 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLong-Document QA with Chain-of-Structured-Thought and Fine-Tuned SLMs
Mar 31, 2026Large language models (LLMs) are widely applied to data analytics over documents, yet direct reasoning over long, noisy documents remains brittle and error-prone. Hence, we study document question answering (QA) that consolidates dispersed evidence into a structured output (e.g., a table, graph, or chunks) to support reliable, verifiable QA. We propose a two-pillar framework, LiteCoST, to achieve both high accuracy and low latency with small language models (SLMs). Pillar 1: Chain-of-Structured-Thought (CoST). We introduce a CoST template, a schema-aware instruction that guides a strong LLM to produce both a step-wise CoST trace and the corresponding structured output. The process induces a minimal structure, normalizes entities/units, aligns records, serializes the output, and verifies/refines it, yielding auditable supervision. Pillar 2: SLM fine-tuning. The compact models are trained on LLM-generated CoST data in two stages: Supervised Fine-Tuning for structural alignment, followed by Group Relative Policy Optimization (GRPO) incorporating triple rewards for answer/format quality and process consistency. By distilling structure-first behavior into SLMs, this approach achieves LLM-comparable quality on multi-domain long-document QA using 3B/7B SLMs, while delivering 2-4x lower latency than GPT-4o and DeepSeek-R1 (671B). The code is available at https://github.com/HKUSTDial/LiteCoST.
Concise Reasoning, Big Gains: Pruning Long Reasoning Trace with Difficulty-Aware Prompting
May 26, 2025Existing chain-of-thought (CoT) distillation methods can effectively transfer reasoning abilities to base models but suffer from two major limitations: excessive verbosity of reasoning traces and inadequate adaptability to problem difficulty. Long reasoning traces significantly increase inference costs, and uniform-length solutions prevent base models from learning adaptive reasoning strategies. To address these issues, we propose a difficulty-aware prompting (DAP) method to dynamically shorten reasoning traces without performance loss. In our approach, a large teacher model first judges each problem's difficulty and then rewrites its reasoning traces to an appropriate shorter length, yielding concise yet complete reasoning traces. Leveraging the DAP pipeline, we curate a distilled dataset called LiteCoT consisting of 100K concise reasoning examples, with solutions averaging only 720 tokens (an order of magnitude shorter than typical CoTs). Using LiteCoT, we distilled a new family of reasoning models called Liter (1.5B, 7B, and 32B) based on the Qwen2.5 architecture. Experiments show that a student model fine-tuned on just 100K of these difficulty-pruned CoT samples outperforms a model distilled on 800K original Long CoT samples, while significantly reducing training and inference costs. Our method also generalizes well: across 11 diverse benchmarks, the shorter difficulty-aware CoTs achieve equal or better accuracy than Long chains, using far fewer tokens. For example, on the challenging AIME24 exam, our approach reaches $74.2\%$ Pass@1 using only about 5K inference tokens, surpassing other methods that consume many more tokens. Our code and data are available at https://github.com/Evanwu1125/LiteCoT.
LEAD: Iterative Data Selection for Efficient LLM Instruction Tuning
May 12, 2025Instruction tuning has emerged as a critical paradigm for improving the capabilities and alignment of large language models (LLMs). However, existing iterative model-aware data selection methods incur significant computational overhead, as they rely on repeatedly performing full-dataset model inference to estimate sample utility for subsequent training iterations, creating a fundamental efficiency bottleneck. In this paper, we propose LEAD, an efficient iterative data selection framework that accurately estimates sample utility entirely within the standard training loop, eliminating the need for costly additional model inference. At its core, LEAD introduces Instance-Level Dynamic Uncertainty (IDU), a theoretically grounded utility function combining instantaneous training loss, gradient-based approximation of loss changes, and exponential smoothing of historical loss signals. To further scale efficiently to large datasets, LEAD employs a two-stage, coarse-to-fine selection strategy, adaptively prioritizing informative clusters through a multi-armed bandit mechanism, followed by precise fine-grained selection of high-utility samples using IDU. Extensive experiments across four diverse benchmarks show that LEAD significantly outperforms state-of-the-art methods, improving average model performance by 6.1%-10.8% while using only 2.5% of the training data and reducing overall training time by 5-10x.
