 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Comparative Study of EMG- and IMU-based Gesture Recognition at the Wrist and Forearm
Dec 08, 2025Gestures are an integral part of our daily interactions with the environment. Hand gesture recognition (HGR) is the process of interpreting human intent through various input modalities, such as visual data (images and videos) and bio-signals. Bio-signals are widely used in HGR due to their ability to be captured non-invasively via sensors placed on the arm. Among these, surface electromyography (sEMG), which measures the electrical activity of muscles, is the most extensively studied modality. However, less-explored alternatives such as inertial measurement units (IMUs) can provide complementary information on subtle muscle movements, which makes them valuable for gesture recognition. In this study, we investigate the potential of using IMU signals from different muscle groups to capture user intent. Our results demonstrate that IMU signals contain sufficient information to serve as the sole input sensor for static gesture recognition. Moreover, we compare different muscle groups and check the quality of pattern recognition on individual muscle groups. We further found that tendon-induced micro-movement captured by IMUs is a major contributor to static gesture recognition. We believe that leveraging muscle micro-movement information can enhance the usability of prosthetic arms for amputees. This approach also offers new possibilities for hand gesture recognition in fields such as robotics, teleoperation, sign language interpretation, and beyond.
Towards Biosignals-Free Autonomous Prosthetic Hand Control via Imitation Learning
Jun 10, 2025



Limb loss affects millions globally, impairing physical function and reducing quality of life. Most traditional surface electromyographic (sEMG) and semi-autonomous methods require users to generate myoelectric signals for each control, imposing physically and mentally taxing demands. This study aims to develop a fully autonomous control system that enables a prosthetic hand to automatically grasp and release objects of various shapes using only a camera attached to the wrist. By placing the hand near an object, the system will automatically execute grasping actions with a proper grip force in response to the hand's movements and the environment. To release the object being grasped, just naturally place the object close to the table and the system will automatically open the hand. Such a system would provide individuals with limb loss with a very easy-to-use prosthetic control interface and greatly reduce mental effort while using. To achieve this goal, we developed a teleoperation system to collect human demonstration data for training the prosthetic hand control model using imitation learning, which mimics the prosthetic hand actions from human. Through training the model using only a few objects' data from one single participant, we have shown that the imitation learning algorithm can achieve high success rates, generalizing to more individuals and unseen objects with a variation of weights. The demonstrations are available at \href{https://sites.google.com/view/autonomous-prosthetic-hand}{https://sites.google.com/view/autonomous-prosthetic-hand}
TextDoctor: Unified Document Image Inpainting via Patch Pyramid Diffusion Models
Mar 06, 2025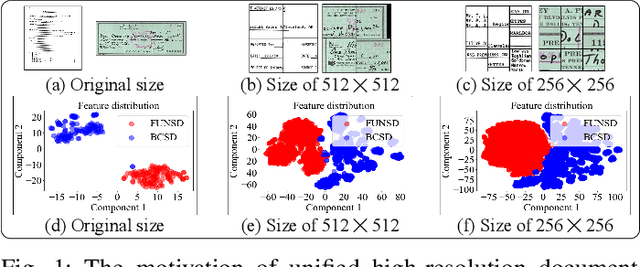

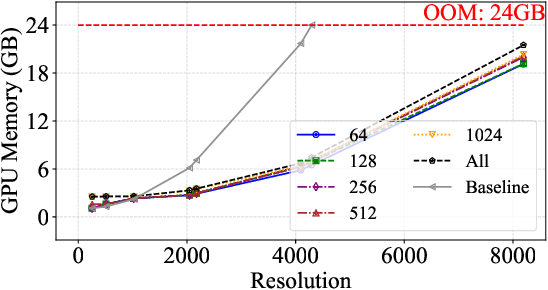
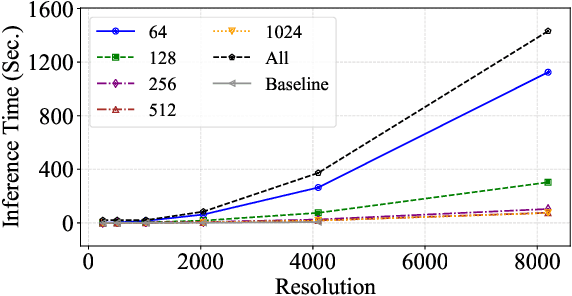
Digital versions of real-world text documents often suffer from issues like environmental corrosion of the original document, low-quality scanning, or human interference. Existing document restoration and inpainting methods typically struggle with generalizing to unseen document styles and handling high-resolution images. To address these challenges, we introduce TextDoctor, a novel unified document image inpainting method. Inspired by human reading behavior, TextDoctor restores fundamental text elements from patches and then applies diffusion models to entire document images instead of training models on specific document types. To handle varying text sizes and avoid out-of-memory issues, common in high-resolution documents, we propose using structure pyramid prediction and patch pyramid diffusion models. These techniques leverage multiscale inputs and pyramid patches to enhance the quality of inpainting both globally and locally. Extensive qualitative and quantitative experiments on seven public datasets validated that TextDoctor outperforms state-of-the-art methods in restoring various types of high-resolution document images.
Visual Style Prompt Learning Using Diffusion Models for Blind Face Restoration
Dec 30, 2024



