 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn Catastrophic Forgetting in Low-Rank Decomposition-Based Parameter-Efficient Fine-Tuning
Mar 10, 2026Parameter-efficient fine-tuning (PEFT) based on low-rank decomposition, such as LoRA, has become a standard for adapting large pretrained models. However, its behavior in sequential learning -- specifically regarding catastrophic forgetting -- remains insufficiently understood. In this work, we present an empirical study showing that forgetting is strongly influenced by the geometry and parameterization of the update subspace. While methods that restrict updates to small, shared matrix subspaces often suffer from task interference, tensor-based decompositions (e.g., LoRETTA) mitigate forgetting by capturing richer structural information within ultra-compact budgets, and structurally aligned parameterizations (e.g., WeGeFT) preserve pretrained representations. Our findings highlight update subspace design as a key factor in continual learning and offer practical guidance for selecting efficient adaptation strategies in sequential settings.
TextDoctor: Unified Document Image Inpainting via Patch Pyramid Diffusion Models
Mar 06, 2025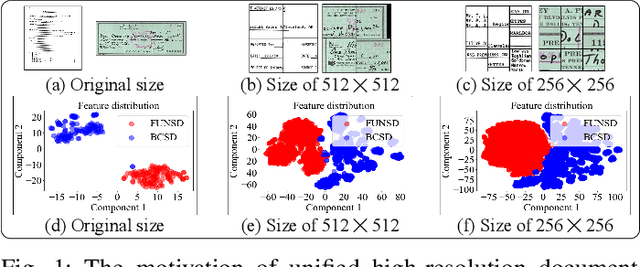

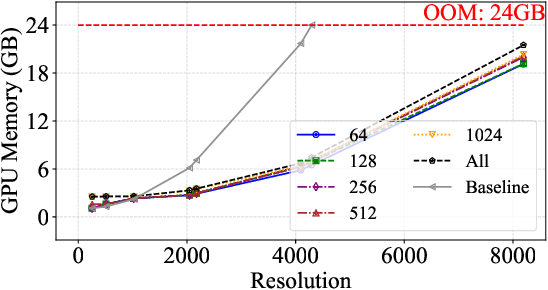
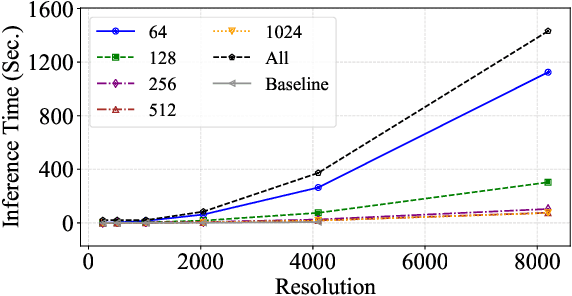
Digital versions of real-world text documents often suffer from issues like environmental corrosion of the original document, low-quality scanning, or human interference. Existing document restoration and inpainting methods typically struggle with generalizing to unseen document styles and handling high-resolution images. To address these challenges, we introduce TextDoctor, a novel unified document image inpainting method. Inspired by human reading behavior, TextDoctor restores fundamental text elements from patches and then applies diffusion models to entire document images instead of training models on specific document types. To handle varying text sizes and avoid out-of-memory issues, common in high-resolution documents, we propose using structure pyramid prediction and patch pyramid diffusion models. These techniques leverage multiscale inputs and pyramid patches to enhance the quality of inpainting both globally and locally. Extensive qualitative and quantitative experiments on seven public datasets validated that TextDoctor outperforms state-of-the-art methods in restoring various types of high-resolution document images.
Adaptive Principal Components Allocation with the $\ell_{2,g}$-regularized Gaussian Graphical Model for Efficient Fine-Tuning Large Models
Dec 11, 2024


In this work, we propose a novel Parameter-Efficient Fine-Tuning (PEFT) approach based on Gaussian Graphical Models (GGMs), marking the first application of GGMs to PEFT tasks, to the best of our knowledge. The proposed method utilizes the $\ell_{2,g}$-norm to effectively select critical parameters and capture global dependencies. The resulting non-convex optimization problem is efficiently solved using a Block Coordinate Descent (BCD) algorithm. Experimental results on the GLUE benchmark [24] for fine-tuning RoBERTa-Base [18] demonstrate the effectiveness of the proposed approach, achieving competitive performance with significantly fewer trainable parameters. The code for this work is available at: https://github.com/jzheng20/Course projects.git.