GAgent: An Adaptive Rigid-Soft Gripping Agent with Vision Language Models for Complex Lighting Environments
Mar 16, 2024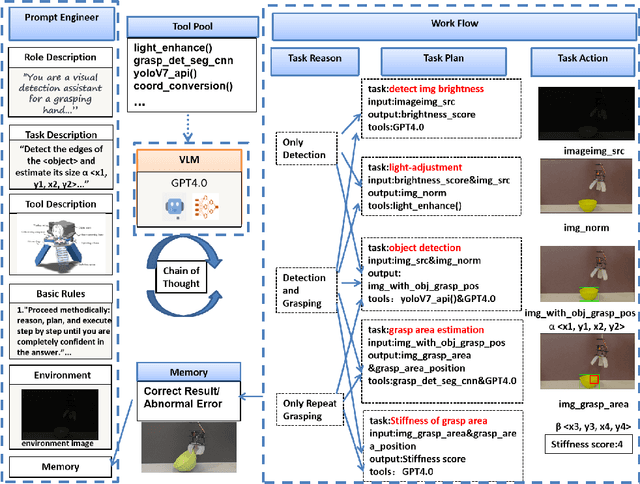

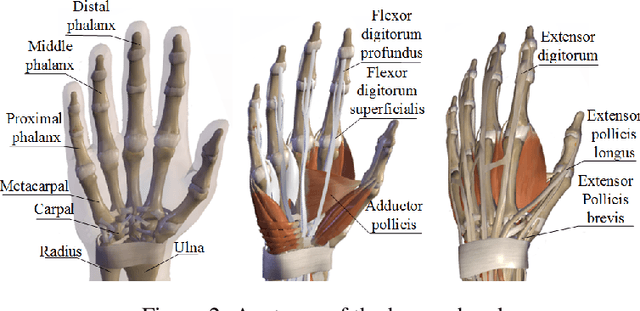
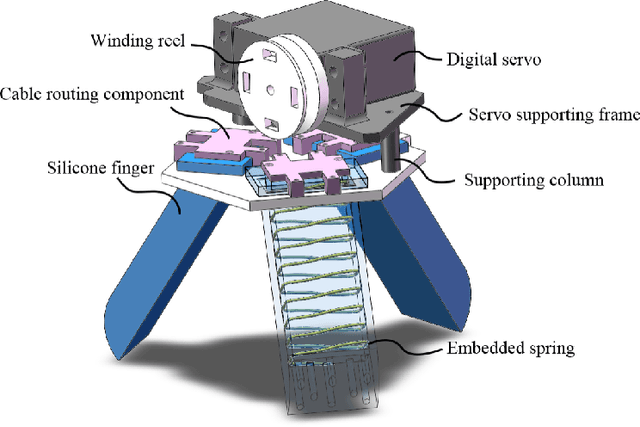
This paper introduces GAgent: an Gripping Agent designed for open-world environments that provides advanced cognitive abilities via VLM agents and flexible grasping abilities with variable stiffness soft grippers. GAgent comprises three primary components - Prompt Engineer module, Visual-Language Model (VLM) core and Workflow module. These three modules enhance gripper success rates by recognizing objects and materials and accurately estimating grasp area even under challenging lighting conditions. As part of creativity, researchers also created a bionic hybrid soft gripper with variable stiffness capable of gripping heavy loads while still gently engaging objects. This intelligent agent, featuring VLM-based cognitive processing with bionic design, shows promise as it could potentially benefit UAVs in various scenarios.
