 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTextDoctor: Unified Document Image Inpainting via Patch Pyramid Diffusion Models
Mar 06, 2025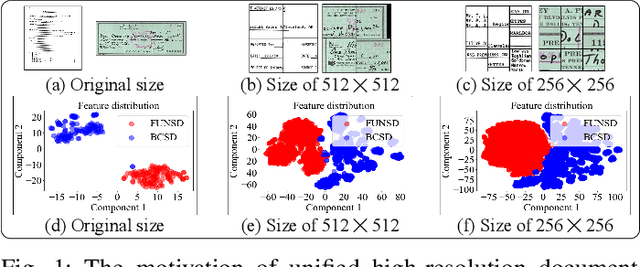

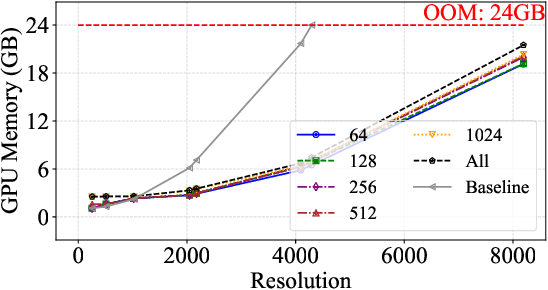
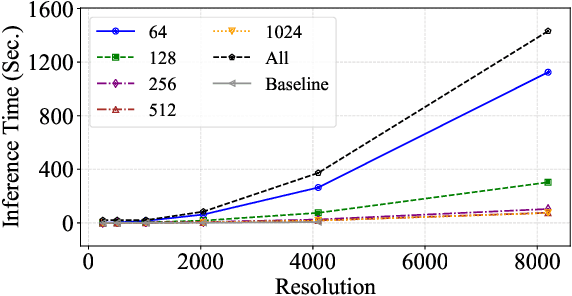
Digital versions of real-world text documents often suffer from issues like environmental corrosion of the original document, low-quality scanning, or human interference. Existing document restoration and inpainting methods typically struggle with generalizing to unseen document styles and handling high-resolution images. To address these challenges, we introduce TextDoctor, a novel unified document image inpainting method. Inspired by human reading behavior, TextDoctor restores fundamental text elements from patches and then applies diffusion models to entire document images instead of training models on specific document types. To handle varying text sizes and avoid out-of-memory issues, common in high-resolution documents, we propose using structure pyramid prediction and patch pyramid diffusion models. These techniques leverage multiscale inputs and pyramid patches to enhance the quality of inpainting both globally and locally. Extensive qualitative and quantitative experiments on seven public datasets validated that TextDoctor outperforms state-of-the-art methods in restoring various types of high-resolution document images.
Robust Black-box Watermarking for Deep NeuralNetwork using Inverse Document Frequency
Mar 09, 2021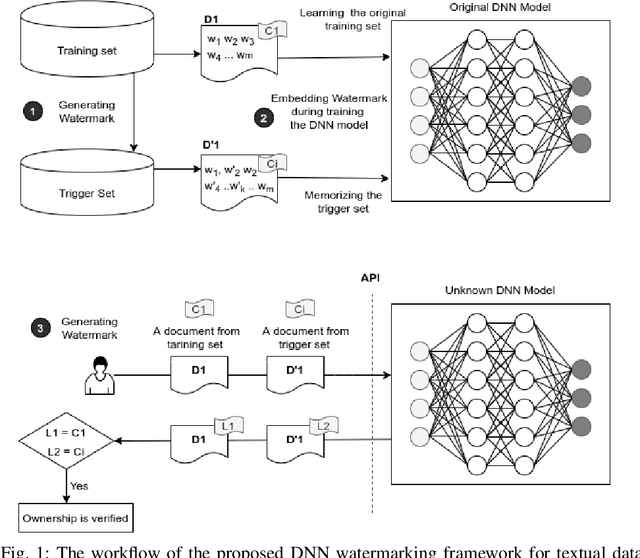
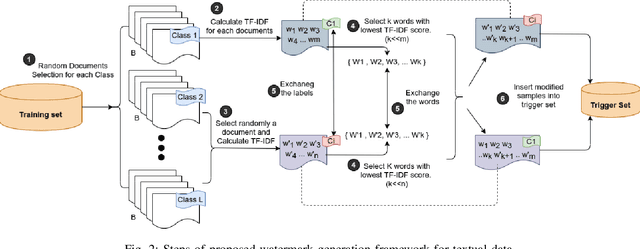

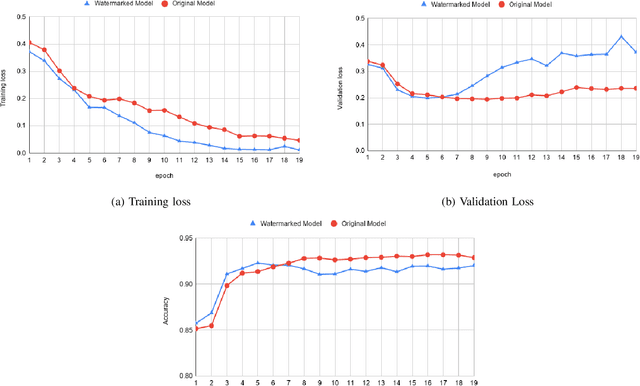