A Novel Defense Against Poisoning Attacks on Federated Learning: LayerCAM Augmented with Autoencoder
Jun 02, 2024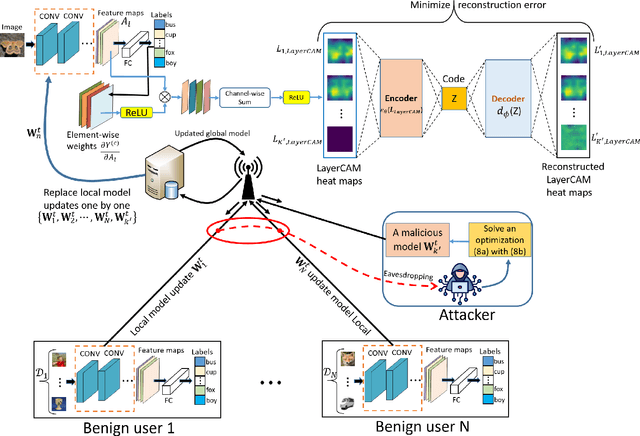

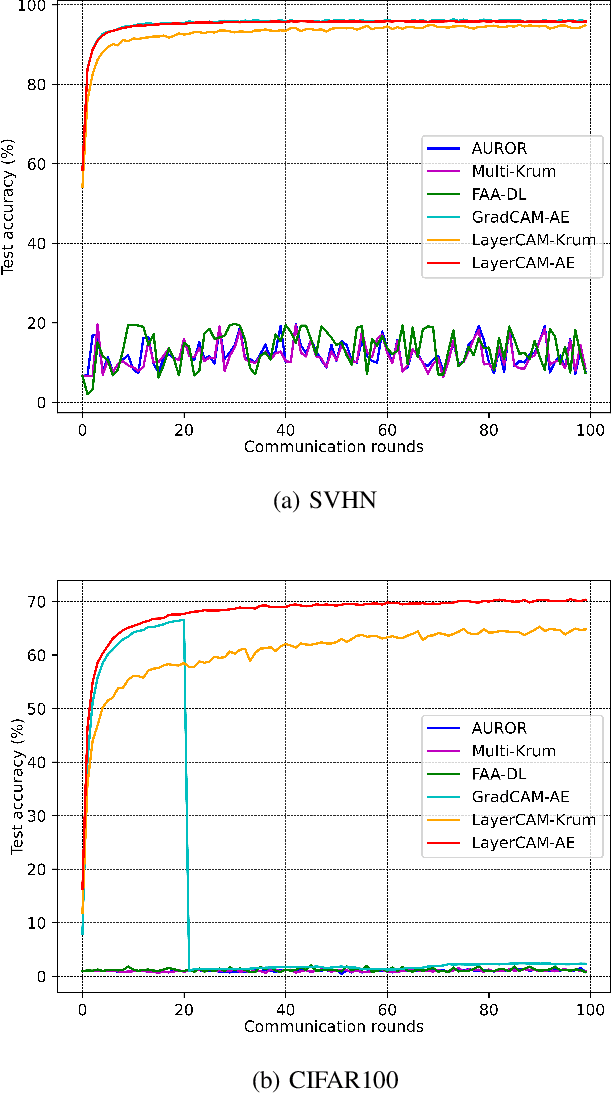
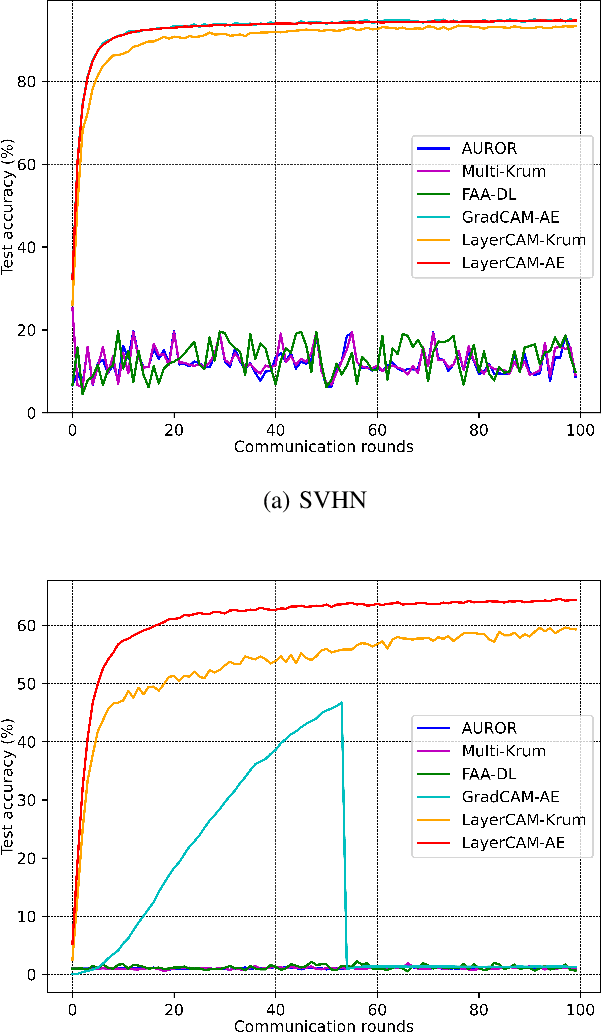
Recent attacks on federated learning (FL) can introduce malicious model updates that circumvent widely adopted Euclidean distance-based detection methods. This paper proposes a novel defense strategy, referred to as LayerCAM-AE, designed to counteract model poisoning in federated learning. The LayerCAM-AE puts forth a new Layer Class Activation Mapping (LayerCAM) integrated with an autoencoder (AE), significantly enhancing detection capabilities. Specifically, LayerCAM-AE generates a heat map for each local model update, which is then transformed into a more compact visual format. The autoencoder is designed to process the LayerCAM heat maps from the local model updates, improving their distinctiveness and thereby increasing the accuracy in spotting anomalous maps and malicious local models. To address the risk of misclassifications with LayerCAM-AE, a voting algorithm is developed, where a local model update is flagged as malicious if its heat maps are consistently suspicious over several rounds of communication. Extensive tests of LayerCAM-AE on the SVHN and CIFAR-100 datasets are performed under both Independent and Identically Distributed (IID) and non-IID settings in comparison with existing ResNet-50 and REGNETY-800MF defense models. Experimental