Characterising User Transfer Amid Industrial Resource Variation: A Bayesian Nonparametric Approach
Sep 25, 2023In a multitude of industrial fields, a key objective entails optimising resource management whilst satisfying user requirements. Resource management by industrial practitioners can result in a passive transfer of user loads across resource providers, a phenomenon whose accurate characterisation is both challenging and crucial. This research reveals the existence of user clusters, which capture macro-level user transfer patterns amid resource variation. We then propose CLUSTER, an interpretable hierarchical Bayesian nonparametric model capable of automating cluster identification, and thereby predicting user transfer in response to resource variation. Furthermore, CLUSTER facilitates uncertainty quantification for further reliable decision-making. Our method enables privacy protection by functioning independently of personally identifiable information. Experiments with simulated and real-world data from the communications industry reveal a pronounced alignment between prediction results and empirical observations across a spectrum of resource management scenarios. This research establishes a solid groundwork for advancing resource management strategy development.
A Survey on Deep Multi-modal Learning for Body Language Recognition and Generation
Aug 17, 2023



Body language (BL) refers to the non-verbal communication expressed through physical movements, gestures, facial expressions, and postures. It is a form of communication that conveys information, emotions, attitudes, and intentions without the use of spoken or written words. It plays a crucial role in interpersonal interactions and can complement or even override verbal communication. Deep multi-modal learning techniques have shown promise in understanding and analyzing these diverse aspects of BL. The survey emphasizes their applications to BL generation and recognition. Several common BLs are considered i.e., Sign Language (SL), Cued Speech (CS), Co-speech (CoS), and Talking Head (TH), and we have conducted an analysis and established the connections among these four BL for the first time. Their generation and recognition often involve multi-modal approaches. Benchmark datasets for BL research are well collected and organized, along with the evaluation of SOTA methods on these datasets. The survey highlights challenges such as limited labeled data, multi-modal learning, and the need for domain adaptation to generalize models to unseen speakers or languages. Future research directions are presented, including exploring self-supervised learning techniques, integrating contextual information from other modalities, and exploiting large-scale pre-trained multi-modal models. In summary, this survey paper provides a comprehensive understanding of deep multi-modal learning for various BL generations and recognitions for the first time. By analyzing advancements, challenges, and future directions, it serves as a valuable resource for researchers and practitioners in advancing this field. n addition, we maintain a continuously updated paper list for deep multi-modal learning for BL recognition and generation: https://github.com/wentaoL86/awesome-body-language.
Mitigating Catastrophic Forgetting in Task-Incremental Continual Learning with Adaptive Classification Criterion
May 20, 2023



Task-incremental continual learning refers to continually training a model in a sequence of tasks while overcoming the problem of catastrophic forgetting (CF). The issue arrives for the reason that the learned representations are forgotten for learning new tasks, and the decision boundary is destructed. Previous studies mostly consider how to recover the representations of learned tasks. It is seldom considered to adapt the decision boundary for new representations and in this paper we propose a Supervised Contrastive learning framework with adaptive classification criterion for Continual Learning (SCCL), In our method, a contrastive loss is used to directly learn representations for different tasks and a limited number of data samples are saved as the classification criterion. During inference, the saved data samples are fed into the current model to obtain updated representations, and a k Nearest Neighbour module is used for classification. In this way, the extensible model can solve the learned tasks with adaptive criteria of saved samples. To mitigate CF, we further use an instance-wise relation distillation regularization term and a memory replay module to maintain the information of previous tasks. Experiments show that SCCL achieves state-of-the-art performance and has a stronger ability to overcome CF compared with the classification baselines.
How to choose "Good" Samples for Text Data Augmentation
Feb 02, 2023



Deep learning-based text classification models need abundant labeled data to obtain competitive performance. Unfortunately, annotating large-size corpus is time-consuming and laborious. To tackle this, multiple researches try to use data augmentation to expand the corpus size. However, data augmentation may potentially produce some noisy augmented samples. There are currently no works exploring sample selection for augmented samples in nature language processing field. In this paper, we propose a novel self-training selection framework with two selectors to select the high-quality samples from data augmentation. Specifically, we firstly use an entropy-based strategy and the model prediction to select augmented samples. Considering some samples with high quality at the above step may be wrongly filtered, we propose to recall them from two perspectives of word overlap and semantic similarity. Experimental results show the effectiveness and simplicity of our framework.
