 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn Catastrophic Forgetting in Low-Rank Decomposition-Based Parameter-Efficient Fine-Tuning
Mar 10, 2026Parameter-efficient fine-tuning (PEFT) based on low-rank decomposition, such as LoRA, has become a standard for adapting large pretrained models. However, its behavior in sequential learning -- specifically regarding catastrophic forgetting -- remains insufficiently understood. In this work, we present an empirical study showing that forgetting is strongly influenced by the geometry and parameterization of the update subspace. While methods that restrict updates to small, shared matrix subspaces often suffer from task interference, tensor-based decompositions (e.g., LoRETTA) mitigate forgetting by capturing richer structural information within ultra-compact budgets, and structurally aligned parameterizations (e.g., WeGeFT) preserve pretrained representations. Our findings highlight update subspace design as a key factor in continual learning and offer practical guidance for selecting efficient adaptation strategies in sequential settings.
Adaptive Principal Components Allocation with the $\ell_{2,g}$-regularized Gaussian Graphical Model for Efficient Fine-Tuning Large Models
Dec 11, 2024


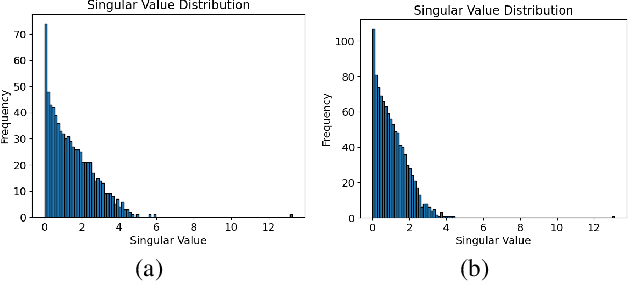
In this work, we propose a novel Parameter-Efficient Fine-Tuning (PEFT) approach based on Gaussian Graphical Models (GGMs), marking the first application of GGMs to PEFT tasks, to the best of our knowledge. The proposed method utilizes the $\ell_{2,g}$-norm to effectively select critical parameters and capture global dependencies. The resulting non-convex optimization problem is efficiently solved using a Block Coordinate Descent (BCD) algorithm. Experimental results on the GLUE benchmark [24] for fine-tuning RoBERTa-Base [18] demonstrate the effectiveness of the proposed approach, achieving competitive performance with significantly fewer trainable parameters. The code for this work is available at: https://github.com/jzheng20/Course projects.git.
Can a Single Tree Outperform an Entire Forest?
Nov 26, 2024



The prevailing mindset is that a single decision tree underperforms classic random forests in testing accuracy, despite its advantages in interpretability and lightweight structure. This study challenges such a mindset by significantly improving the testing accuracy of an oblique regression tree through our gradient-based entire tree optimization framework, making its performance comparable to the classic random forest. Our approach reformulates tree training as a differentiable unconstrained optimization task, employing a scaled sigmoid approximation strategy. To ameliorate numerical instability, we propose an algorithmic scheme that solves a sequence of increasingly accurate approximations. Additionally, a subtree polish strategy is implemented to reduce approximation errors accumulated across the tree. Extensive experiments on 16 datasets demonstrate that our optimized tree outperforms the classic random forest by an average of $2.03\%$ improvements in testing accuracy.
Causality-inspired Latent Feature Augmentation for Single Domain Generalization
Jun 10, 2024Single domain generalization (Single-DG) intends to develop a generalizable model with only one single training domain to perform well on other unknown target domains. Under the domain-hungry configuration, how to expand the coverage of source domain and find intrinsic causal features across different distributions is the key to enhancing the models' generalization ability. Existing methods mainly depend on the meticulous design of finite image-level transformation techniques and learning invariant features across domains based on statistical correlation between samples and labels in source domain. This makes it difficult to capture stable semantics between source and target domains, which hinders the improvement of the model's generalization performance. In this paper, we propose a novel causality-inspired latent feature augmentation method for Single-DG by learning the meta-knowledge of feature-level transformation based on causal learning and interventions. Instead of strongly relying on the finite image-level transformation, with the learned meta-knowledge, we can generate diverse implicit feature-level transformations in latent space based on the consistency of causal features and diversity of non-causal features, which can better compensate for the domain-hungry defect and reduce the strong reliance on initial finite image-level transformations and capture more stable domain-invariant causal features for generalization. Extensive experiments on several open-access benchmarks demonstrate the outstanding performance of our model over other state-of-the-art single domain generalization and also multi-source domain generalization methods.
High-Order Tensor Recovery with A Tensor $U_1$ Norm
Nov 23, 2023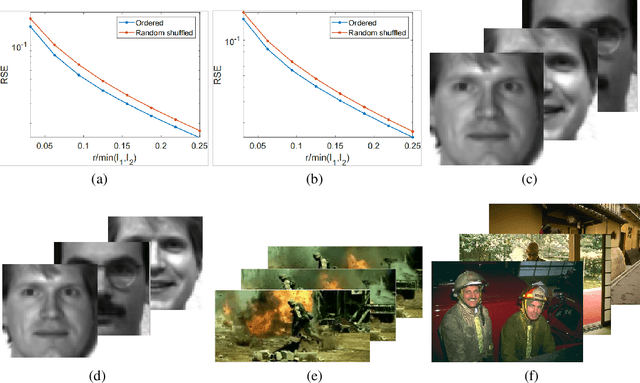


