 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCausality-inspired Latent Feature Augmentation for Single Domain Generalization
Jun 10, 2024Single domain generalization (Single-DG) intends to develop a generalizable model with only one single training domain to perform well on other unknown target domains. Under the domain-hungry configuration, how to expand the coverage of source domain and find intrinsic causal features across different distributions is the key to enhancing the models' generalization ability. Existing methods mainly depend on the meticulous design of finite image-level transformation techniques and learning invariant features across domains based on statistical correlation between samples and labels in source domain. This makes it difficult to capture stable semantics between source and target domains, which hinders the improvement of the model's generalization performance. In this paper, we propose a novel causality-inspired latent feature augmentation method for Single-DG by learning the meta-knowledge of feature-level transformation based on causal learning and interventions. Instead of strongly relying on the finite image-level transformation, with the learned meta-knowledge, we can generate diverse implicit feature-level transformations in latent space based on the consistency of causal features and diversity of non-causal features, which can better compensate for the domain-hungry defect and reduce the strong reliance on initial finite image-level transformations and capture more stable domain-invariant causal features for generalization. Extensive experiments on several open-access benchmarks demonstrate the outstanding performance of our model over other state-of-the-art single domain generalization and also multi-source domain generalization methods.
REFRAME: Reflective Surface Real-Time Rendering for Mobile Devices
Mar 25, 2024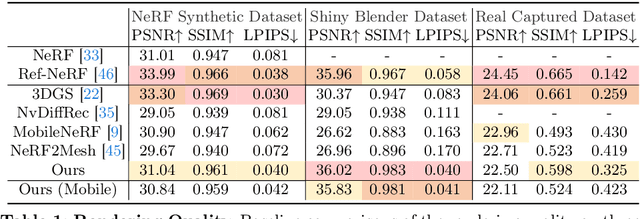
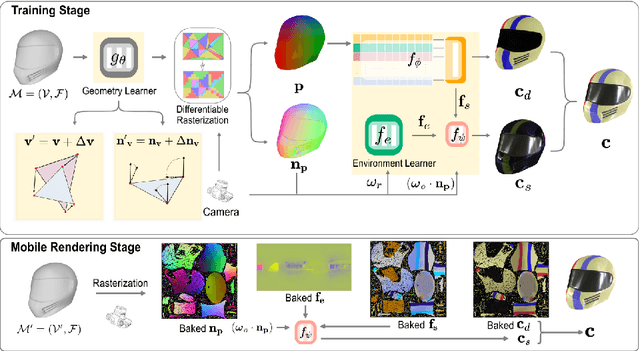


This work tackles the challenging task of achieving real-time novel view synthesis on various scenes, including highly reflective objects and unbounded outdoor scenes. Existing real-time rendering methods, especially those based on meshes, often have subpar performance in modeling surfaces with rich view-dependent appearances. Our key idea lies in leveraging meshes for rendering acceleration while incorporating a novel approach to parameterize view-dependent information. We decompose the color into diffuse and specular, and model the specular color in the reflected direction based on a neural environment map. Our experiments demonstrate that our method achieves comparable reconstruction quality for highly reflective surfaces compared to state-of-the-art offline methods, while also efficiently enabling real-time rendering on edge devices such as smartphones.
A GPU-Accelerated Moving-Horizon Algorithm for Training Deep Classification Trees on Large Datasets
Nov 12, 2023



Decision trees are essential yet NP-complete to train, prompting the widespread use of heuristic methods such as CART, which suffers from sub-optimal performance due to its greedy nature. Recently, breakthroughs in finding optimal decision trees have emerged; however, these methods still face significant computational costs and struggle with continuous features in large-scale datasets and deep trees. To address these limitations, we introduce a moving-horizon differential evolution algorithm for classification trees with continuous features (MH-DEOCT). Our approach consists of a discrete tree decoding method that eliminates duplicated searches between adjacent samples, a GPU-accelerated implementation that significantly reduces running time, and a moving-horizon strategy that iteratively trains shallow subtrees at each node to balance the vision and optimizer capability. Comprehensive studies on 68 UCI datasets demonstrate that our approach outperforms the heuristic method CART on training and testing accuracy by an average of 3.44% and 1.71%, respectively. Moreover, these numerical studies empirically demonstrate that MH-DEOCT achieves near-optimal performance (only 0.38% and 0.06% worse than the global optimal method on training and testing, respectively), while it offers remarkable scalability for deep trees (e.g., depth=8) and large-scale datasets (e.g., ten million samples).