Blind face restoration aims to recover high-quality facial images from various unidentified sources of degradation, posing significant challenges due to the minimal information retrievable from the degraded images. Prior knowledge-based methods, leveraging geometric priors and facial features, have led to advancements in face restoration but often fall short of capturing fine details. To address this, we introduce a visual style prompt learning framework that utilizes diffusion probabilistic models to explicitly generate visual prompts within the latent space of pre-trained generative models. These prompts are designed to guide the restoration process. To fully utilize the visual prompts and enhance the extraction of informative and rich patterns, we introduce a style-modulated aggregation transformation layer. Extensive experiments and applications demonstrate the superiority of our method in achieving high-quality blind face restoration. The source code is available at \href{https://github.com/LonglongaaaGo/VSPBFR}{https://github.com/LonglongaaaGo/VSPBFR}.
* Published at Pattern Recognition; 13 pages, 11 figures
FACEMUG: A Multimodal Generative and Fusion Framework for Local Facial Editing
Dec 26, 2024Existing facial editing methods have achieved remarkable results, yet they often fall short in supporting multimodal conditional local facial editing. One of the significant evidences is that their output image quality degrades dramatically after several iterations of incremental editing, as they do not support local editing. In this paper, we present a novel multimodal generative and fusion framework for globally-consistent local facial editing (FACEMUG) that can handle a wide range of input modalities and enable fine-grained and semantic manipulation while remaining unedited parts unchanged. Different modalities, including sketches, semantic maps, color maps, exemplar images, text, and attribute labels, are adept at conveying diverse conditioning details, and their combined synergy can provide more explicit guidance for the editing process. We thus integrate all modalities into a unified generative latent space to enable multimodal local facial edits. Specifically, a novel multimodal feature fusion mechanism is proposed by utilizing multimodal aggregation and style fusion blocks to fuse facial priors and multimodalities in both latent and feature spaces. We further introduce a novel self-supervised latent warping algorithm to rectify misaligned facial features, efficiently transferring the pose of the edited image to the given latent codes. We evaluate our FACEMUG through extensive experiments and comparisons to state-of-the-art (SOTA) methods. The results demonstrate the superiority of FACEMUG in terms of editing quality, flexibility, and semantic control, making it a promising solution for a wide range of local facial editing tasks.
High-Order Tensor Recovery with A Tensor $U_1$ Norm
Nov 23, 2023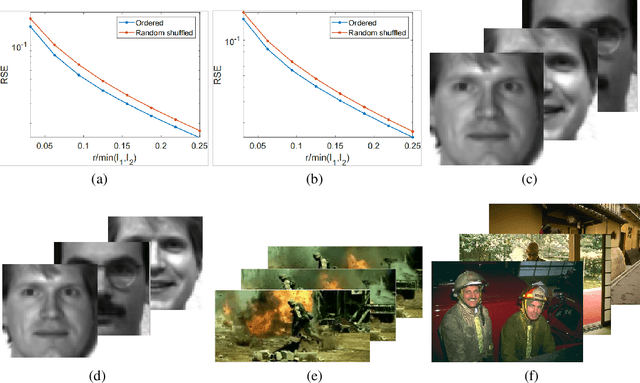


Recently, numerous tensor SVD (t-SVD)-based tensor recovery methods have emerged, showing promise in processing visual data. However, these methods often suffer from performance degradation when confronted with high-order tensor data exhibiting non-smooth changes, commonly observed in real-world scenarios but ignored by the traditional t-SVD-based methods. Our objective in this study is to provide an effective tensor recovery technique for handling non-smooth changes in tensor data and efficiently explore the correlations of high-order tensor data across its various dimensions without introducing numerous variables and weights. To this end, we introduce a new tensor decomposition and a new tensor norm called the Tensor $U_1$ norm. We utilize these novel techniques in solving the problem of high-order tensor completion problem and provide theoretical guarantees for the exact recovery of the resulting tensor completion models. An optimization algorithm is proposed to solve the resulting tensor completion model iteratively by combining the proximal algorithm with the Alternating Direction Method of Multipliers. Theoretical analysis showed the convergence of the algorithm to the Karush-Kuhn-Tucker (KKT) point of the optimization problem. Numerical experiments demonstrated the effectiveness of the proposed method in high-order tensor completion, especially for tensor data with non-smooth changes.
Synthetic Demographic Data Generation for Card Fraud Detection Using GANs
Jun 29, 2023Using machine learning models to generate synthetic data has become common in many fields. Technology to generate synthetic transactions that can be used to detect fraud is also growing fast. Generally, this synthetic data contains only information about the transaction, such as the time, place, and amount of money. It does not usually contain the individual user's characteristics (age and gender are occasionally included). Using relatively complex synthetic demographic data may improve the complexity of transaction data features, thus improving the fraud detection performance. Benefiting from developments of machine learning, some deep learning models have potential to perform better than other well-established synthetic data generation methods, such as microsimulation. In this study, we built a deep-learning Generative Adversarial Network (GAN), called DGGAN, which will be used for demographic data generation. Our model generates samples during model training, which we found important to overcame class imbalance issues. This study can help improve the cognition of synthetic data and further explore the application of synthetic data generation in card fraud detection.
A Novel Tensor Factorization-Based Method with Robustness to Inaccurate Rank Estimation
May 19, 2023