results show that LayerCAM-AE increases detection rates (Recall: 1.0, Precision: 1.0, FPR: 0.0, Accuracy: 1.0, F1 score: 1.0, AUC: 1.0) and test accuracy in FL, surpassing the performance of both the ResNet-50 and REGNETY-800MF. Our code is available at: https://github.com/jjzgeeks/LayerCAM-AE
Leverage Variational Graph Representation For Model Poisoning on Federated Learning
Apr 24, 2024This paper puts forth a new training data-untethered model poisoning (MP) attack on federated learning (FL). The new MP attack extends an adversarial variational graph autoencoder (VGAE) to create malicious local models based solely on the benign local models overheard without any access to the training data of FL. Such an advancement leads to the VGAE-MP attack that is not only efficacious but also remains elusive to detection. VGAE-MP attack extracts graph structural correlations among the benign local models and the training data features, adversarially regenerates the graph structure, and generates malicious local models using the adversarial graph structure and benign models' features. Moreover, a new attacking algorithm is presented to train the malicious local models using VGAE and sub-gradient descent, while enabling an optimal selection of the benign local models for training the VGAE. Experiments demonstrate a gradual drop in FL accuracy under the proposed VGAE-MP attack and the ineffectiveness of existing defense mechanisms in detecting the attack, posing a severe threat to FL.