Deep learning techniques are one of the most significant elements of any Artificial Intelligence (AI) services. Recently, these Machine Learning (ML) methods, such as Deep Neural Networks (DNNs), presented exceptional achievement in implementing human-level capabilities for various predicaments, such as Natural Processing Language (NLP), voice recognition, and image processing, etc. Training these models are expensive in terms of computational power and the existence of enough labelled data. Thus, ML-based models such as DNNs establish genuine business value and intellectual property (IP) for their owners. Therefore the trained models need to be protected from any adversary attacks such as illegal redistribution, reproducing, and derivation. Watermarking can be considered as an effective technique for securing a DNN model. However, so far, most of the watermarking algorithm focuses on watermarking the DNN by adding noise to an image. To this end, we propose a framework for watermarking a DNN model designed for a textual domain. The watermark generation scheme provides a secure watermarking method by combining Term Frequency (TF) and Inverse Document Frequency (IDF) of a particular word. The proposed embedding procedure takes place in the model's training time, making the watermark verification stage straightforward by sending the watermarked document to the trained model. The experimental results show that watermarked models have the same accuracy as the original ones. The proposed framework accurately verifies the ownership of all surrogate models without impairing the performance. The proposed algorithm is robust against well-known attacks such as parameter pruning and brute force attack.
Knowledge Representation in Learning Classifier Systems: A Review
