 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOmniMER: Indonesian Multimodal Emotion Recognition via Auxiliary-Enhanced LLM Adaptation
Dec 22, 2025Indonesian, spoken by over 200 million people, remains underserved in multimodal emotion recognition research despite its dominant presence on Southeast Asian social media platforms. We introduce IndoMER, the first multimodal emotion recognition benchmark for Indonesian, comprising 1,944 video segments from 203 speakers with temporally aligned text, audio, and visual annotations across seven emotion categories. The dataset exhibits realistic challenges including cross-modal inconsistency and long-tailed class distributions shaped by Indonesian cultural communication norms. To address these challenges, we propose OmniMER, a multimodal adaptation framework built upon Qwen2.5-Omni that enhances emotion recognition through three auxiliary modality-specific perception tasks: emotion keyword extraction for text, facial expression analysis for video, and prosody analysis for audio. These auxiliary tasks help the model identify emotion-relevant cues in each modality before fusion, reducing reliance on spurious correlations in low-resource settings. Experiments on IndoMER show that OmniMER achieves 0.582 Macro-F1 on sentiment classification and 0.454 on emotion recognition, outperforming the base model by 7.6 and 22.1 absolute points respectively. Cross-lingual evaluation on the Chinese CH-SIMS dataset further demonstrates the generalizability of the proposed framework. The dataset and code are publicly available. https://github.com/yanxm01/INDOMER
LR-IAD:Mask-Free Industrial Anomaly Detection with Logical Reasoning
Apr 28, 2025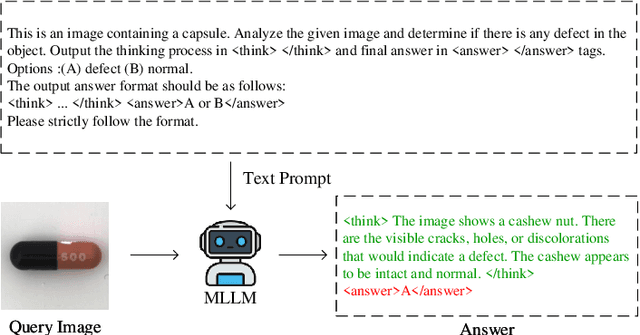

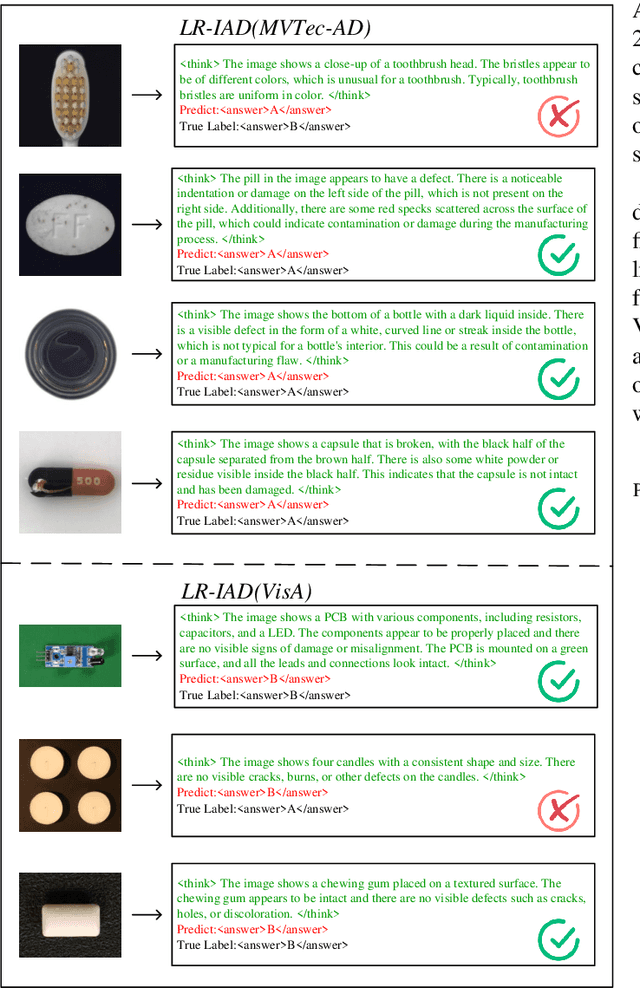

Industrial Anomaly Detection (IAD) is critical for ensuring product quality by identifying defects. Traditional methods such as feature embedding and reconstruction-based approaches require large datasets and struggle with scalability. Existing vision-language models (VLMs) and Multimodal Large Language Models (MLLMs) address some limitations but rely on mask annotations, leading to high implementation costs and false positives. Additionally, industrial datasets like