 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCLASS: Enhancing Cross-Modal Text-Molecule Retrieval Performance and Training Efficiency
Paper and Code
Feb 17, 2025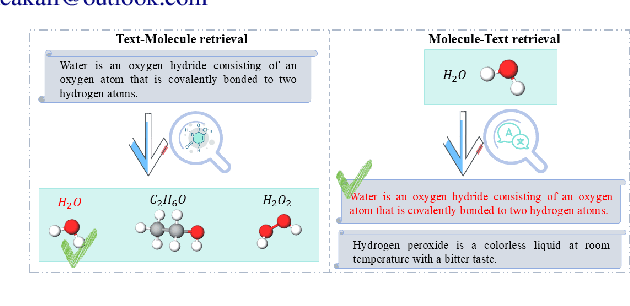
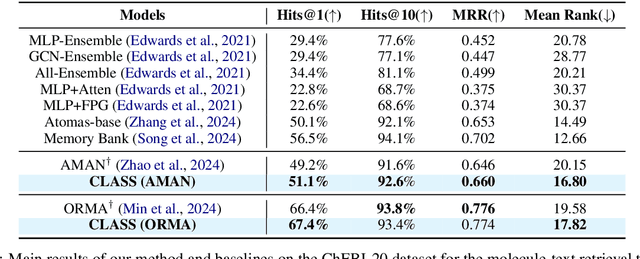
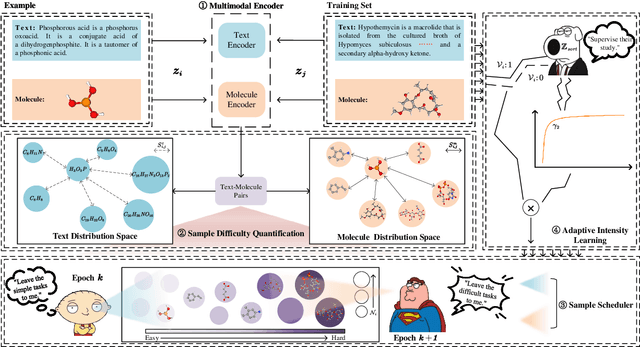
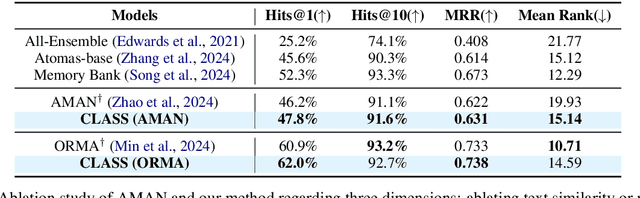
Cross-modal text-molecule retrieval task bridges molecule structures and natural language descriptions. Existing methods predominantly focus on aligning text modality and molecule modality, yet they overlook adaptively adjusting the learning states at different training stages and enhancing training efficiency. To tackle these challenges, this paper proposes a Curriculum Learning-bAsed croSS-modal text-molecule training framework (CLASS), which can be integrated with any backbone to yield promising performance improvement. Specifically, we quantify the sample difficulty considering both text modality and molecule modality, and design a sample scheduler to introduce training samples via an easy-to-difficult paradigm as the training advances, remarkably reducing the scale of training samples at the early stage of training and improving training efficiency. Moreover, we introduce adaptive intensity learning to increase the training intensity as the training progresses, which adaptively controls the learning intensity across all curriculum stages. Experimental results on the ChEBI-20 dataset demonstrate that our proposed method gains superior performance, simultaneously achieving prominent time savings.