 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOTESGN:Optimal Transport Enhanced Syntactic-Semantic Graph Networks for Aspect-Based Sentiment Analysis
Sep 10, 2025Aspect-based sentiment analysis (ABSA) aims to identify aspect terms and determine their sentiment polarity. While dependency trees combined with contextual semantics effectively identify aspect sentiment, existing methods relying on syntax trees and aspect-aware attention struggle to model complex semantic relationships. Their dependence on linear dot-product features fails to capture nonlinear associations, allowing noisy similarity from irrelevant words to obscure key opinion terms. Motivated by Differentiable Optimal Matching, we propose the Optimal Transport Enhanced Syntactic-Semantic Graph Network (OTESGN), which introduces a Syntactic-Semantic Collaborative Attention. It comprises a Syntactic Graph-Aware Attention for mining latent syntactic dependencies and modeling global syntactic topology, as well as a Semantic Optimal Transport Attention designed to uncover fine-grained semantic alignments amidst textual noise, thereby accurately capturing sentiment signals obscured by irrelevant tokens. A Adaptive Attention Fusion module integrates these heterogeneous features, and contrastive regularization further improves robustness. Experiments demonstrate that OTESGN achieves state-of-the-art results, outperforming previous best models by +1.01% F1 on Twitter and +1.30% F1 on Laptop14 benchmarks. Ablative studies and visual analyses corroborate its efficacy in precise localization of opinion words and noise resistance.
CLASS: Enhancing Cross-Modal Text-Molecule Retrieval Performance and Training Efficiency
Feb 17, 2025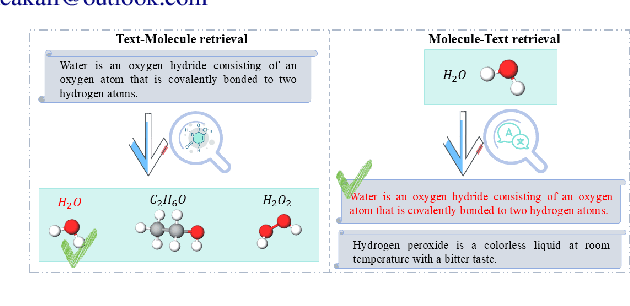
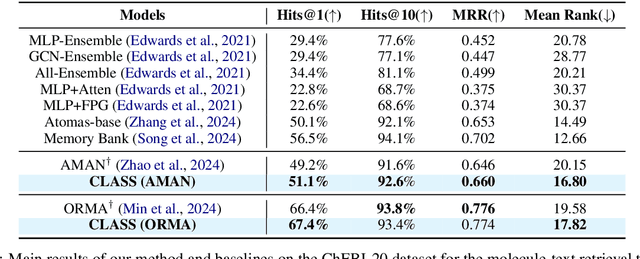
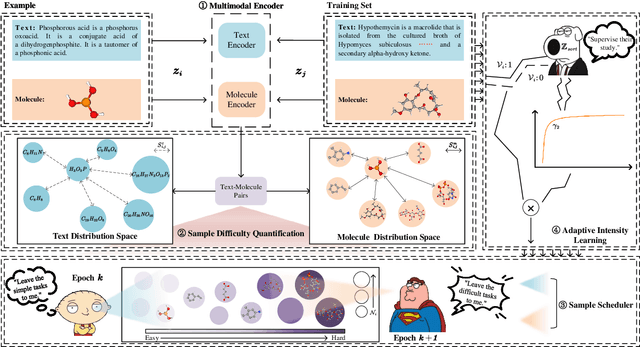
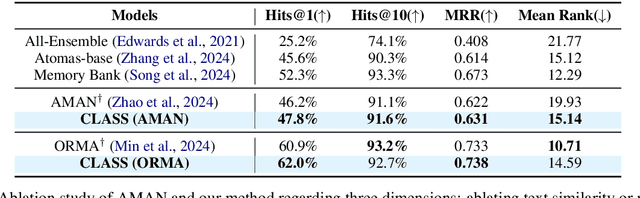
Cross-modal text-molecule retrieval task bridges molecule structures and natural language descriptions. Existing methods predominantly focus on aligning text modality and molecule modality, yet they overlook adaptively adjusting the learning states at different training stages and enhancing training efficiency. To tackle these challenges, this paper proposes a Curriculum Learning-bAsed croSS-modal text-molecule training framework (CLASS), which can be integrated with any backbone to yield promising performance improvement. Specifically, we quantify the sample difficulty considering both text modality and molecule modality, and design a sample scheduler to introduce training samples via an easy-to-difficult paradigm as the training advances, remarkably reducing the scale of training samples at the early stage of training and improving training efficiency. Moreover, we introduce adaptive intensity learning to increase the training intensity as the training progresses, which adaptively controls the learning intensity across all curriculum stages. Experimental results on the ChEBI-20 dataset demonstrate that our proposed method gains superior performance, simultaneously achieving prominent time savings.
An Effective Deployment of Diffusion LM for Data Augmentation in Low-Resource Sentiment Classification
Sep 05, 2024