A Global Optimization Algorithm for K-Center Clustering of One Billion Samples
Dec 30, 2022This paper presents a practical global optimization algorithm for the K-center clustering problem, which aims to select K samples as the cluster centers to minimize the maximum within-cluster distance. This algorithm is based on a reduced-space branch and bound scheme and guarantees convergence to the global optimum in a finite number of steps by only branching on the regions of centers. To improve efficiency, we have designed a two-stage decomposable lower bound, the solution of which can be derived in a closed form. In addition, we also propose several acceleration techniques to narrow down the region of centers, including bounds tightening, sample reduction, and parallelization. Extensive studies on synthetic and real-world datasets have demonstrated that our algorithm can solve the K-center problems to global optimal within 4 hours for ten million samples in the serial mode and one billion samples in the parallel mode. Moreover, compared with the state-of-the-art heuristic methods, the global optimum obtained by our algorithm can averagely reduce the objective function by 25.8% on all the synthetic and real-world datasets.
Smoothness Sensor: Adaptive Smoothness-Transition Graph Convolutions for Attributed Graph Clustering
Sep 12, 2020Clustering techniques attempt to group objects with similar properties into a cluster. Clustering the nodes of an attributed graph, in which each node is associated with a set of feature attributes, has attracted significant attention. Graph convolutional networks (GCNs) represent an effective approach for integrating the two complementary factors of node attributes and structural information for attributed graph clustering. However, oversmoothing of GCNs produces indistinguishable representations of nodes, such that the nodes in a graph tend to be grouped into fewer clusters, and poses a challenge due to the resulting performance drop. In this study, we propose a smoothness sensor for attributed graph clustering based on adaptive smoothness-transition graph convolutions, which senses the smoothness of a graph and adaptively terminates the current convolution once the smoothness is saturated to prevent oversmoothing. Furthermore, as an alternative to graph-level smoothness, a novel fine-gained node-wise level assessment of smoothness is proposed, in which smoothness is computed in accordance with the neighborhood conditions of a given node at a certain order of graph convolution. In addition, a self-supervision criterion is designed considering both the tightness within clusters and the separation between clusters to guide the whole neural network training process. Experiments show that the proposed methods significantly outperform 12 other state-of-the-art baselines in terms of three different metrics across four benchmark datasets. In addition, an extensive study reveals the reasons for their effectiveness and efficiency.
Graph Polish: A Novel Graph Generation Paradigm for Molecular Optimization
Aug 14, 2020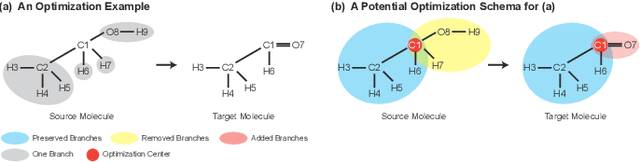
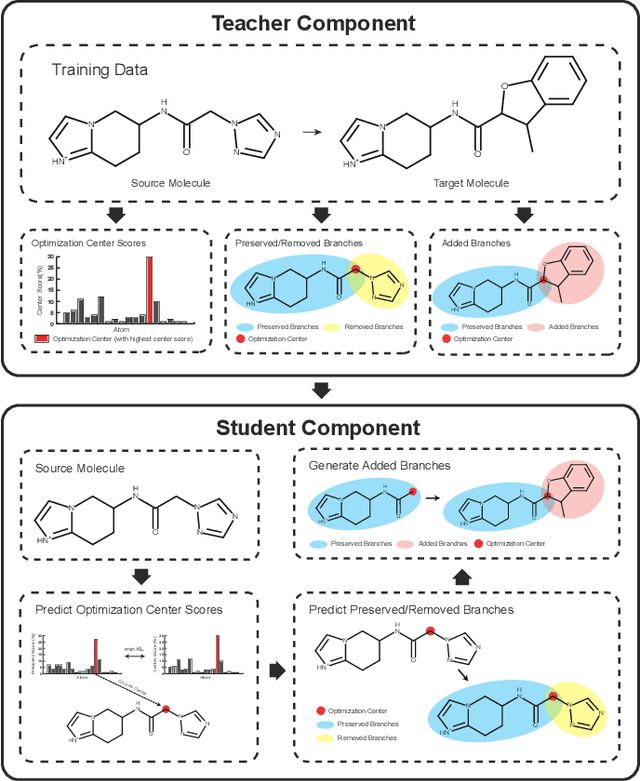