MVTec-AD and VisA suffer from severe class imbalance, with defect samples constituting only 23.8% and 11.1% of total data respectively. To address these challenges, we propose a reward function that dynamically prioritizes rare defect patterns during training to handle class imbalance. We also introduce a mask-free reasoning framework using Chain of Thought (CoT) and Group Relative Policy Optimization (GRPO) mechanisms, enabling anomaly detection directly from raw images without annotated masks. This approach generates interpretable step-by-step explanations for defect localization. Our method achieves state-of-the-art performance, outperforming prior approaches by 36% in accuracy on MVTec-AD and 16% on VisA. By eliminating mask dependency and reducing costs while providing explainable outputs, this work advances industrial anomaly detection and supports scalable quality control in manufacturing. Code to reproduce the experiment is available at https://github.com/LilaKen/LR-IAD.
Chameleon: On the Scene Diversity and Domain Variety of AI-Generated Videos Detection
Mar 09, 2025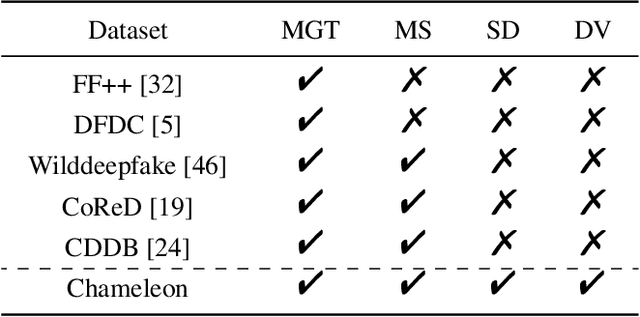

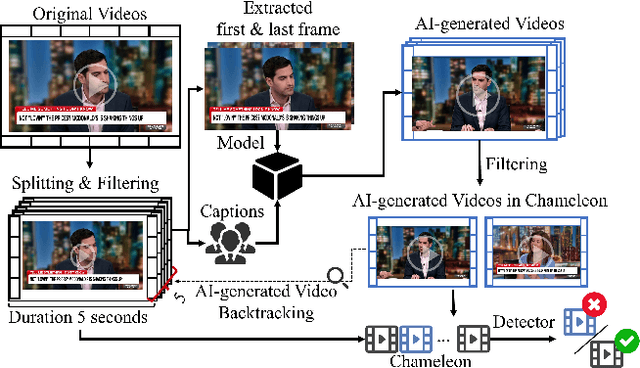
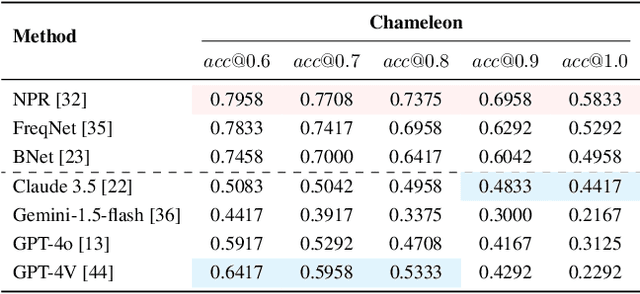
Artificial intelligence generated content (AIGC), known as DeepFakes, has emerged as a growing concern because it is being utilized as a tool for spreading disinformation. While much research exists on identifying AI-generated text and images, research on detecting AI-generated videos is limited. Existing datasets for AI-generated videos detection exhibit limitations in terms of diversity, complexity, and realism. To address these issues, this paper focuses on AI-generated videos detection and constructs a diverse dataset named Chameleon. We generate videos through multiple generation tools and various real video sources. At the same time, we preserve the videos' real-world complexity, including scene switches and dynamic perspective changes, and expand beyond face-centered detection to include human actions and environment generation. Our work bridges the gap between AI-generated dataset construction and real-world forensic needs, offering a valuable benchmark to counteract the evolving threats of AI-generated content.