No More Ambiguity in 360° Room Layout via Bi-Layout Estimation
Apr 15, 2024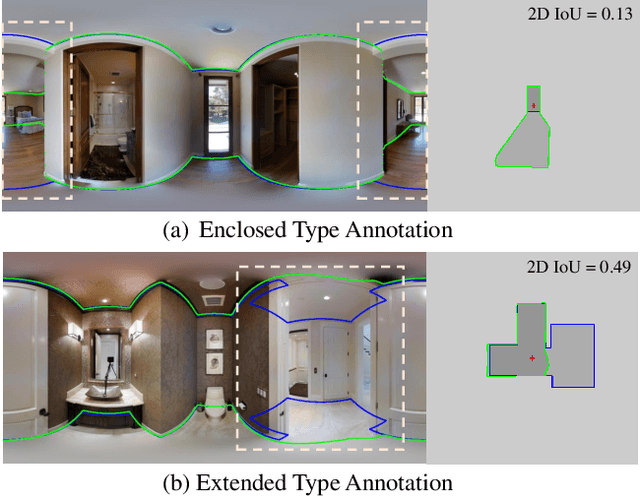
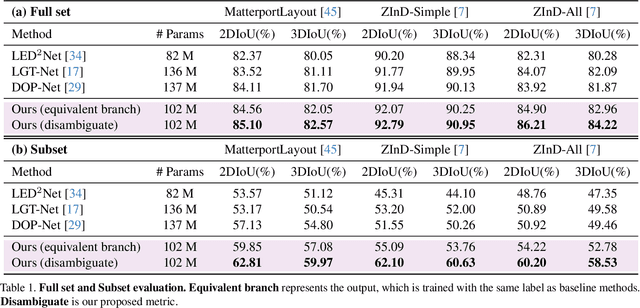
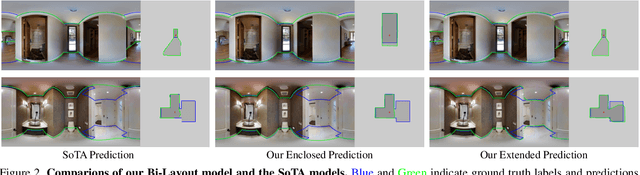
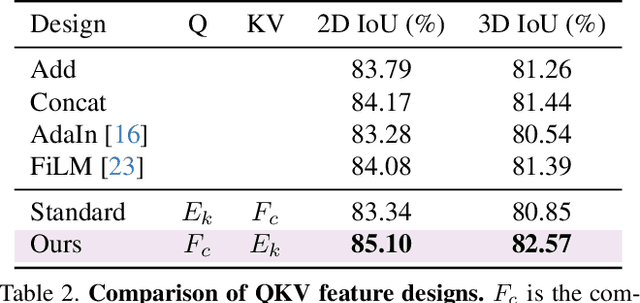
Inherent ambiguity in layout annotations poses significant challenges to developing accurate 360{\deg} room layout estimation models. To address this issue, we propose a novel Bi-Layout model capable of predicting two distinct layout types. One stops at ambiguous regions, while the other extends to encompass all visible areas. Our model employs two global context embeddings, where each embedding is designed to capture specific contextual information for each layout type. With our novel feature guidance module, the image feature retrieves relevant context from these embeddings, generating layout-aware features for precise bi-layout predictions. A unique property of our Bi-Layout model is its ability to inherently detect ambiguous regions by comparing the two predictions. To circumvent the need for manual correction of ambiguous annotations during testing, we also introduce a new metric for disambiguating ground truth layouts. Our method demonstrates superior performance on benchmark datasets, notably outperforming leading approaches. Specifically, on the MatterportLayout dataset, it improves 3DIoU from 81.70% to 82.57% across the full test set and notably from 54.80% to 59.97% in subsets with significant ambiguity. Project page: https://liagm.github.io/Bi_Layout/
