 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCLASS: Enhancing Cross-Modal Text-Molecule Retrieval Performance and Training Efficiency
Feb 17, 2025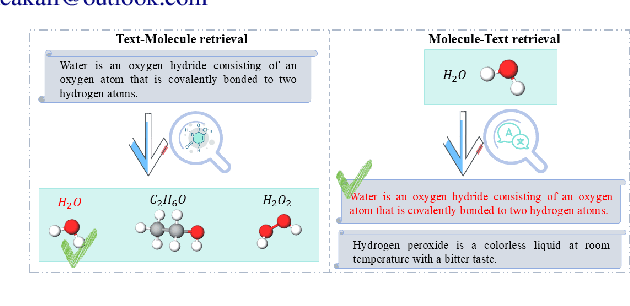
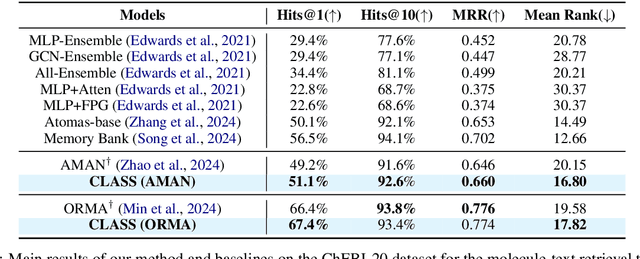
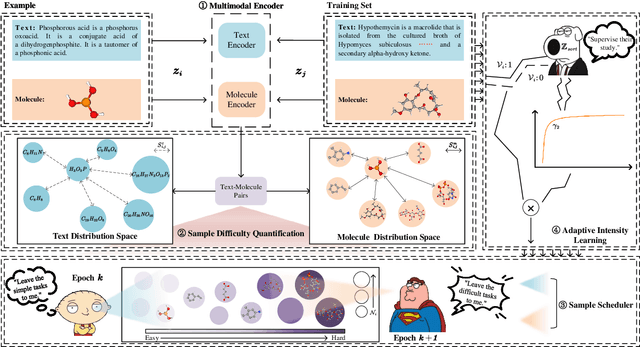
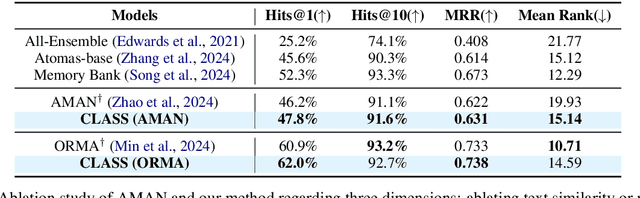
Cross-modal text-molecule retrieval task bridges molecule structures and natural language descriptions. Existing methods predominantly focus on aligning text modality and molecule modality, yet they overlook adaptively adjusting the learning states at different training stages and enhancing training efficiency. To tackle these challenges, this paper proposes a Curriculum Learning-bAsed croSS-modal text-molecule training framework (CLASS), which can be integrated with any backbone to yield promising performance improvement. Specifically, we quantify the sample difficulty considering both text modality and molecule modality, and design a sample scheduler to introduce training samples via an easy-to-difficult paradigm as the training advances, remarkably reducing the scale of training samples at the early stage of training and improving training efficiency. Moreover, we introduce adaptive intensity learning to increase the training intensity as the training progresses, which adaptively controls the learning intensity across all curriculum stages. Experimental results on the ChEBI-20 dataset demonstrate that our proposed method gains superior performance, simultaneously achieving prominent time savings.
Jailbreaking? One Step Is Enough!