LLM-driven Effective Knowledge Tracing by Integrating Dual-channel Difficulty
Feb 27, 2025Knowledge Tracing (KT) is a fundamental technology in intelligent tutoring systems used to simulate changes in students' knowledge state during learning, track personalized knowledge mastery, and predict performance. However, current KT models face three major challenges: (1) When encountering new questions, models face cold-start problems due to sparse interaction records, making precise modeling difficult; (2) Traditional models only use historical interaction records for student personalization modeling, unable to accurately track individual mastery levels, resulting in unclear personalized modeling; (3) The decision-making process is opaque to educators, making it challenging for them to understand model judgments. To address these challenges, we propose a novel Dual-channel Difficulty-aware Knowledge Tracing (DDKT) framework that utilizes Large Language Models (LLMs) and Retrieval-Augmented Generation (RAG) for subjective difficulty assessment, while integrating difficulty bias-aware algorithms and student mastery algorithms for precise difficulty measurement. Our framework introduces three key innovations: (1) Difficulty Balance Perception Sequence (DBPS) - students' subjective perceptions combined with objective difficulty, measuring gaps between LLM-assessed difficulty, mathematical-statistical difficulty, and students' subjective perceived difficulty through attention mechanisms; (2) Difficulty Mastery Ratio (DMR) - precise modeling of student mastery levels through different difficulty zones; (3) Knowledge State Update Mechanism - implementing personalized knowledge acquisition through gated networks and updating student knowledge state. Experimental results on two real datasets show our method consistently outperforms nine baseline models, improving AUC metrics by 2% to 10% while effectively addressing cold-start problems and enhancing model interpretability.
CLASS: Enhancing Cross-Modal Text-Molecule Retrieval Performance and Training Efficiency
Feb 17, 2025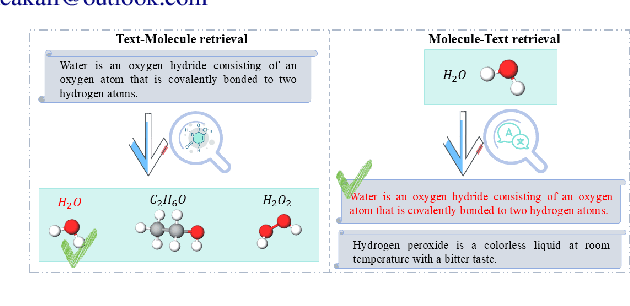
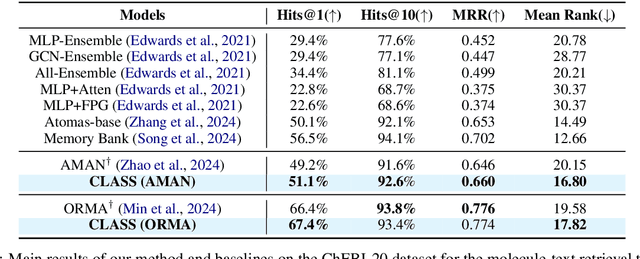
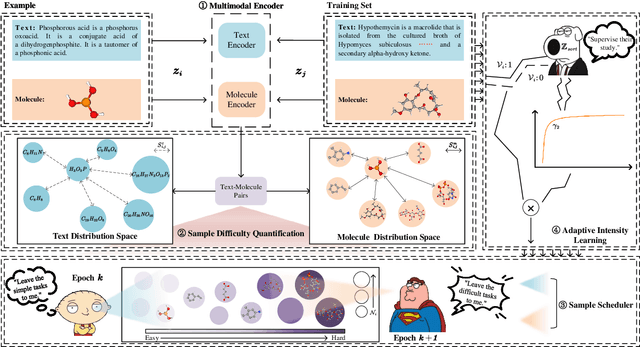
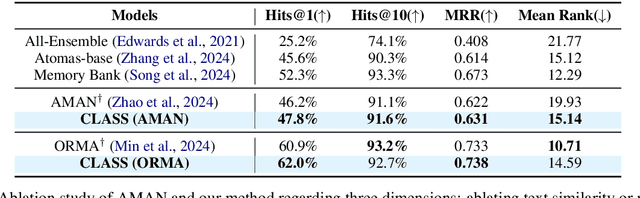
Cross-modal text-molecule retrieval task bridges molecule structures and natural language descriptions. Existing methods predominantly focus on aligning text modality and molecule modality, yet they overlook adaptively adjusting the learning states at different training stages and enhancing training efficiency. To tackle these challenges, this paper proposes a Curriculum Learning-bAsed croSS-modal text-molecule training framework (CLASS), which can be integrated with any backbone to yield promising performance improvement. Specifically, we quantify the sample difficulty considering both text modality and molecule modality, and design a sample scheduler to introduce training samples via an easy-to-difficult paradigm as the training advances, remarkably reducing the scale of training samples at the early stage of training and improving training efficiency. Moreover, we introduce adaptive intensity learning to increase the training intensity as the training progresses, which adaptively controls the learning intensity across all curriculum stages. Experimental results on the ChEBI-20 dataset demonstrate that our proposed method gains superior performance, simultaneously achieving prominent time savings.