Jun 12, 2015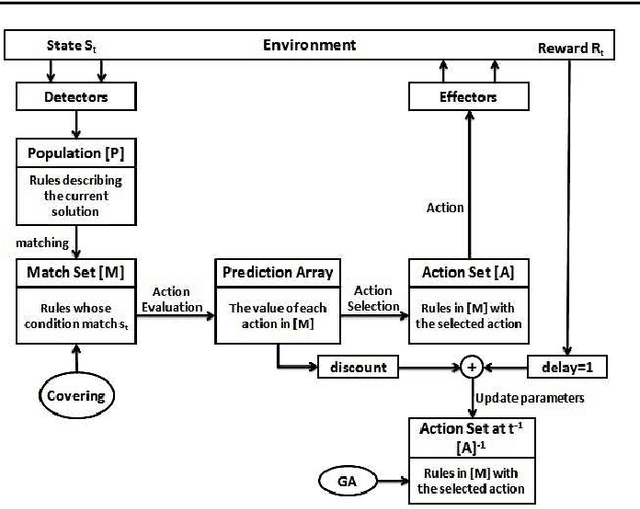
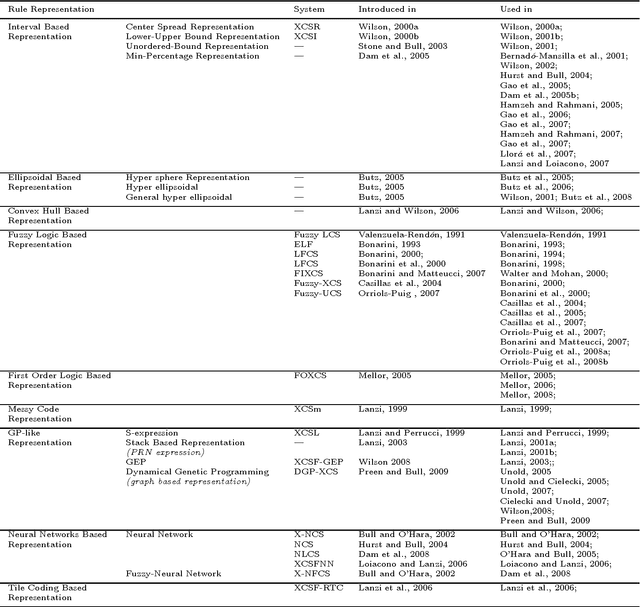
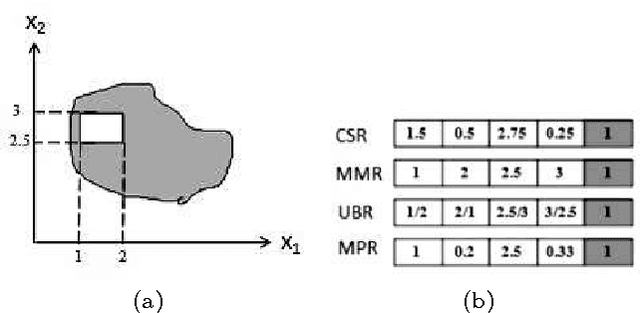
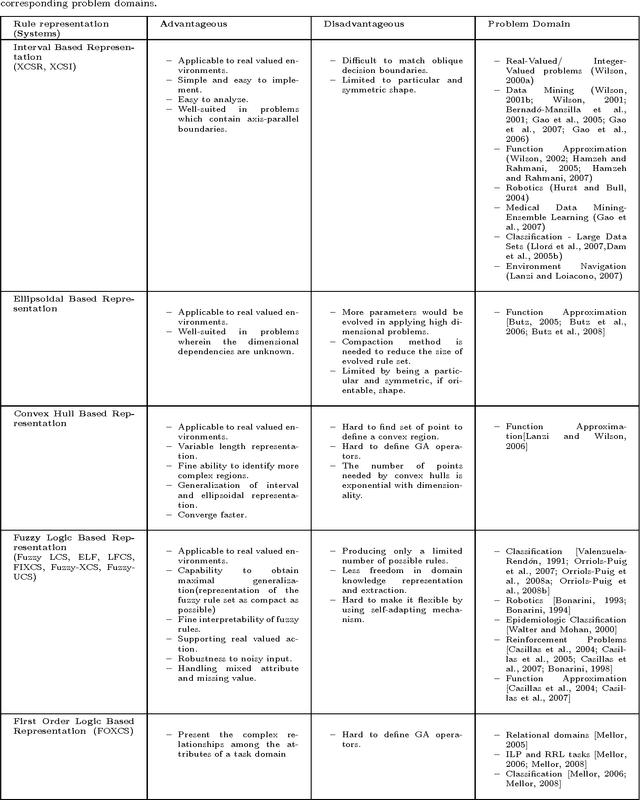
Knowledge representation is a key component to the success of all rule based systems including learning classifier systems (LCSs). This component brings insight into how to partition the problem space what in turn seeks prominent role in generalization capacity of the system as a whole. Recently, knowledge representation component has received great deal of attention within data mining communities due to its impacts on rule based systems in terms of efficiency and efficacy. The current work is an attempt to find a comprehensive and yet elaborate view into the existing knowledge representation techniques in LCS domain in general and XCS in specific. To achieve the objectives, knowledge representation techniques are grouped into different categories based on the classification approach in which they are incorporated. In each category, the underlying rule representation schema and the format of classifier condition to support the corresponding representation are presented. Furthermore, a precise explanation on the way that each technique partitions the problem space along with the extensive experimental results is provided. To have an elaborated view on the functionality of each technique, a comparative analysis of existing techniques on some conventional problems is provided. We expect this survey to be of interest to the LCS researchers and practitioners since it provides a guideline for choosing a proper knowledge representation technique for a given problem and also opens up new streams of research on this topic.