Dec 17, 2024



Large language models (LLMs) excel in various tasks but remain vulnerable to jailbreak attacks, where adversaries manipulate prompts to generate harmful outputs. Examining jailbreak prompts helps uncover the shortcomings of LLMs. However, current jailbreak methods and the target model's defenses are engaged in an independent and adversarial process, resulting in the need for frequent attack iterations and redesigning attacks for different models. To address these gaps, we propose a Reverse Embedded Defense Attack (REDA) mechanism that disguises the attack intention as the "defense". intention against harmful content. Specifically, REDA starts from the target response, guiding the model to embed harmful content within its defensive measures, thereby relegating harmful content to a secondary role and making the model believe it is performing a defensive task. The attacking model considers that it is guiding the target model to deal with harmful content, while the target model thinks it is performing a defensive task, creating an illusion of cooperation between the two. Additionally, to enhance the model's confidence and guidance in "defensive" intentions, we adopt in-context learning (ICL) with a small number of attack examples and construct a corresponding dataset of attack examples. Extensive evaluations demonstrate that the REDA method enables cross-model attacks without the need to redesign attack strategies for different models, enables successful jailbreak in one iteration, and outperforms existing methods on both open-source and closed-source models.
HateDebias: On the Diversity and Variability of Hate Speech Debiasing
Jun 07, 2024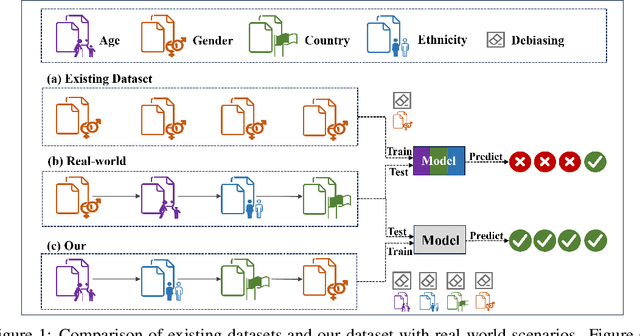



Hate speech on social media is ubiquitous but urgently controlled. Without detecting and mitigating the biases brought by hate speech, different types of ethical problems. While a number of datasets have been proposed to address the problem of hate speech detection, these datasets seldom consider the diversity and variability of bias, making it far from real-world scenarios. To fill this gap, we propose a benchmark, named HateDebias, to analyze the model ability of hate speech detection under continuous, changing environments. Specifically, to meet the diversity of biases, we collect existing hate speech detection datasets with different types of biases. To further meet the variability (i.e., the changing of bias attributes in datasets), we reorganize datasets to follow the continuous learning setting. We evaluate the detection accuracy of models trained on the datasets with a single type of bias with the performance on the HateDebias, where a significant performance drop is observed. To provide a potential direction for debiasing, we further propose a debiasing framework based on continuous learning and bias information regularization, as well as the memory replay strategies to ensure the debiasing ability of the model. Experiment results on the proposed benchmark show that the aforementioned method can improve several baselines with a distinguished margin, highlighting its effectiveness in real-world applications.
Learn to Disguise: Avoid Refusal Responses in LLM's Defense via a Multi-agent Attacker-Disguiser Game
Apr 03, 2024



With the enhanced performance of large models on natural language processing tasks, potential moral and ethical issues of large models arise. There exist malicious attackers who induce large models to jailbreak and generate information containing illegal, privacy-invasive information through techniques such as prompt engineering. As a result, large models counter malicious attackers' attacks using techniques such as safety alignment. However, the strong defense mechanism of the large model through rejection replies is easily identified by attackers and used to strengthen attackers' capabilities. In this paper, we propose a multi-agent attacker-disguiser game approach to achieve a weak defense mechanism that allows the large model to both safely reply to the attacker and hide the defense intent. First, we construct a multi-agent framework to simulate attack and defense scenarios, playing different roles to be responsible for attack, disguise, safety evaluation, and disguise evaluation tasks. After that, we design attack and disguise game algorithms to optimize the game strategies of the attacker and the disguiser and use the curriculum learning process to strengthen the capabilities of the agents. The experiments verify that the method in this paper is more effective in strengthening the model's ability to disguise the defense intent compared with other methods. Moreover, our approach can adapt any black-box large model to assist the model in defense and does not suffer from model version iterations.