Jailbreaking? One Step Is Enough!
Dec 17, 2024



Large language models (LLMs) excel in various tasks but remain vulnerable to jailbreak attacks, where adversaries manipulate prompts to generate harmful outputs. Examining jailbreak prompts helps uncover the shortcomings of LLMs. However, current jailbreak methods and the target model's defenses are engaged in an independent and adversarial process, resulting in the need for frequent attack iterations and redesigning attacks for different models. To address these gaps, we propose a Reverse Embedded Defense Attack (REDA) mechanism that disguises the attack intention as the "defense". intention against harmful content. Specifically, REDA starts from the target response, guiding the model to embed harmful content within its defensive measures, thereby relegating harmful content to a secondary role and making the model believe it is performing a defensive task. The attacking model considers that it is guiding the target model to deal with harmful content, while the target model thinks it is performing a defensive task, creating an illusion of cooperation between the two. Additionally, to enhance the model's confidence and guidance in "defensive" intentions, we adopt in-context learning (ICL) with a small number of attack examples and construct a corresponding dataset of attack examples. Extensive evaluations demonstrate that the REDA method enables cross-model attacks without the need to redesign attack strategies for different models, enables successful jailbreak in one iteration, and outperforms existing methods on both open-source and closed-source models.
A Simple Yet Effective Corpus Construction Framework for Indonesian Grammatical Error Correction
Oct 28, 2024Currently, the majority of research in grammatical error correction (GEC) is concentrated on universal languages, such as English and Chinese. Many low-resource languages lack accessible evaluation corpora. How to efficiently construct high-quality evaluation corpora for GEC in low-resource languages has become a significant challenge. To fill these gaps, in this paper, we present a framework for constructing GEC corpora. Specifically, we focus on Indonesian as our research language and construct an evaluation corpus for Indonesian GEC using the proposed framework, addressing the limitations of existing evaluation corpora in Indonesian. Furthermore, we investigate the feasibility of utilizing existing large language models (LLMs), such as GPT-3.5-Turbo and GPT-4, to streamline corpus annotation efforts in GEC tasks. The results demonstrate significant potential for enhancing the performance of LLMs in low-resource language settings. Our code and corpus can be obtained from https://github.com/GKLMIP/GEC-Construction-Framework.