This study aims to solve the over-reliance on the rank estimation strategy in the standard tensor factorization-based tensor recovery and the problem of a large computational cost in the standard t-SVD-based tensor recovery. To this end, we proposes a new tensor norm with a dual low-rank constraint, which utilizes the low-rank prior and rank information at the same time. In the proposed tensor norm, a series of surrogate functions of the tensor tubal rank can be used to achieve better performance in harness low-rankness within tensor data. It is proven theoretically that the resulting tensor completion model can effectively avoid performance degradation caused by inaccurate rank estimation. Meanwhile, attributed to the proposed dual low-rank constraint, the t-SVD of a smaller tensor instead of the original big one is computed by using a sample trick. Based on this, the total cost at each iteration of the optimization algorithm is reduced to $\mathcal{O}(n^3\log n +kn^3)$ from $\mathcal{O}(n^4)$ achieved with standard methods, where $k$ is the estimation of the true tensor rank and far less than $n$. Our method was evaluated on synthetic and real-world data, and it demonstrated superior performance and efficiency over several existing state-of-the-art tensor completion methods.
GRIG: Few-Shot Generative Residual Image Inpainting
Apr 24, 2023



Image inpainting is the task of filling in missing or masked region of an image with semantically meaningful contents. Recent methods have shown significant improvement in dealing with large-scale missing regions. However, these methods usually require large training datasets to achieve satisfactory results and there has been limited research into training these models on a small number of samples. To address this, we present a novel few-shot generative residual image inpainting method that produces high-quality inpainting results. The core idea is to propose an iterative residual reasoning method that incorporates Convolutional Neural Networks (CNNs) for feature extraction and Transformers for global reasoning within generative adversarial networks, along with image-level and patch-level discriminators. We also propose a novel forgery-patch adversarial training strategy to create faithful textures and detailed appearances. Extensive evaluations show that our method outperforms previous methods on the few-shot image inpainting task, both quantitatively and qualitatively.
DcnnGrasp: Towards Accurate Grasp Pattern Recognition with Adaptive Regularizer Learning
May 11, 2022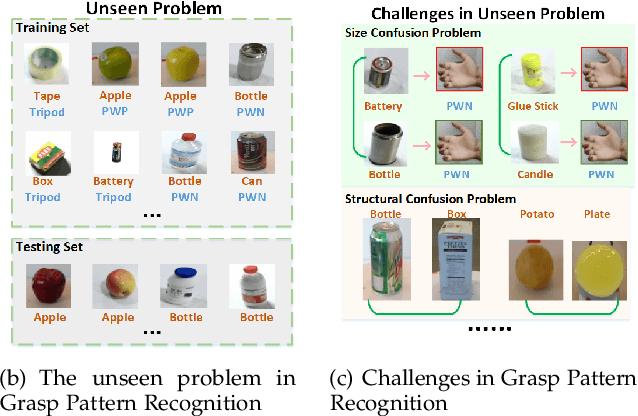



The task of grasp pattern recognition aims to derive the applicable grasp types of an object according to the visual information. Current state-of-the-art methods ignore category information of objects which is crucial for grasp pattern recognition. This paper presents a novel dual-branch convolutional neural network (DcnnGrasp) to achieve joint learning of object category classification and grasp pattern recognition. DcnnGrasp takes object category classification as an auxiliary task to improve the effectiveness of grasp pattern recognition. Meanwhile, a new loss function called joint cross-entropy with an adaptive regularizer is derived through maximizing a posterior, which significantly improves the model performance. Besides, based on the new loss function, a training strategy is proposed to maximize the collaborative learning of the two tasks. The experiment was performed on five household objects datasets including the RGB-D Object dataset, Hit-GPRec dataset, Amsterdam library of object images (ALOI), Columbia University Image Library (COIL-100), and MeganePro dataset 1. The experimental results demonstrated that the proposed method can achieve competitive performance on grasp pattern recognition with several state-of-the-art methods. Specifically, our method even outperformed the second-best one by nearly 15% in terms of global accuracy for the case of testing a novel object on the RGB-D Object dataset.