Data-Agnostic Model Poisoning against Federated Learning: A Graph Autoencoder Approach
Nov 30, 2023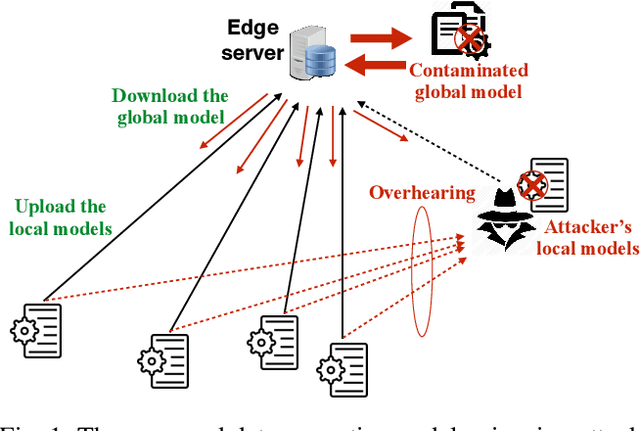
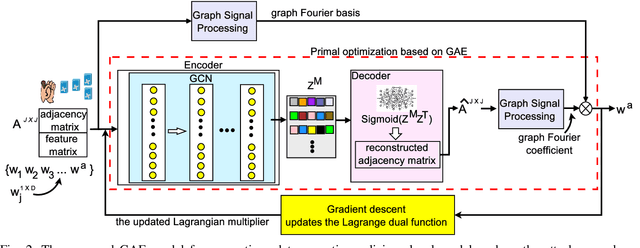
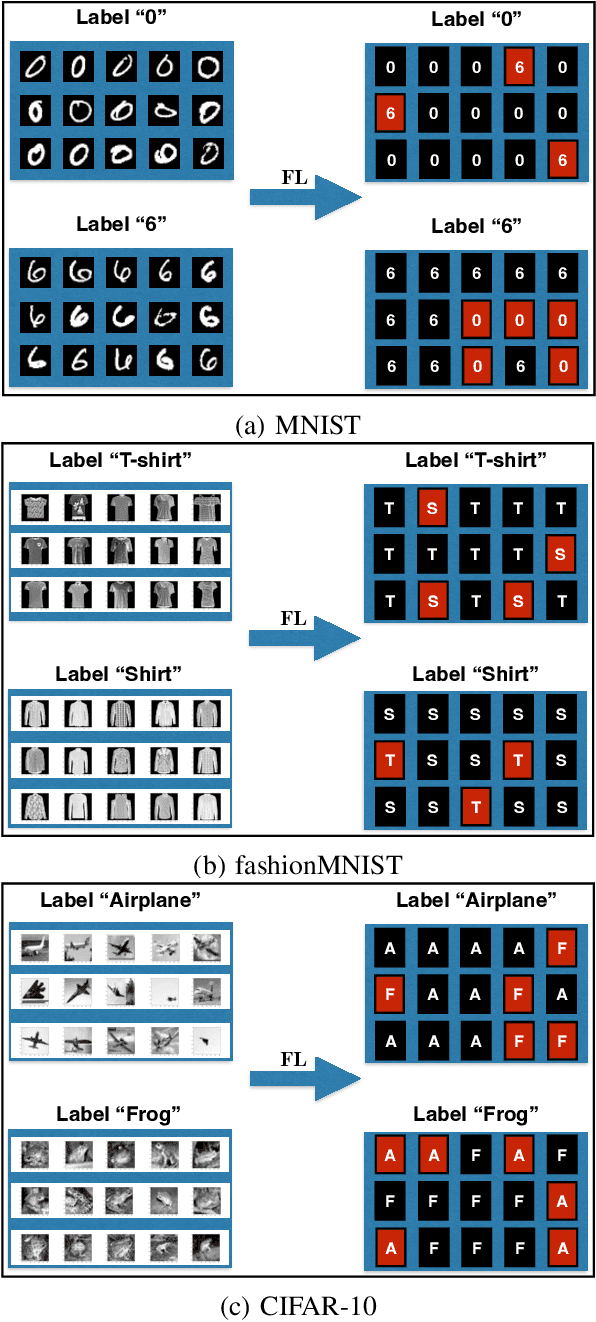
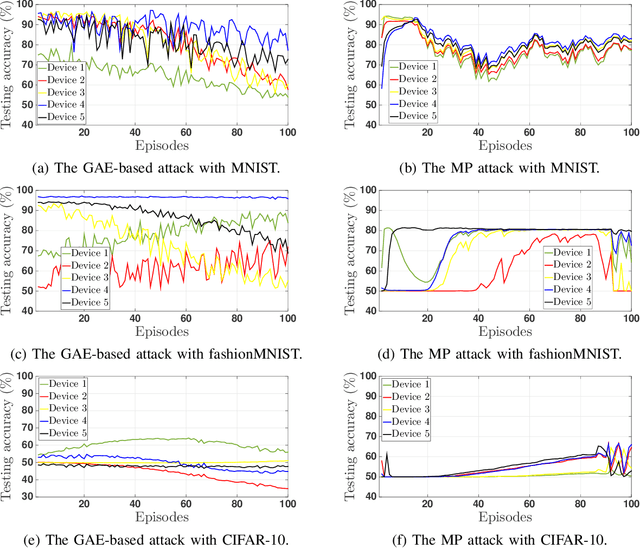
This paper proposes a novel, data-agnostic, model poisoning attack on Federated Learning (FL), by designing a new adversarial graph autoencoder (GAE)-based framework. The attack requires no knowledge of FL training data and achieves both effectiveness and undetectability. By listening to the benign local models and the global model, the attacker extracts the graph structural correlations among the benign local models and the training data features substantiating the models. The attacker then adversarially regenerates the graph structural correlations while maximizing the FL training loss, and subsequently generates malicious local models using the adversarial graph structure and the training data features of the benign ones. A new algorithm is designed to iteratively train the malicious local models using GAE and sub-gradient descent. The convergence of FL under attack is rigorously proved, with a considerably large optimality gap. Experiments show that the FL accuracy drops gradually under the proposed attack and existing defense mechanisms fail to detect it. The attack can give rise to an infection across all benign devices, making it a serious threat to FL.
High-Order Tensor Recovery with A Tensor $U_1$ Norm