A Novel Hybrid Approach for Cephalometric Landmark Detection
Jun 12, 2015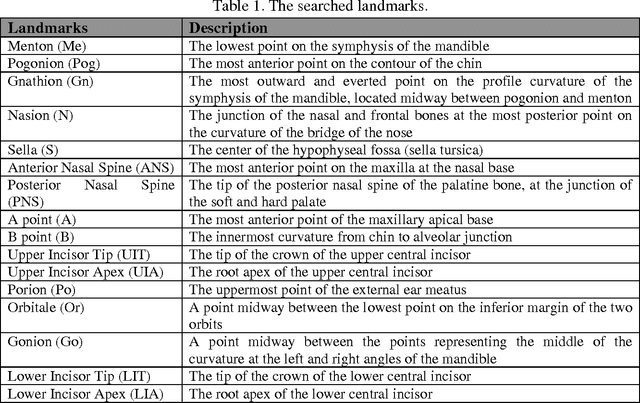
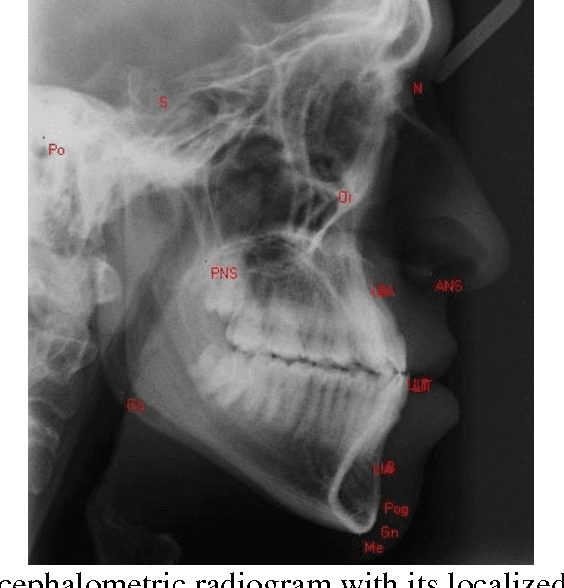
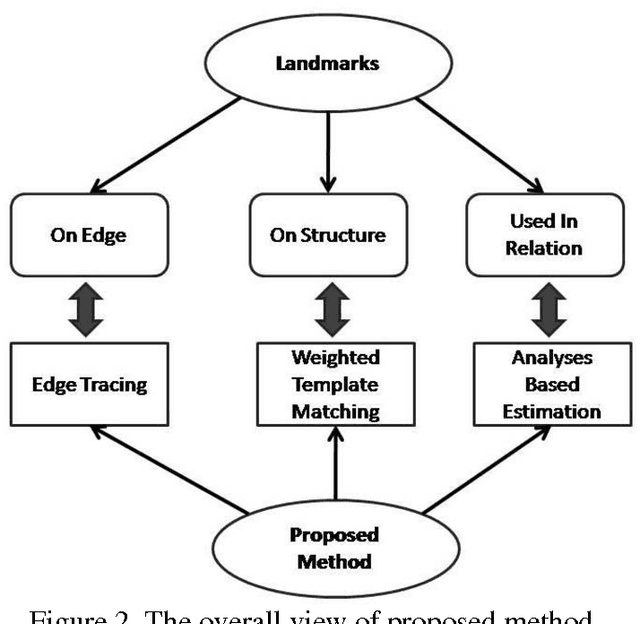

Cephalometric analysis has an important role in dentistry and especially in orthodontics as a treatment planning tool to gauge the size and special relationships of the teeth, jaws and cranium. The first step of using such analyses is localizing some important landmarks known as cephalometric landmarks on craniofacial in x-ray image. The past decade has seen a growing interest in automating this process. In this paper, a novel hybrid approach is proposed for automatic detection of cephalometric landmarks. Here, the landmarks are categorized into three main sets according to their anatomical characteristics and usage in well-known cephalometric analyses. Consequently, to have a reliable and accurate detection system, three methods named edge tracing, weighted template matching, and analysis based estimation are designed, each of which is consistent and well-suited for one category. Edge tracing method is suggested to predict those landmarks which are located on edges. Weighted template matching method is well-suited for landmarks located in an obvious and specific structure which can be extracted or searchable in a given x-ray image. The last but not the least method is named analysis based estimation. This method is based on the fact that in cephalometric analyses the relations between landmarks are used and the locations of some landmarks are never used individually. Therefore the third suggested method has a novelty in estimating the desired relations directly. The effectiveness of the proposed approach is compared with the state of the art methods and the results were promising especially in real world applications.