CEL: A Continual Learning Model for Disease Outbreak Prediction by Leveraging Domain Adaptation via Elastic Weight Consolidation
Jan 17, 2024Continual learning, the ability of a model to learn over time without forgetting previous knowledge and, therefore, be adaptive to new data, is paramount in dynamic fields such as disease outbreak prediction. Deep neural networks, i.e., LSTM, are prone to error due to catastrophic forgetting. This study introduces a novel CEL model for continual learning by leveraging domain adaptation via Elastic Weight Consolidation (EWC). This model aims to mitigate the catastrophic forgetting phenomenon in a domain incremental setting. The Fisher Information Matrix (FIM) is constructed with EWC to develop a regularization term that penalizes changes to important parameters, namely, the important previous knowledge. CEL's performance is evaluated on three distinct diseases, Influenza, Mpox, and Measles, with different metrics. The high R-squared values during evaluation and reevaluation outperform the other state-of-the-art models in several contexts, indicating that CEL adapts to incremental data well. CEL's robustness and reliability are underscored by its minimal 65% forgetting rate and 18% higher memory stability compared to existing benchmark studies. This study highlights CEL's versatility in disease outbreak prediction, addressing evolving data with temporal patterns. It offers a valuable model for proactive disease control with accurate, timely predictions.
Curricular Subgoals for Inverse Reinforcement Learning
Jun 14, 2023



Inverse Reinforcement Learning (IRL) aims to reconstruct the reward function from expert demonstrations to facilitate policy learning, and has demonstrated its remarkable success in imitation learning. To promote expert-like behavior, existing IRL methods mainly focus on learning global reward functions to minimize the