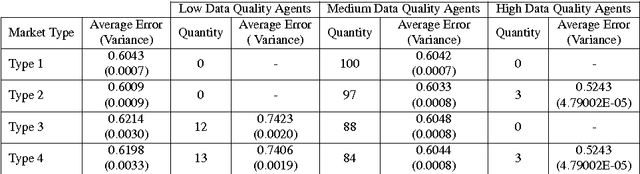
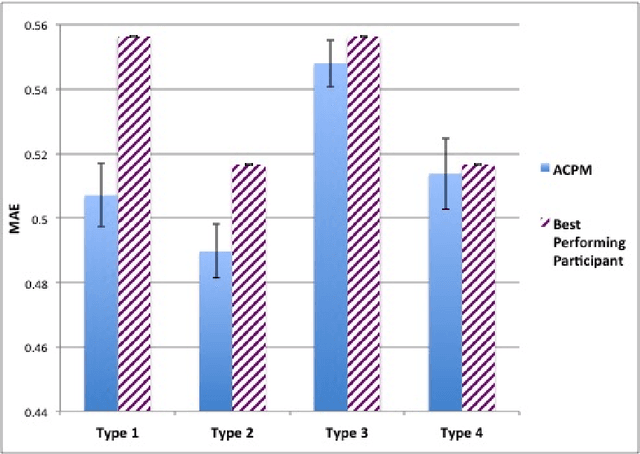
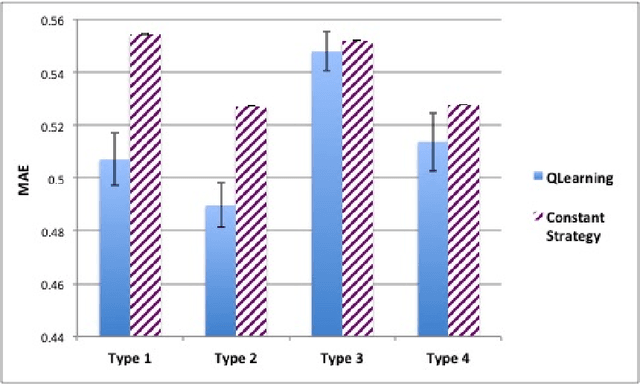
We propose the Artificial Continuous Prediction Market (ACPM) as a means to predict a continuous real value, by integrating a range of data sources and aggregating the results of different machine learning (ML) algorithms. ACPM adapts the concept of the (physical) prediction market to address the prediction of real values instead of discrete events. Each ACPM participant has a data source, a ML algorithm and a local decision-making procedure that determines what to bid on what value. The contributions of ACPM are: (i) adaptation to changes in data quality by the use of learning in: (a) the market, which weights each market participant to adjust the influence of each on the market prediction and (b) the participants, which use a Q-learning based trading strategy to incorporate the market prediction into their subsequent predictions, (ii) resilience to a changing population of low- and high-performing participants. We demonstrate the effectiveness of ACPM by application to an influenza-like illnesses data set, showing ACPM out-performs a range of well-known regression models and is resilient to variation in data source quality.
Knowledge Representation in Learning Classifier Systems: A Review
Jun 12, 2015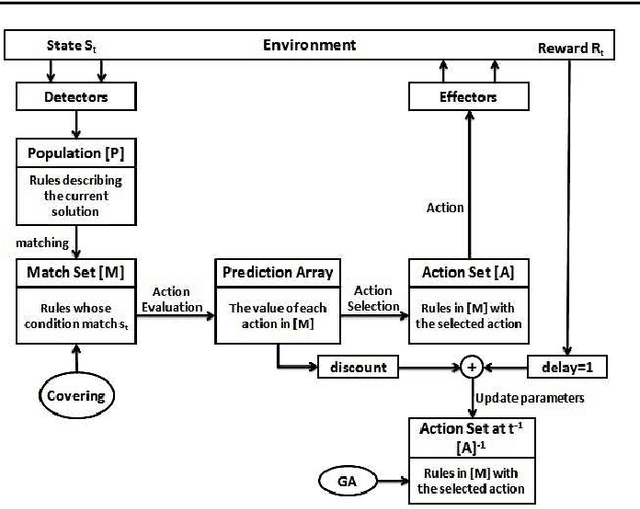
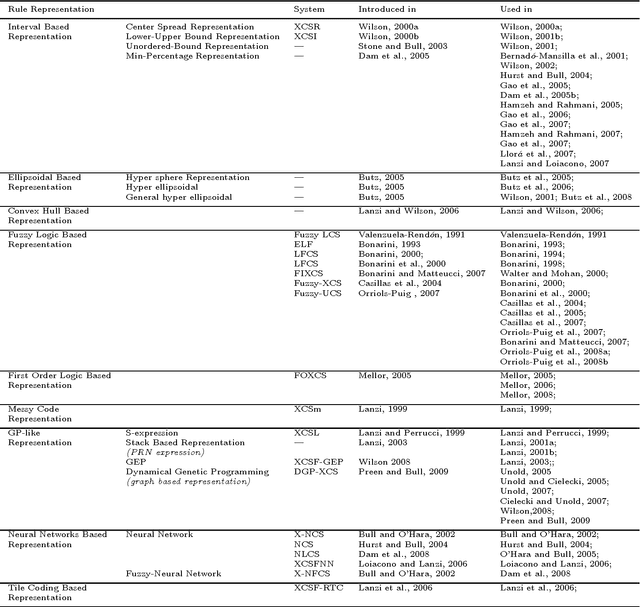
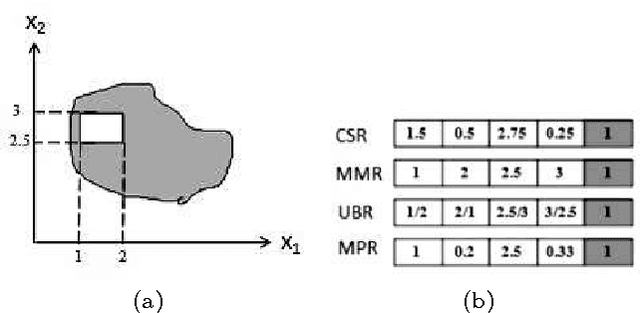
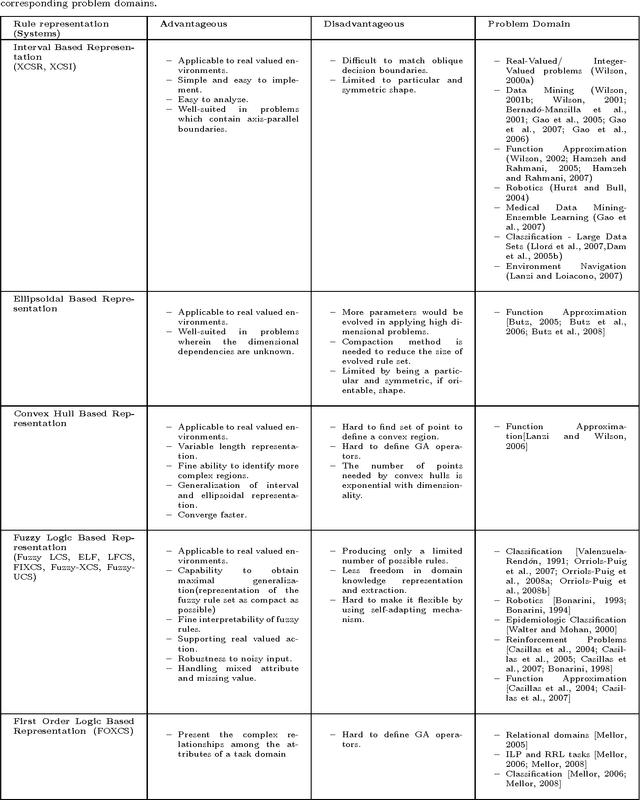
Knowledge representation is a key component to the success of all rule based systems including learning classifier systems (LCSs). This component brings insight into how to partition the problem space what in turn seeks prominent role in generalization capacity of the system as a whole. Recently, knowledge representation component has received great deal of attention within data mining communities due to its impacts on rule based systems in terms of efficiency and efficacy. The current work is an attempt to find a comprehensive and yet elaborate view into the existing knowledge representation techniques in LCS domain in general and XCS in specific. To achieve the objectives, knowledge representation techniques are grouped into different categories based on the classification approach in which they are incorporated. In each category, the underlying rule representation schema and the format of classifier condition to support the corresponding representation are presented. Furthermore, a precise explanation on the way that each technique partitions the problem space along with the extensive experimental results is provided. To have an elaborated view on the functionality of each technique, a comparative analysis of existing techniques on some conventional problems is provided. We expect this survey to be of interest to the LCS researchers and practitioners since it provides a guideline for choosing a proper knowledge representation technique for a given problem and also opens up new streams of research on this topic.