Sentiment classification (SC) often suffers from low-resource challenges such as domain-specific contexts, imbalanced label distributions, and few-shot scenarios. The potential of the diffusion language model (LM) for textual data augmentation (DA) remains unexplored, moreover, textual DA methods struggle to balance the diversity and consistency of new samples. Most DA methods either perform logical modifications or rephrase less important tokens in the original sequence with the language model. In the context of SC, strong emotional tokens could act critically on the sentiment of the whole sequence. Therefore, contrary to rephrasing less important context, we propose DiffusionCLS to leverage a diffusion LM to capture in-domain knowledge and generate pseudo samples by reconstructing strong label-related tokens. This approach ensures a balance between consistency and diversity, avoiding the introduction of noise and augmenting crucial features of datasets. DiffusionCLS also comprises a Noise-Resistant Training objective to help the model generalize. Experiments demonstrate the effectiveness of our method in various low-resource scenarios including domain-specific and domain-general problems. Ablation studies confirm the effectiveness of our framework's modules, and visualization studies highlight optimal deployment conditions, reinforcing our conclusions.
HateDebias: On the Diversity and Variability of Hate Speech Debiasing
Jun 07, 2024



Hate speech on social media is ubiquitous but urgently controlled. Without detecting and mitigating the biases brought by hate speech, different types of ethical problems. While a number of datasets have been proposed to address the problem of hate speech detection, these datasets seldom consider the diversity and variability of bias, making it far from real-world scenarios. To fill this gap, we propose a benchmark, named HateDebias, to analyze the model ability of hate speech detection under continuous, changing environments. Specifically, to meet the diversity of biases, we collect existing hate speech detection datasets with different types of biases. To further meet the variability (i.e., the changing of bias attributes in datasets), we reorganize datasets to follow the continuous learning setting. We evaluate the detection accuracy of models trained on the datasets with a single type of bias with the performance on the HateDebias, where a significant performance drop is observed. To provide a potential direction for debiasing, we further propose a debiasing framework based on continuous learning and bias information regularization, as well as the memory replay strategies to ensure the debiasing ability of the model. Experiment results on the proposed benchmark show that the aforementioned method can improve several baselines with a distinguished margin, highlighting its effectiveness in real-world applications.
Multilingual Text Classification for Dravidian Languages
Dec 03, 2021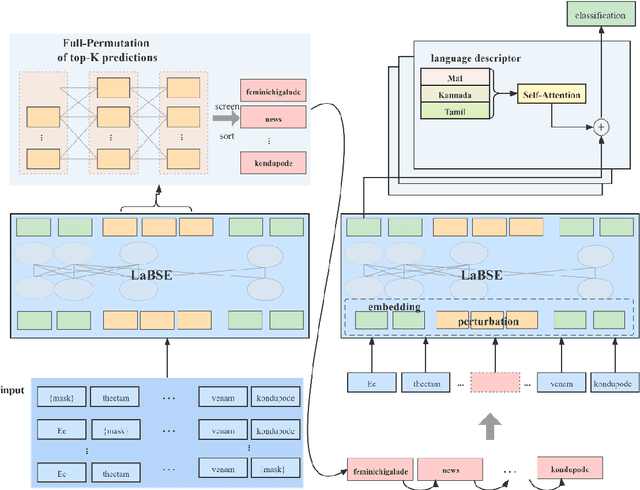
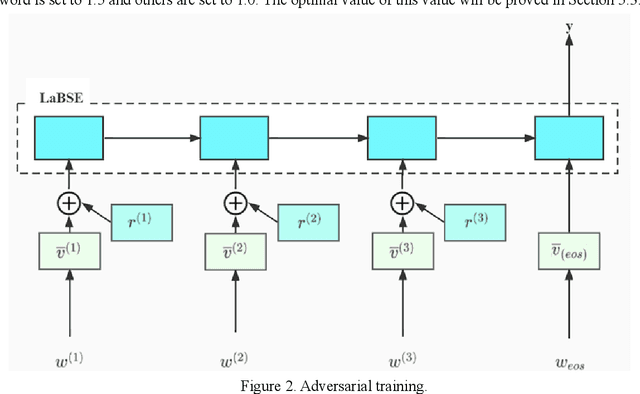

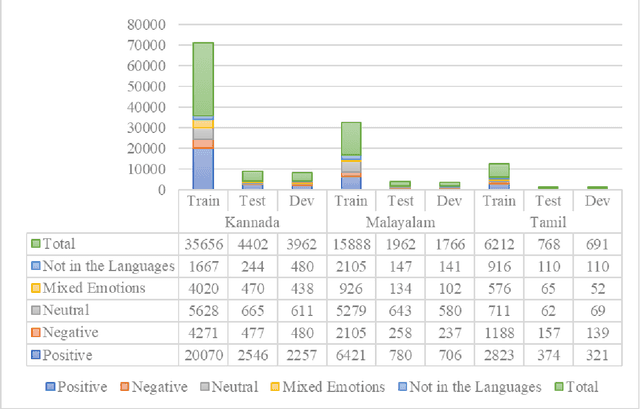
As the fourth largest language family in the world, the Dravidian languages have become a research hotspot in natural language processing (NLP). Although the Dravidian languages contain a large number of languages, there are relatively few public available resources. Besides, text classification task, as a basic task of natural language processing, how to combine it to multiple languages in the Dravidian languages, is still a major difficulty in Dravidian Natural Language Processing. Hence, to address these problems, we proposed a multilingual text classification framework for the Dravidian languages. On the one hand, the framework used the LaBSE pre-trained model as the base model. Aiming at the problem of text information bias in multi-task learning, we propose to use the MLM strategy to select language-specific words, and used adversarial training to perturb them. On the other hand, in view of the problem that the model cannot well recognize and utilize the correlation among languages, we further proposed a language-specific representation module to enrich semantic information for the model. The experimental results demonstrated that the framework we proposed has a significant performance in multilingual text classification tasks with each strategy achieving certain improvements.