trajectory difference between the imitator and the expert. However, these global designs are still limited by the redundant noise and error propagation problems, leading to the unsuitable reward assignment and thus downgrading the agent capability in complex multi-stage tasks. In this paper, we propose a novel Curricular Subgoal-based Inverse Reinforcement Learning (CSIRL) framework, that explicitly disentangles one task with several local subgoals to guide agent imitation. Specifically, CSIRL firstly introduces decision uncertainty of the trained agent over expert trajectories to dynamically select subgoals, which directly determines the exploration boundary of different task stages. To further acquire local reward functions for each stage, we customize a meta-imitation objective based on these curricular subgoals to train an intrinsic reward generator. Experiments on the D4RL and autonomous driving benchmarks demonstrate that the proposed methods yields results superior to the state-of-the-art counterparts, as well as better interpretability. Our code is available at https://github.com/Plankson/CSIRL.
An Analysis of the Differences Among Regional Varieties of Chinese in Malay Archipelago
Sep 10, 2022
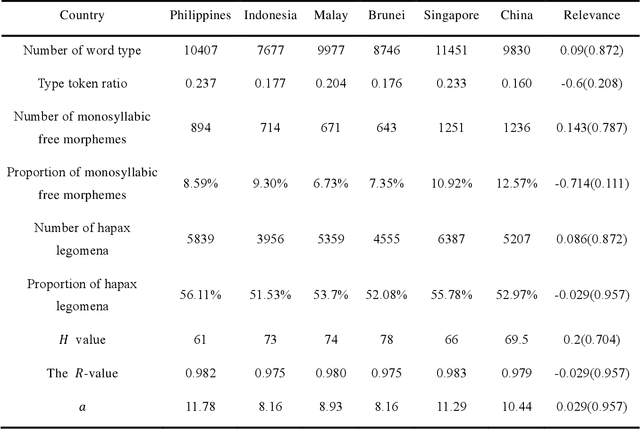
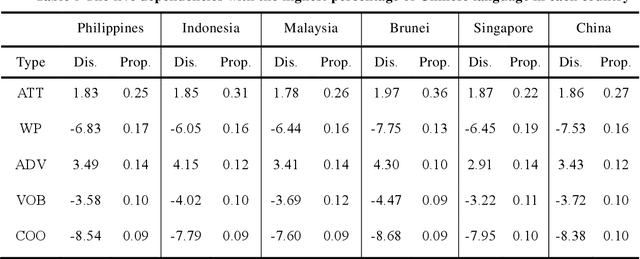
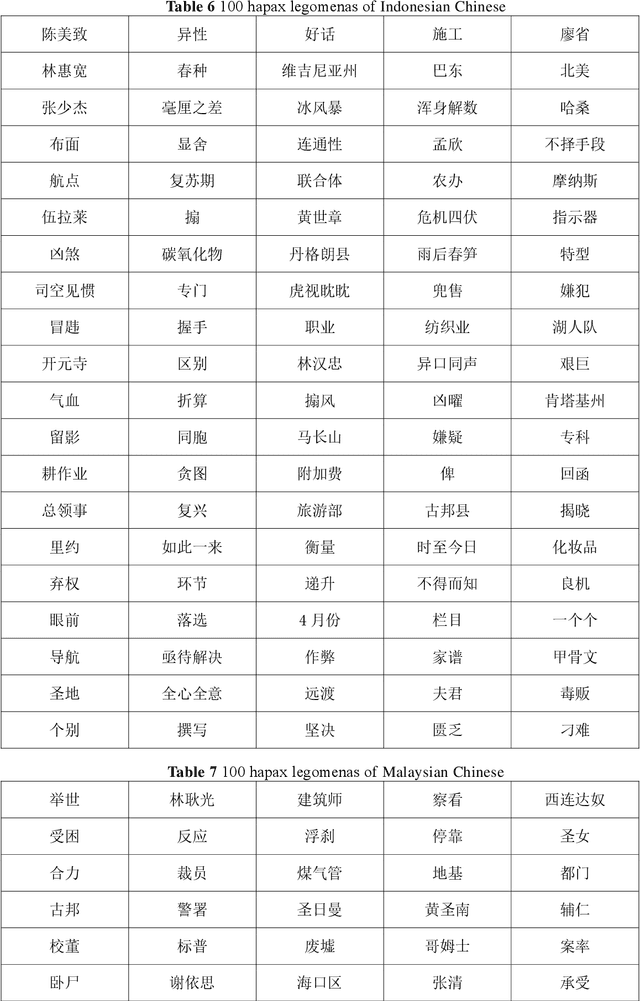
Chinese features prominently in the Chinese communities located in the nations of Malay Archipelago. In these countries, Chinese has undergone the process of adjustment to the local languages and cultures, which leads to the occurrence of a Chinese variant in each country. In this paper, we conducted a quantitative analysis on Chinese news texts collected from five Malay Archipelago nations, namely Indonesia, Malaysia, Singapore, Philippines and Brunei, trying to figure out their differences with the texts written in modern standard Chinese from a lexical and syntactic