A Novel Strategy Selection Method for Multi-Objective Clustering Algorithms Using Game Theory
Aug 15, 2012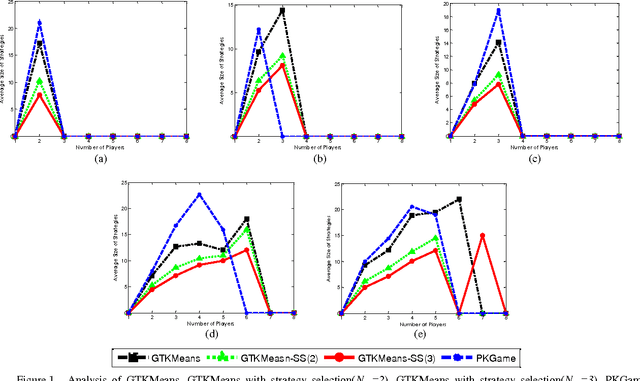

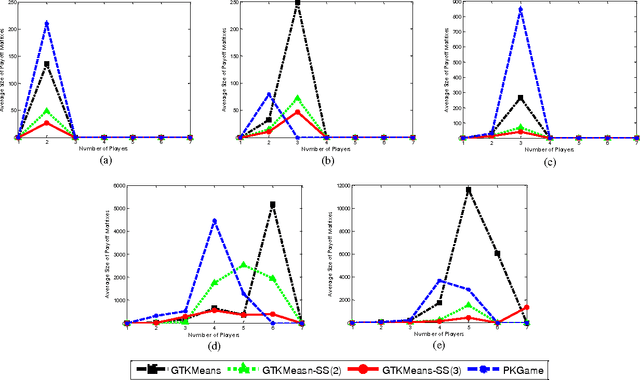
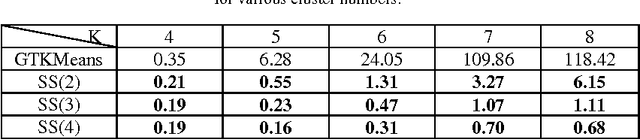
The most important factors which contribute to the efficiency of game-theoretical algorithms are time and game complexity. In this study, we have offered an elegant method to deal with high complexity of game theoretic multi-objective clustering methods in large-sized data sets. Here, we have developed a method which selects a subset of strategies from strategies profile for each player. In this case, the size of payoff matrices reduces significantly which has a remarkable impact on time complexity. Therefore, practical problems with more data are tractable with less computational complexity. Although strategies set may grow with increasing the number of data points, the presented model of strategy selection reduces the strategy space, considerably, where clusters are subdivided into several sub-clusters in each local game. The remarkable results demonstrate the efficiency of the presented approach in reducing computational complexity of the problem of concern.
Dispelling Classes Gradually to Improve Quality of Feature Reduction Approaches