A Chinese Spelling Check Framework Based on Reverse Contrastive Learning
Oct 25, 2022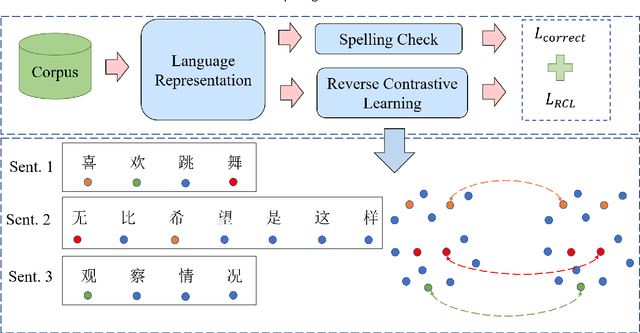
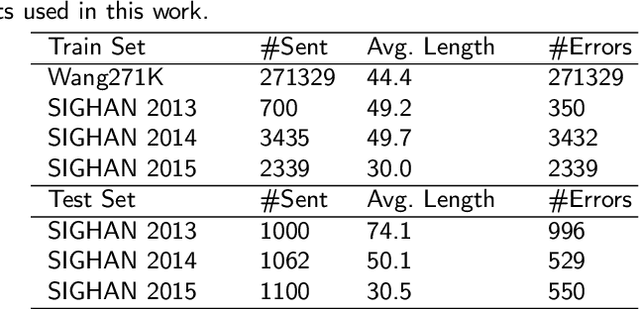
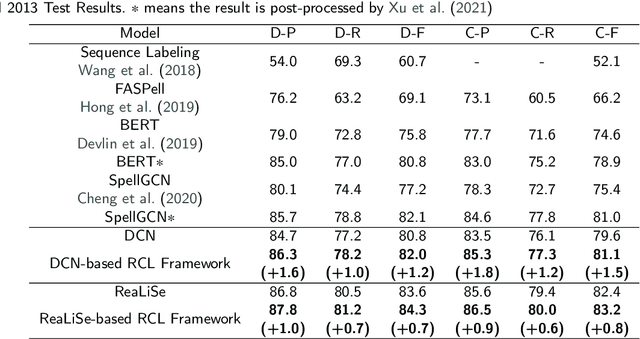
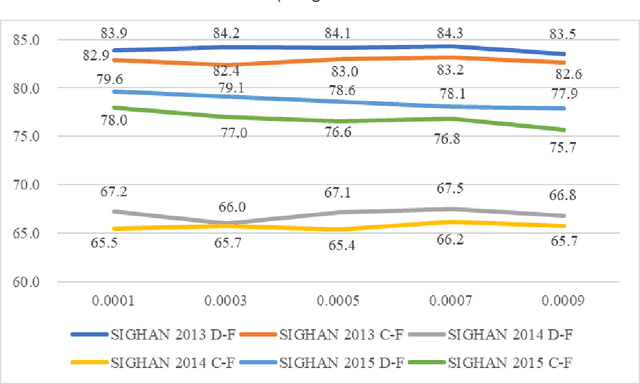
Chinese spelling check is a task to detect and correct spelling mistakes in Chinese text. Existing research aims to enhance the text representation and use multi-source information to improve the detection and correction capabilities of models, but does not pay too much attention to improving their ability to distinguish between confusable words. Contrastive learning, whose aim is to minimize the distance in representation space between similar sample pairs, has recently become a dominant technique in natural language processing. Inspired by contrastive learning, we present a novel framework for Chinese spelling checking, which consists of three modules: language representation, spelling check and reverse contrastive learning. Specifically, we propose a reverse contrastive learning strategy, which explicitly forces the model to minimize the agreement between the similar examples, namely, the phonetically and visually confusable characters. Experimental results show that our framework is model-agnostic and could be combined with existing Chinese spelling check models to yield state-of-the-art performance.