perspective. The statistical results show that the Chinese variants used in these five nations are quite different, diverging from their modern Chinese mainland counterpart. Meanwhile, we managed to extract and classify several featured Chinese words used in each nation. All these discrepancies reflect how Chinese evolves overseas, and demonstrate the profound impact rom local societies and cultures on the development of Chinese.
Spatio-Temporal Multi-step Prediction of Influenza Outbreaks
Feb 16, 2021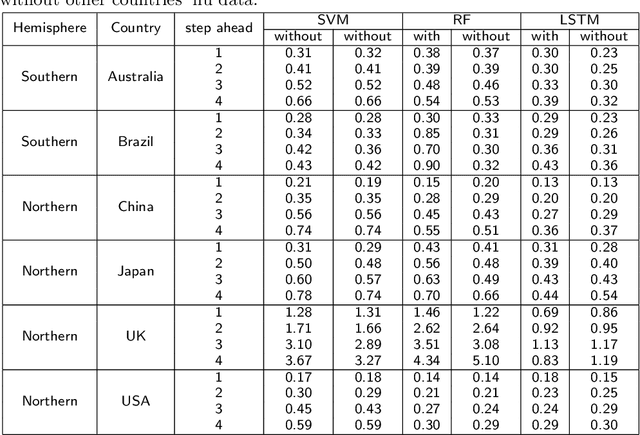
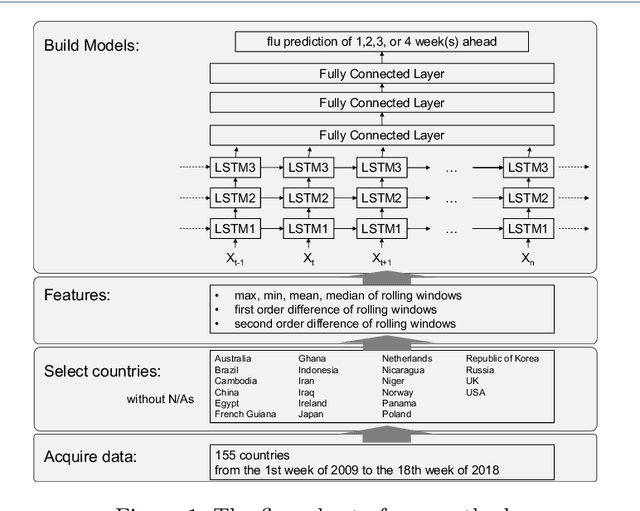

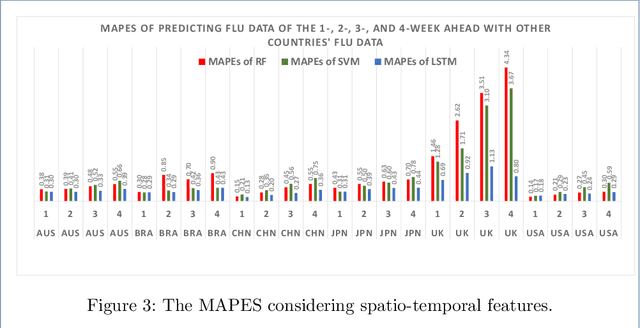
Flu circulates all over the world. The worldwide infection places a substantial burden on people's health every year. Regardless of the characteristic of the worldwide circulation of flu, most previous studies focused on regional prediction of flu outbreaks. The methodology of considering the spatio-temporal correlation could help forecast flu outbreaks more precisely. Furthermore, forecasting a long-term flu outbreak, and understanding flu infection trends more accurately could help hospitals, clinics, and pharmaceutical companies to better prepare for annual flu outbreaks. Predicting a sequence of values in the future, namely, the multi-step prediction of flu outbreaks should cause concern. Therefore, we highlight the importance of developing spatio-temporal methodologies to perform multi-step prediction of worldwide flu outbreaks. We compared the MAPEs of SVM, RF, LSTM models of predicting flu data of the 1-4 weeks ahead with and without other countries' flu data. We found the LSTM models achieved the lowest MAPEs in most cases. As for countries in the Southern hemisphere, the MAPEs of predicting flu data with other countries are higher than those of predicting without other countries. For countries in the Northern hemisphere, the MAPEs of predicting flu