Jun 07, 2012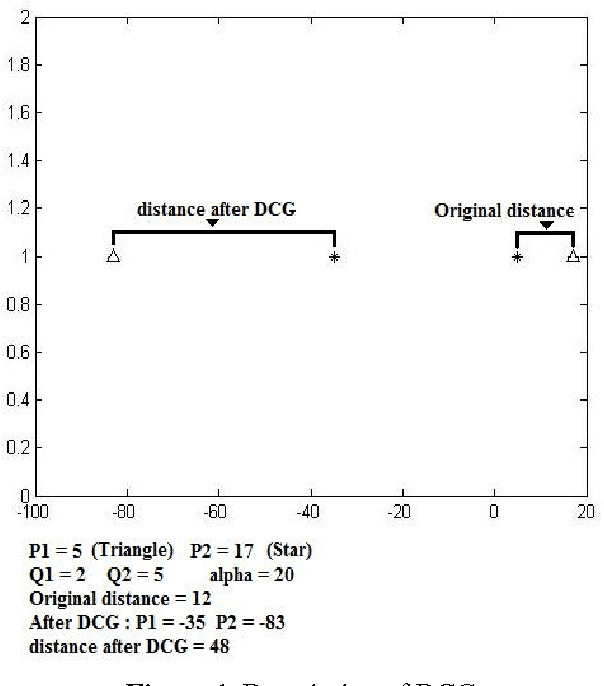
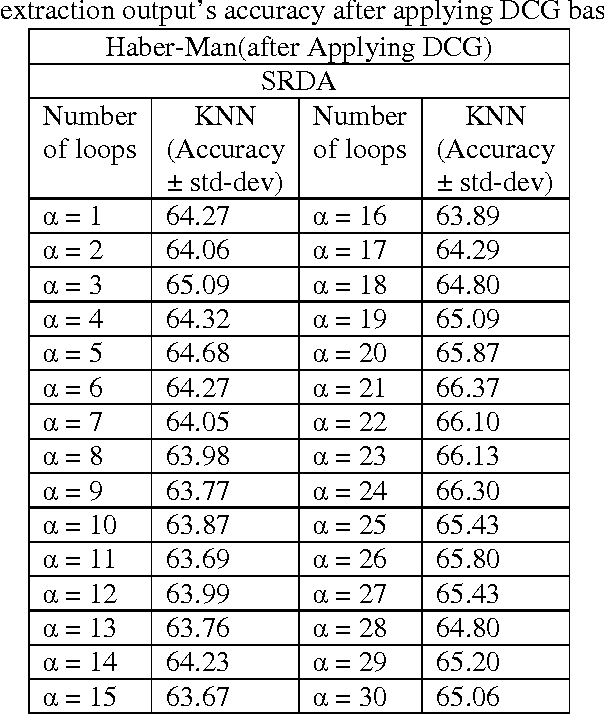
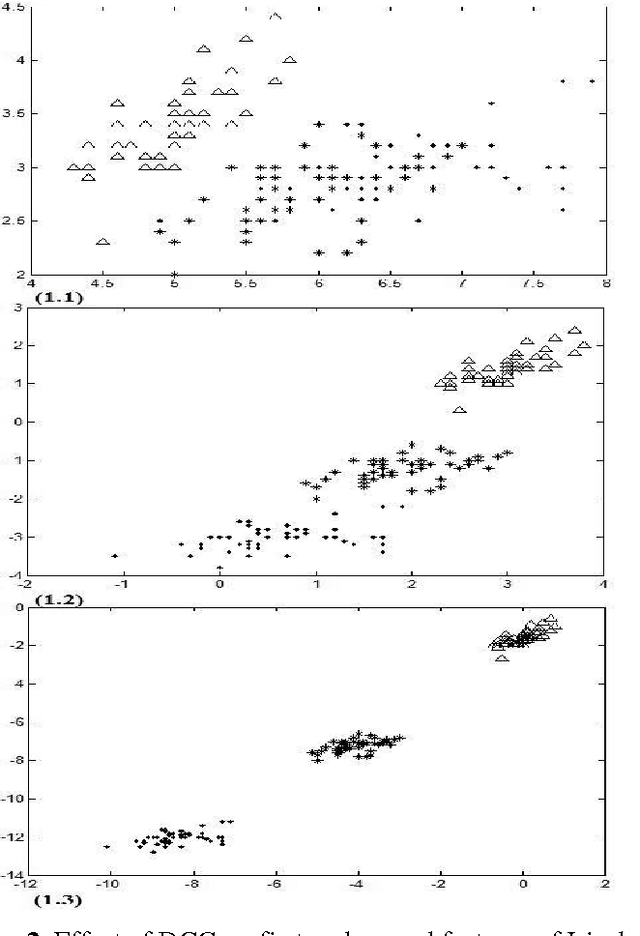
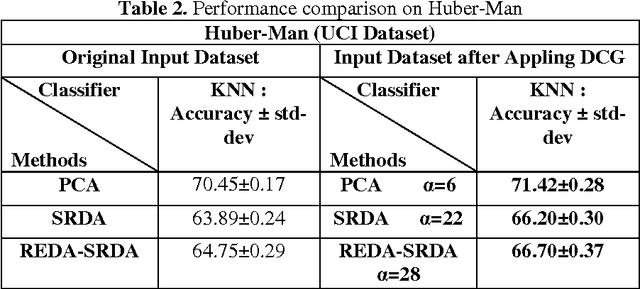
Feature reduction is an important concept which is used for reducing dimensions to decrease the computation complexity and time of classification. Since now many approaches have been proposed for solving this problem, but almost all of them just presented a fix output for each input dataset that some of them aren't satisfied cases for classification. In this we proposed an approach as processing input dataset to increase accuracy rate of each feature extraction methods. First of all, a new concept called dispelling classes gradually (DCG) is proposed to increase separability of classes based on their labels. Next, this method is used to process input dataset of the feature reduction approaches to decrease the misclassification error rate of their outputs more than when output is achieved without any processing. In addition our method has a good quality to collate with noise based on adapting dataset with feature reduction approaches. In the result part, two conditions (With process and without that) are compared to support our idea by using some of UCI datasets.