HateDebias: On the Diversity and Variability of Hate Speech Debiasing
Jun 07, 2024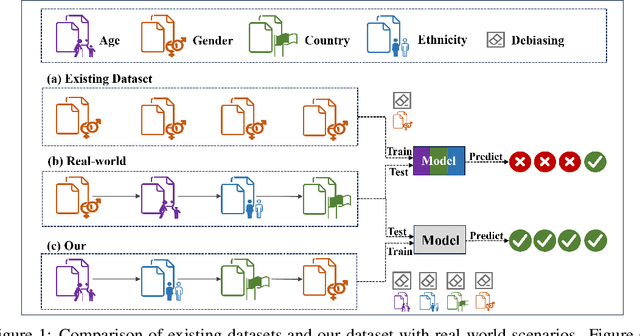



Hate speech on social media is ubiquitous but urgently controlled. Without detecting and mitigating the biases brought by hate speech, different types of ethical problems. While a number of datasets have been proposed to address the problem of hate speech detection, these datasets seldom consider the diversity and variability of bias, making it far from real-world scenarios. To fill this gap, we propose a benchmark, named HateDebias, to analyze the model ability of hate speech detection under continuous, changing environments. Specifically, to meet the diversity of biases, we collect existing hate speech detection datasets with different types of biases. To further meet the variability (i.e., the changing of bias attributes in datasets), we reorganize datasets to follow the continuous learning setting. We evaluate the detection accuracy of models trained on the datasets with a single type of bias with the performance on the HateDebias, where a significant performance drop is observed. To provide a potential direction for debiasing, we further propose a debiasing framework based on continuous learning and bias information regularization, as well as the memory replay strategies to ensure the debiasing ability of the model. Experiment results on the proposed benchmark show that the aforementioned method can improve several baselines with a distinguished margin, highlighting its effectiveness in real-world applications.
An interpretability framework for Similar case matching
Apr 04, 2023



Similar Case Matching (SCM) is designed to determine whether two cases are similar. The task has an essential role in the legal system, helping legal professionals to find relevant cases quickly and thus deal with them more efficiently. Existing research has focused on improving the model's performance but not on its interpretability. Therefore, this paper proposes a pipeline framework for interpretable SCM, which consists of four modules: a judicial feature sentence identification module, a case matching module, a feature sentence alignment module, and a conflict disambiguation module. Unlike existing SCM methods, our framework will identify feature sentences in a case that contain essential information, perform similar case matching based on the extracted feature sentence results, and align the feature sentences in the two cases to provide evidence for the similarity of the cases. SCM results may conflict with feature sentence alignment results, and our framework further disambiguates against this inconsistency. The experimental results show the effectiveness of our framework, and our work provides a new benchmark for interpretable SCM.
A BERT-based Unsupervised Grammatical Error Correction Framework
Mar 30, 2023



Grammatical error correction (GEC) is a challenging task of natural language processing techniques. While more attempts are being made in this approach for universal languages like English or Chinese, relatively little work has been done for low-resource languages for the lack of large annotated corpora. In low-resource languages, the current unsupervised GEC based on language model scoring performs well. However, the pre-trained language model is still to be explored in this context. This study proposes a BERT-based unsupervised GEC framework, where GEC is viewed as multi-class classification task. The framework contains three modules: data flow construction module, sentence perplexity scoring module, and error detecting and correcting module. We propose a novel scoring method for pseudo-perplexity to evaluate a sentence's probable correctness and construct a Tagalog corpus for Tagalog GEC research. It obtains competitive performance on the Tagalog corpus we construct and open-source Indonesian corpus and it demonstrates that our framework is complementary to baseline method for low-resource GEC task.