data of the 2-4 weeks ahead with other countries are lower than those of predicting without other countries; and the MAPEs of predicting flu data of the 1-weeks ahead with other countries are higher than those of predicting without other countries, except for the UK. In this study, we performed the spatio-temporal multi-step prediction of influenza outbreaks. The methodology considering the spatio-temporal features improves the multi-step prediction of flu outbreaks.
Dynamic Virtual Graph Significance Networks for Predicting Influenza
Feb 16, 2021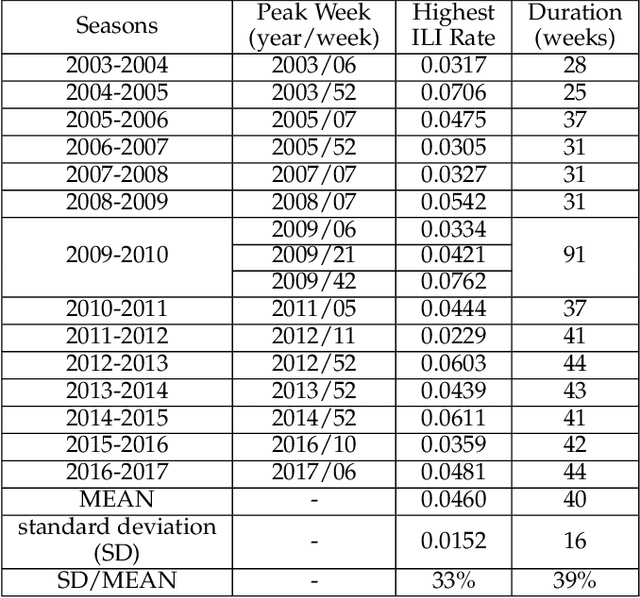
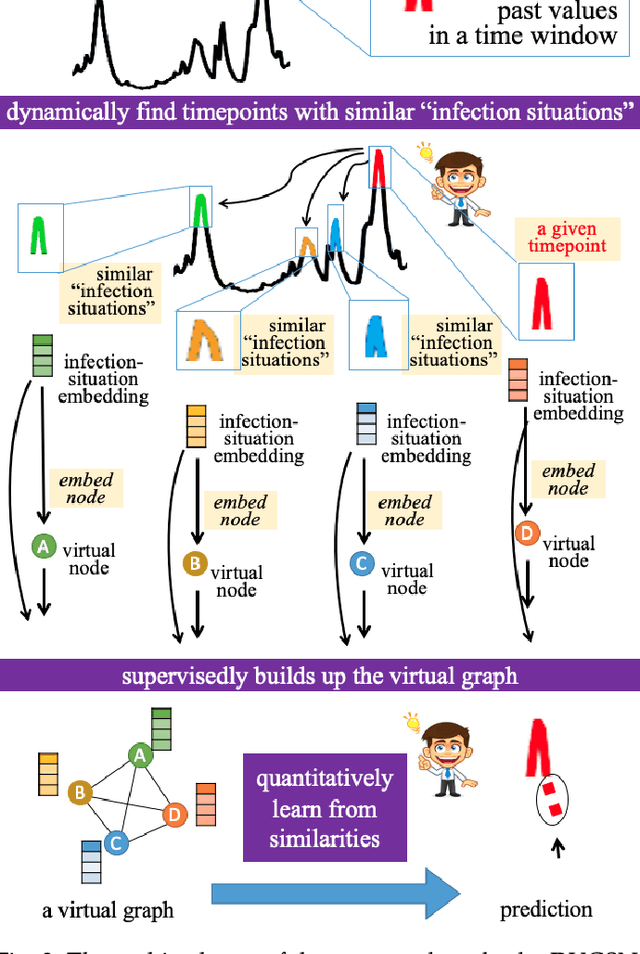

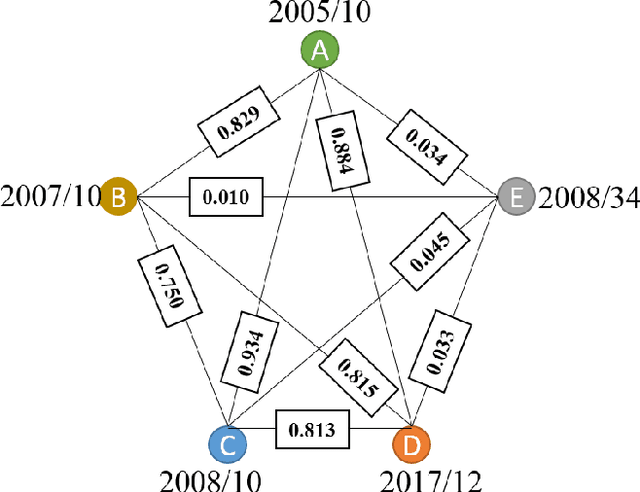
Graph-structured data and their related algorithms have attracted significant attention in many fields, such as influenza prediction in public health. However, the variable influenza seasonality, occasional pandemics, and domain knowledge pose great challenges to construct an appropriate graph, which could impair the strength of the current popular graph-based algorithms to perform data analysis. In this study, we develop a novel method, Dynamic Virtual Graph Significance Networks (DVGSN), which can supervisedly and dynamically learn from similar "infection situations" in historical timepoints. Representation learning on the dynamic virtual graph can tackle the varied seasonality and pandemics, and therefore improve the performance. The extensive experiments on real-world influenza data demonstrate that DVGSN significantly outperforms the current state-of-the-art methods. To the best of our knowledge, this is the first attempt to supervisedly learn a dynamic virtual graph for time-series prediction tasks. Moreover, the proposed method needs less domain knowledge to build a graph in advance and has rich interpretability, which makes the method more acceptable in the fields of public health, life sciences, and so on.
