 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLR-IAD:Mask-Free Industrial Anomaly Detection with Logical Reasoning
Apr 28, 2025Industrial Anomaly Detection (IAD) is critical for ensuring product quality by identifying defects. Traditional methods such as feature embedding and reconstruction-based approaches require large datasets and struggle with scalability. Existing vision-language models (VLMs) and Multimodal Large Language Models (MLLMs) address some limitations but rely on mask annotations, leading to high implementation costs and false positives. Additionally, industrial datasets like MVTec-AD and VisA suffer from severe class imbalance, with defect samples constituting only 23.8% and 11.1% of total data respectively. To address these challenges, we propose a reward function that dynamically prioritizes rare defect patterns during training to handle class imbalance. We also introduce a mask-free reasoning framework using Chain of Thought (CoT) and Group Relative Policy Optimization (GRPO) mechanisms, enabling anomaly detection directly from raw images without annotated masks. This approach generates interpretable step-by-step explanations for defect localization. Our method achieves state-of-the-art performance, outperforming prior approaches by 36% in accuracy on MVTec-AD and 16% on VisA. By eliminating mask dependency and reducing costs while providing explainable outputs, this work advances industrial anomaly detection and supports scalable quality control in manufacturing. Code to reproduce the experiment is available at https://github.com/LilaKen/LR-IAD.
CLASS: Enhancing Cross-Modal Text-Molecule Retrieval Performance and Training Efficiency
Feb 17, 2025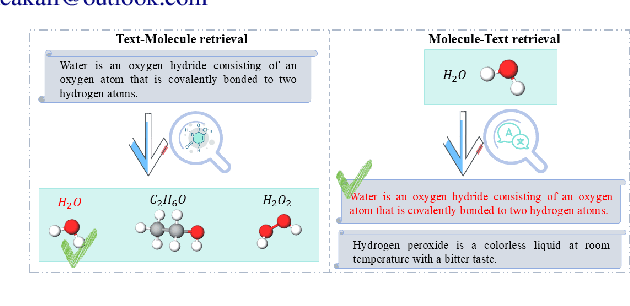
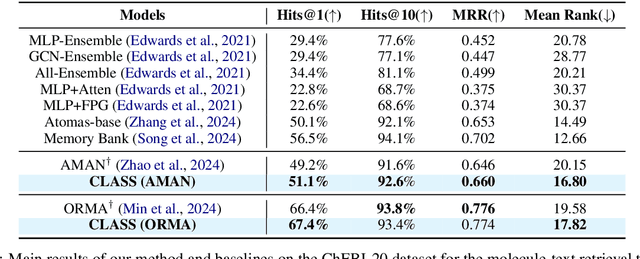
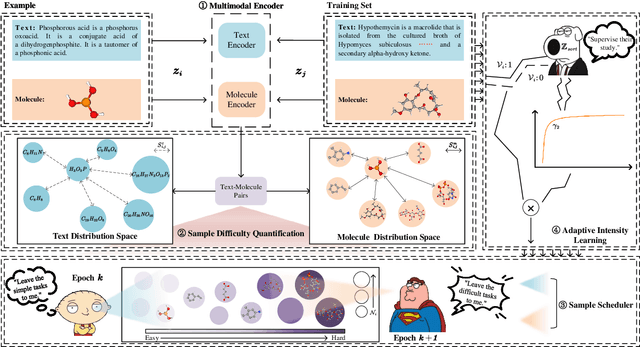
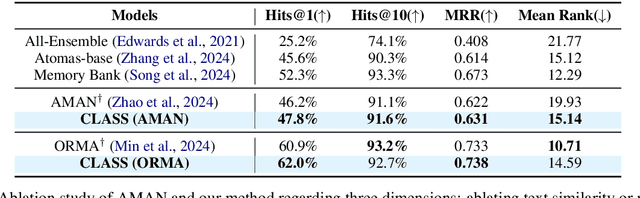
Cross-modal text-molecule retrieval task bridges molecule structures and natural language descriptions. Existing methods predominantly focus on aligning text modality and molecule modality, yet they overlook adaptively adjusting the learning states at different training stages and enhancing training efficiency. To tackle these challenges, this paper proposes a Curriculum Learning-bAsed croSS-modal text-molecule training framework (CLASS), which can be integrated with any backbone to yield promising performance improvement. Specifically, we quantify the sample difficulty considering both text modality and molecule modality, and design a sample scheduler to introduce training samples via an easy-to-difficult paradigm as the training advances, remarkably reducing the scale of training samples at the early stage of training and improving training efficiency. Moreover, we introduce adaptive intensity learning to increase the training intensity as the training progresses, which adaptively controls the learning intensity across all curriculum stages. Experimental results on the ChEBI-20 dataset demonstrate that our proposed method gains superior performance, simultaneously achieving prominent time savings.
Jailbreaking? One Step Is Enough!
Dec 17, 2024



Large language models (LLMs) excel in various tasks but remain vulnerable to jailbreak attacks, where adversaries manipulate prompts to generate harmful outputs. Examining jailbreak prompts helps uncover the shortcomings of LLMs. However, current jailbreak methods and the target model's defenses are engaged in an independent and adversarial process, resulting in the need for frequent attack iterations and redesigning attacks for different models. To address these gaps, we propose a Reverse Embedded Defense Attack (REDA) mechanism that disguises the attack intention as the "defense". intention against harmful content. Specifically, REDA starts from the target response, guiding the model to embed harmful content within its defensive measures, thereby relegating harmful content to a secondary role and making the model believe it is performing a defensive task. The attacking model considers that it is guiding the target model to deal with harmful content, while the target model thinks it is performing a defensive task, creating an illusion of cooperation between the two. Additionally, to enhance the model's confidence and guidance in "defensive" intentions, we adopt in-context learning (ICL) with a small number of attack examples and construct a corresponding dataset of attack examples. Extensive evaluations demonstrate that the REDA method enables cross-model attacks without the need to redesign attack strategies for different models, enables successful jailbreak in one iteration, and outperforms existing methods on both open-source and closed-source models.