Nov 23, 2023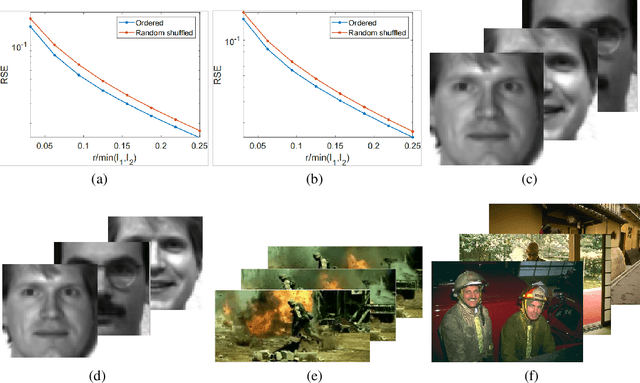


Recently, numerous tensor SVD (t-SVD)-based tensor recovery methods have emerged, showing promise in processing visual data. However, these methods often suffer from performance degradation when confronted with high-order tensor data exhibiting non-smooth changes, commonly observed in real-world scenarios but ignored by the traditional t-SVD-based methods. Our objective in this study is to provide an effective tensor recovery technique for handling non-smooth changes in tensor data and efficiently explore the correlations of high-order tensor data across its various dimensions without introducing numerous variables and weights. To this end, we introduce a new tensor decomposition and a new tensor norm called the Tensor $U_1$ norm. We utilize these novel techniques in solving the problem of high-order tensor completion problem and provide theoretical guarantees for the exact recovery of the resulting tensor completion models. An optimization algorithm is proposed to solve the resulting tensor completion model iteratively by combining the proximal algorithm with the Alternating Direction Method of Multipliers. Theoretical analysis showed the convergence of the algorithm to the Karush-Kuhn-Tucker (KKT) point of the optimization problem. Numerical experiments demonstrated the effectiveness of the proposed method in high-order tensor completion, especially for tensor data with non-smooth changes.