Meta-Path-Free Representation Learning on Heterogeneous Networks
Feb 16, 2021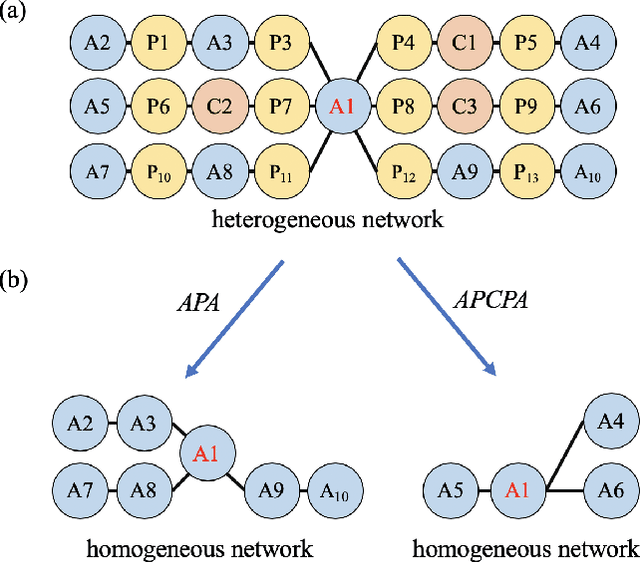
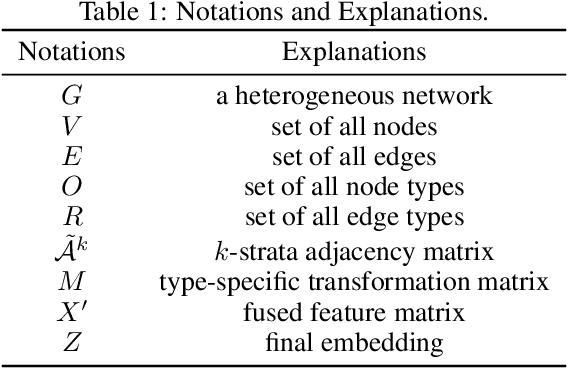
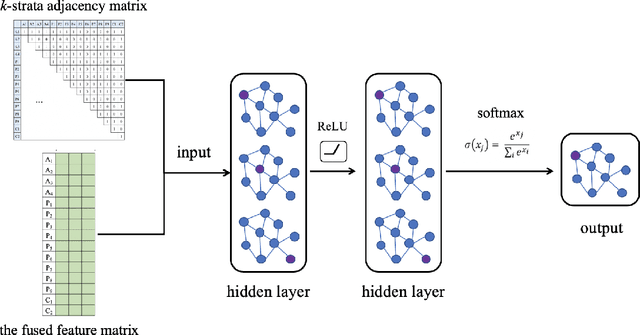
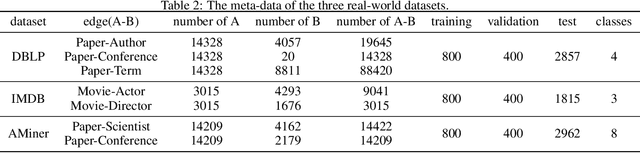
Real-world networks and knowledge graphs are usually heterogeneous networks. Representation learning on heterogeneous networks is not only a popular but a pragmatic research field. The main challenge comes from the heterogeneity -- the diverse types of nodes and edges. Besides, for a given node in a HIN, the significance of a neighborhood node depends not only on the structural distance but semantics. How to effectively capture both structural and semantic relations is another challenge. The current state-of-the-art methods are based on the algorithm of meta-path and therefore have a serious disadvantage -- the performance depends on the arbitrary choosing of meta-path(s). However, the selection of meta-path(s) is experience-based and time-consuming. In this work, we propose a novel meta-path-free representation learning on heterogeneous networks, namely Heterogeneous graph Convolutional Networks (HCN). The proposed method fuses the heterogeneity and develops a $k$-strata algorithm ($k$ is an integer) to capture the $k$-hop structural and semantic information in heterogeneous networks. To the best of our knowledge, this is the first attempt to break out of the confinement of meta-paths for representation learning on heterogeneous networks. We carry out extensive experiments on three real-world heterogeneous networks. The experimental results demonstrate that the proposed method significantly outperforms the current state-of-the-art methods in a variety of analytic tasks.