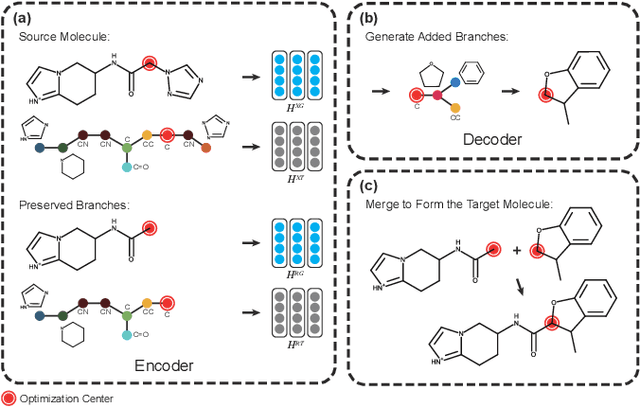
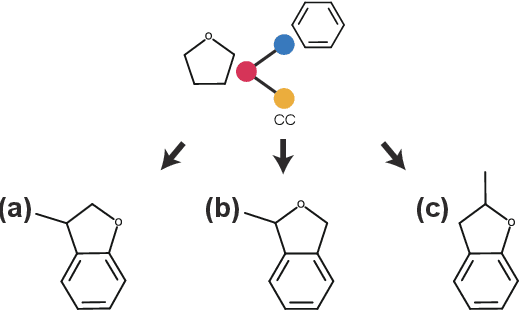
Molecular optimization, which transforms a given input molecule X into another Y with desirable properties, is essential in molecular drug discovery. The traditional translating approaches, generating the molecular graphs from scratch by adding some substructures piece by piece, prone to error because of the large set of candidate substructures in a large number of steps to the final target. In this study, we present a novel molecular optimization paradigm, Graph Polish, which changes molecular optimization from the traditional "two-language translating" task into a "single-language polishing" task. The key to this optimization paradigm is to find an optimization center subject to the conditions that the preserved areas around it ought to be maximized and thereafter the removed and added regions should be minimized. We then propose an effective and efficient learning framework T&S polish to capture the long-term dependencies in the optimization steps. The T component automatically identifies and annotates the optimization centers and the preservation, removal and addition of some parts of the molecule, and the S component learns these behaviors and applies these actions to a new molecule. Furthermore, the proposed paradigm can offer an intuitive interpretation for each molecular optimization result. Experiments with multiple optimization tasks are conducted on four benchmark datasets. The proposed T&S polish approach achieves significant advantage over the five state-of-the-art baseline methods on all the tasks. In addition, extensive studies are conducted to validate the effectiveness, explainability and time saving of the novel optimization paradigm.
Boundary-aware Context Neural Network for Medical Image Segmentation
May 03, 2020
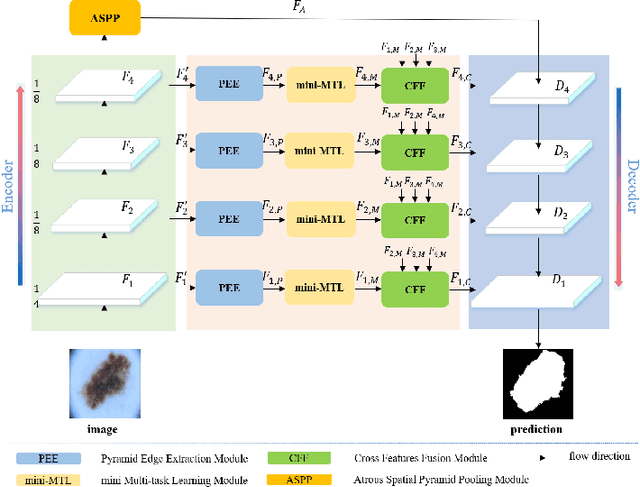
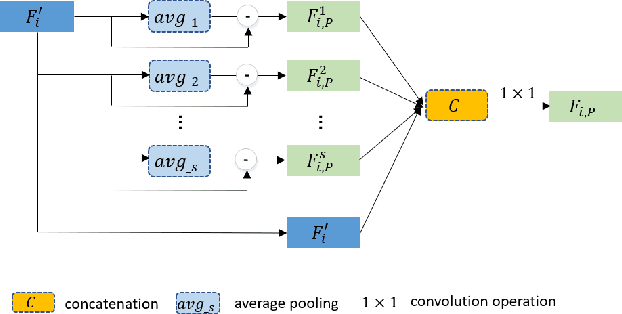
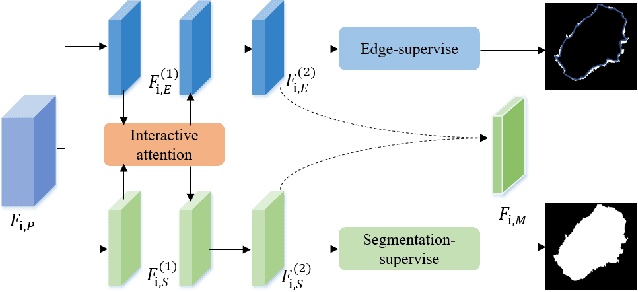
Medical image segmentation can provide a reliable basis for further clinical analysis and disease diagnosis. The performance of medical image segmentation has been significantly advanced with the convolutional neural networks (CNNs). However, most existing CNNs-based methods often produce unsatisfactory segmentation mask without accurate object boundaries. This is caused by the limited context information and inadequate discriminative feature maps after consecutive pooling and convolution operations. In that the medical image is characterized by the high intra-class variation, inter-class indistinction and noise, extracting powerful context and aggregating discriminative features for fine-grained segmentation are still challenging today. In this paper, we formulate a boundary-aware context neural network (BA-Net) for 2D medical image segmentation to capture richer context and preserve fine spatial information. BA-Net adopts encoder-decoder architecture. In each stage of encoder network, pyramid edge extraction module is proposed for obtaining edge information with multiple granularities firstly. Then we design a mini multi-task learning module for jointly learning to segment object masks and detect