A Novel Tensor Factorization-Based Method with Robustness to Inaccurate Rank Estimation
May 19, 2023



This study aims to solve the over-reliance on the rank estimation strategy in the standard tensor factorization-based tensor recovery and the problem of a large computational cost in the standard t-SVD-based tensor recovery. To this end, we proposes a new tensor norm with a dual low-rank constraint, which utilizes the low-rank prior and rank information at the same time. In the proposed tensor norm, a series of surrogate functions of the tensor tubal rank can be used to achieve better performance in harness low-rankness within tensor data. It is proven theoretically that the resulting tensor completion model can effectively avoid performance degradation caused by inaccurate rank estimation. Meanwhile, attributed to the proposed dual low-rank constraint, the t-SVD of a smaller tensor instead of the original big one is computed by using a sample trick. Based on this, the total cost at each iteration of the optimization algorithm is reduced to $\mathcal{O}(n^3\log n +kn^3)$ from $\mathcal{O}(n^4)$ achieved with standard methods, where $k$ is the estimation of the true tensor rank and far less than $n$. Our method was evaluated on synthetic and real-world data, and it demonstrated superior performance and efficiency over several existing state-of-the-art tensor completion methods.
Learning Feature Decomposition for Domain Adaptive Monocular Depth Estimation
Jul 30, 2022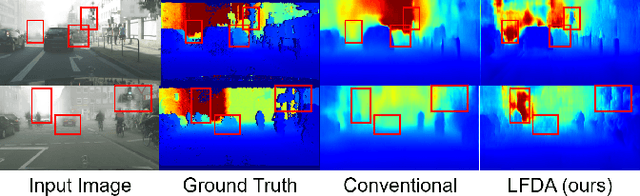
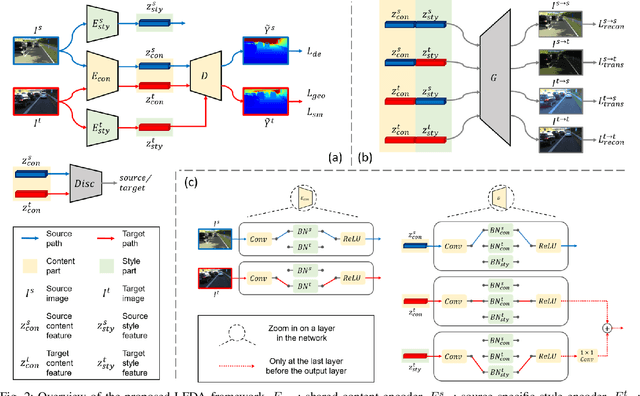

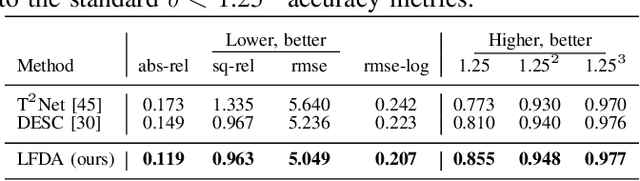
Monocular depth estimation (MDE) has attracted intense study due to its low cost and critical functions for robotic tasks such as localization, mapping and obstacle detection. Supervised approaches have led to great success with the advance of deep learning, but they rely on large quantities of ground-truth depth annotations that are expensive to acquire. Unsupervised domain adaptation (UDA) transfers knowledge from labeled source data to unlabeled target data, so as to relax the constraint of supervised learning. However, existing UDA approaches may not completely align the domain gap across different datasets because of the domain shift problem. We believe better domain alignment can be achieved via well-designed feature decomposition. In this paper, we propose a novel UDA method for MDE, referred to as Learning Feature Decomposition for Adaptation (LFDA), which learns to decompose the feature space into content and style components. LFDA only attempts to align the content component since it has a smaller domain gap. Meanwhile, it excludes the style component which is specific to the source domain from training the primary task. Furthermore, LFDA uses separate feature distribution estimations to further bridge the domain gap. Extensive experiments on three domain adaptative MDE scenarios show that the proposed method achieves superior accuracy and lower computational cost compared to the state-of-the-art approaches.