Recently, numerous tensor SVD (t-SVD)-based tensor recovery methods have emerged, showing promise in processing visual data. However, these methods often suffer from performance degradation when confronted with high-order tensor data exhibiting non-smooth changes, commonly observed in real-world scenarios but ignored by the traditional t-SVD-based methods. Our objective in this study is to provide an effective tensor recovery technique for handling non-smooth changes in tensor data and efficiently explore the correlations of high-order tensor data across its various dimensions without introducing numerous variables and weights. To this end, we introduce a new tensor decomposition and a new tensor norm called the Tensor $U_1$ norm. We utilize these novel techniques in solving the problem of high-order tensor completion problem and provide theoretical guarantees for the exact recovery of the resulting tensor completion models. An optimization algorithm is proposed to solve the resulting tensor completion model iteratively by combining the proximal algorithm with the Alternating Direction Method of Multipliers. Theoretical analysis showed the convergence of the algorithm to the Karush-Kuhn-Tucker (KKT) point of the optimization problem. Numerical experiments demonstrated the effectiveness of the proposed method in high-order tensor completion, especially for tensor data with non-smooth changes.
A GPU-Accelerated Moving-Horizon Algorithm for Training Deep Classification Trees on Large Datasets
Nov 12, 2023



Decision trees are essential yet NP-complete to train, prompting the widespread use of heuristic methods such as CART, which suffers from sub-optimal performance due to its greedy nature. Recently, breakthroughs in finding optimal decision trees have emerged; however, these methods still face significant computational costs and struggle with continuous features in large-scale datasets and deep trees. To address these limitations, we introduce a moving-horizon differential evolution algorithm for classification trees with continuous features (MH-DEOCT). Our approach consists of a discrete tree decoding method that eliminates duplicated searches between adjacent samples, a GPU-accelerated implementation that significantly reduces running time, and a moving-horizon strategy that iteratively trains shallow subtrees at each node to balance the vision and optimizer capability. Comprehensive studies on 68 UCI datasets demonstrate that our approach outperforms the heuristic method CART on training and testing accuracy by an average of 3.44% and 1.71%, respectively. Moreover, these numerical studies empirically demonstrate that MH-DEOCT achieves near-optimal performance (only 0.38% and 0.06% worse than the global optimal method on training and testing, respectively), while it offers remarkable scalability for deep trees (e.g., depth=8) and large-scale datasets (e.g., ten million samples).
A Global Optimization Algorithm for K-Center Clustering of One Billion Samples
Dec 30, 2022This paper presents a practical global optimization algorithm for the K-center clustering problem, which aims to select K samples as the cluster centers to minimize the maximum within-cluster distance. This algorithm is based on a reduced-space branch and bound scheme and guarantees convergence to the global optimum in a finite number of steps by only branching on the regions of centers. To improve efficiency, we have designed a two-stage decomposable lower bound, the solution of which can be derived in a closed form. In addition, we also propose several acceleration techniques to narrow down the region of centers, including bounds tightening, sample reduction, and parallelization. Extensive studies on synthetic and real-world datasets have demonstrated that our algorithm can solve the K-center problems to global optimal within 4 hours for ten million samples in the serial mode and one billion samples in the parallel mode. Moreover, compared with the state-of-the-art heuristic methods, the global optimum obtained by our algorithm can averagely reduce the objective function by 25.8% on all the synthetic and real-world datasets.