An Efficient Framework for Few-shot Skeleton-based Temporal Action Segmentation
Jul 20, 2022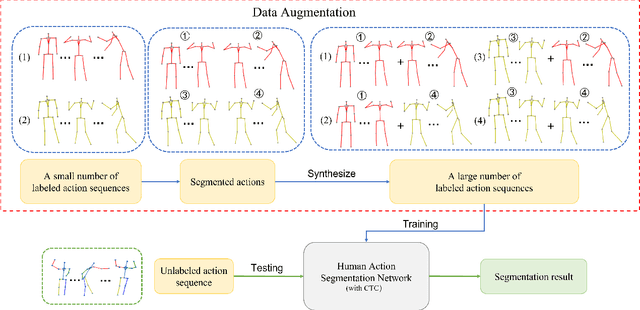
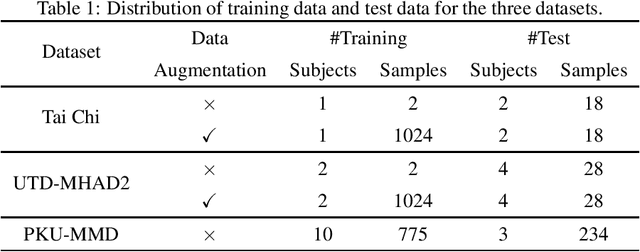
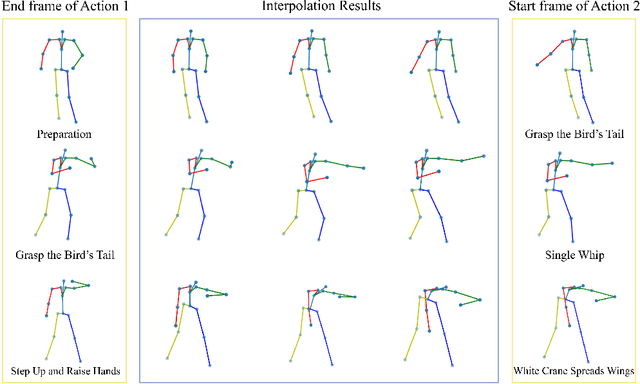
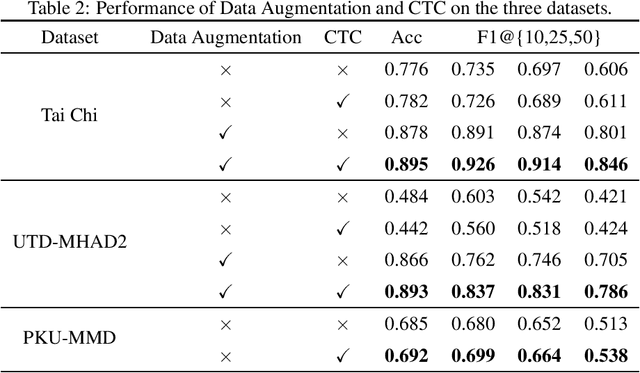
Temporal action segmentation (TAS) aims to classify and locate actions in the long untrimmed action sequence. With the success of deep learning, many deep models for action segmentation have emerged. However, few-shot TAS is still a challenging problem. This study proposes an efficient framework for the few-shot skeleton-based TAS, including a data augmentation method and an improved model. The data augmentation approach based on motion interpolation is presented here to solve the problem of insufficient data, and can increase the number of samples significantly by synthesizing action sequences. Besides, we concatenate a Connectionist Temporal Classification (CTC) layer with a network designed for skeleton-based TAS to obtain an optimized model. Leveraging CTC can enhance the temporal alignment between prediction and ground truth and further improve the segment-wise metrics of segmentation results. Extensive experiments on both public and self-constructed datasets, including two small-scale datasets and one large-scale dataset, show the effectiveness of two proposed methods in improving the performance of the few-shot skeleton-based TAS task.