lesion boundaries. In particular, a new interactive attention is proposed to bridge two tasks for achieving information complementarity between different tasks, which effectively leverages the boundary information for offering a strong cue to better segmentation prediction. At last, a cross feature fusion module aims to selectively aggregate multi-level features from the whole encoder network. By cascaded three modules, richer context and fine-grain features of each stage are encoded. Extensive experiments on five datasets show that the proposed BA-Net outperforms state-of-the-art approaches.
Perturb More, Trap More: Understanding Behaviors of Graph Neural Networks
Apr 28, 2020



While graph neural networks (GNNs) have shown a great potential in various tasks on graph, the lack of transparency has hindered understanding how GNNs arrived at its predictions. Although few explainers for GNNs are explored, the consideration of local fidelity, indicating how the model behaves around an instance should be predicted, is neglected. In this paper, we first propose a novel post-hoc framework based on local fidelity for any trained GNNs - TraP2, which can generate a high-fidelity explanation. Considering that both relevant graph structure and important features inside each node need to be highlighted, a three-layer architecture in TraP2 is designed: i) interpretation domain are defined by Translation layer in advance; ii) local predictive behavior of GNNs being explained are probed and monitored by Perturbation layer, in which multiple perturbations for graph structure and feature-level are conducted in interpretation domain; iii) high faithful explanations are generated by fitting the local decision boundary through Paraphrase layer. Finally, TraP2 is evaluated on six benchmark datasets based on five desired attributions: accuracy, fidelity, decisiveness, insight and inspiration, which achieves $10.2\%$ higher explanation accuracy than the state-of-the-art methods.
HopGAT: Hop-aware Supervision Graph Attention Networks for Sparsely Labeled Graphs
Apr 09, 2020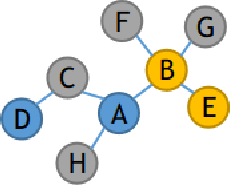

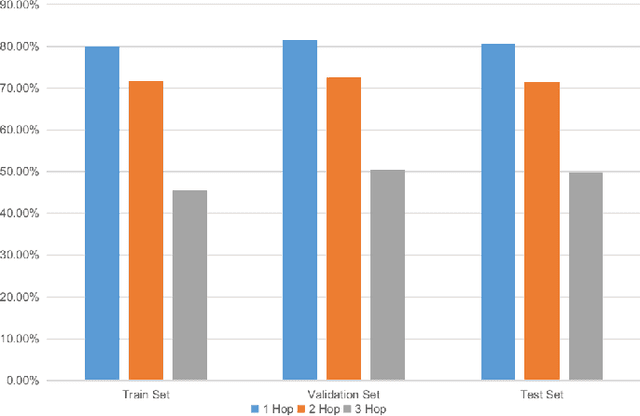

Due to the cost of labeling nodes, classifying a node in a sparsely labeled graph while maintaining the prediction accuracy deserves attention. The key point is how the algorithm learns sufficient information from more neighbors with different hop distances. This study first proposes a hop-aware attention supervision mechanism for the node classification task. A simulated annealing learning strategy is then adopted to balance two learning tasks, node classification and the hop-aware attention coefficients, along the training timeline. Compared with state-of-the-art models, the experimental results proved the superior effectiveness of the proposed Hop-aware Supervision Graph Attention Networks (HopGAT) model. Especially, for the protein-protein interaction network, in a 40% labeled graph, the performance loss is only 3.9%, from 98.5% to 94.6%, compared to the fully labeled graph. Extensive experiments also demonstrate the effectiveness of supervised attention coefficient and learning strategies.