 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Efficient Framework for Few-shot Skeleton-based Temporal Action Segmentation
Jul 20, 2022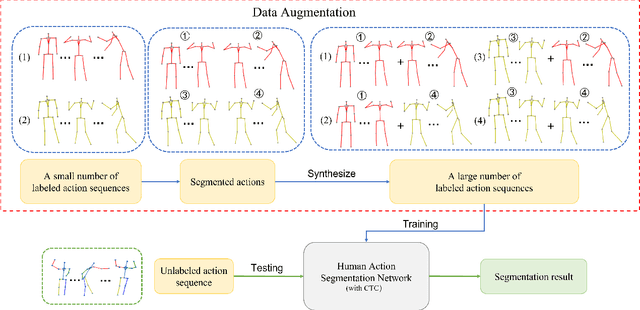
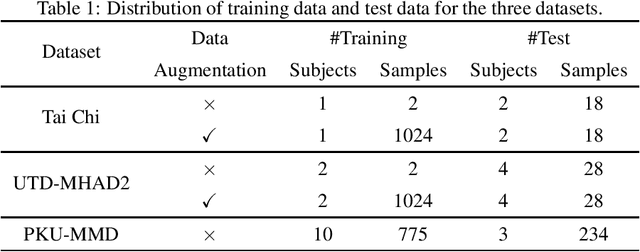
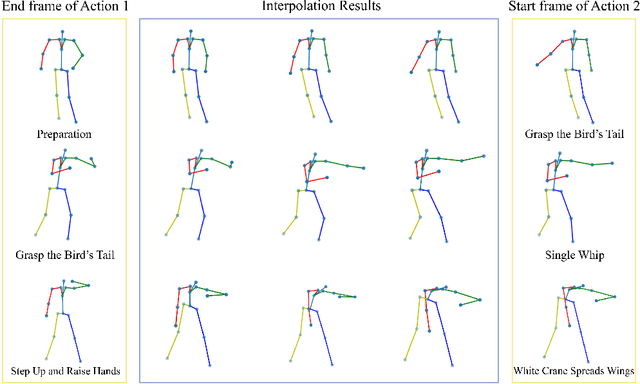
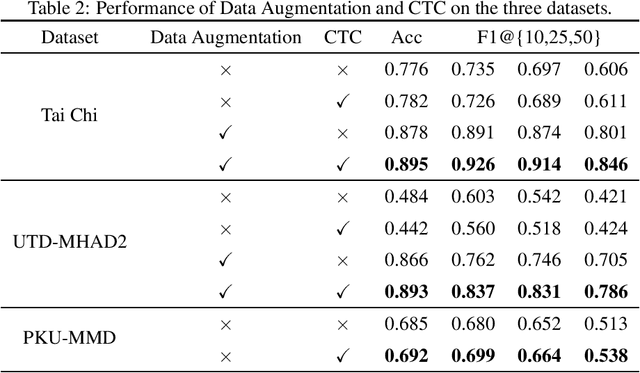
Temporal action segmentation (TAS) aims to classify and locate actions in the long untrimmed action sequence. With the success of deep learning, many deep models for action segmentation have emerged. However, few-shot TAS is still a challenging problem. This study proposes an efficient framework for the few-shot skeleton-based TAS, including a data augmentation method and an improved model. The data augmentation approach based on motion interpolation is presented here to solve the problem of insufficient data, and can increase the number of samples significantly by synthesizing action sequences. Besides, we concatenate a Connectionist Temporal Classification (CTC) layer with a network designed for skeleton-based TAS to obtain an optimized model. Leveraging CTC can enhance the temporal alignment between prediction and ground truth and further improve the segment-wise metrics of segmentation results. Extensive experiments on both public and self-constructed datasets, including two small-scale datasets and one large-scale dataset, show the effectiveness of two proposed methods in improving the performance of the few-shot skeleton-based TAS task.
Automatic dataset generation for specific object detection
Jul 16, 2022



In the past decade, object detection tasks are defined mostly by large public datasets. However, building object detection datasets is not scalable due to inefficient image collecting and labeling. Furthermore, most labels are still in the form of bounding boxes, which provide much less information than the real human visual system. In this paper, we present a method to synthesize object-in-scene images, which can preserve the objects' detailed features without bringing irrelevant information. In brief, given a set of images containing a target object, our algorithm first trains a model to find an approximate center of the object as an anchor, then makes an outline regression to estimate its boundary, and finally blends the object into a new scene. Our result shows that in the synthesized image, the boundaries of objects blend very well with the background. Experiments also show that SOTA segmentation models work well with our synthesized data.
Spatial Transformer Network with Transfer Learning for Small-scale Fine-grained Skeleton-based Tai Chi Action Recognition
Jun 30, 2022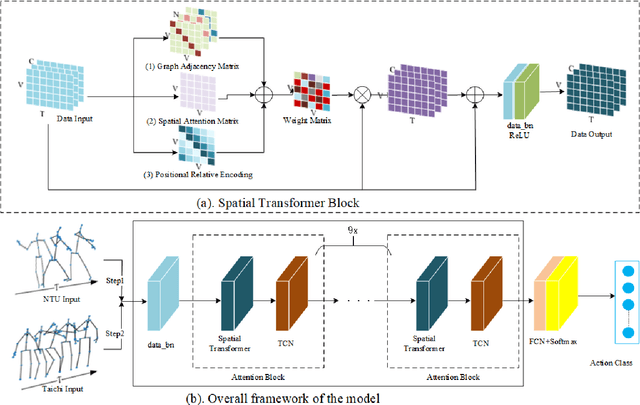

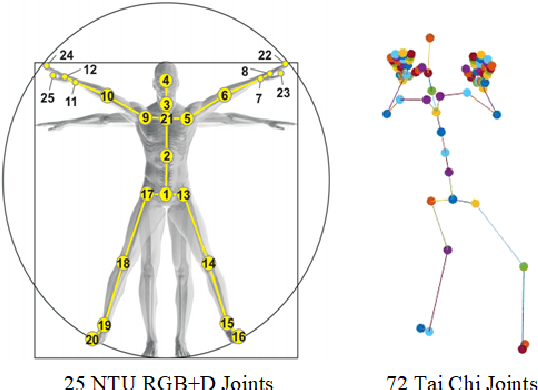
Human action recognition is a quite hugely investigated area where most remarkable action recognition networks usually use large-scale coarse-grained action datasets of daily human actions as inputs to state the superiority of their networks. We intend to recognize our small-scale fine-grained Tai Chi action dataset using neural networks and propose a transfer-learning method using NTU RGB+D dataset to pre-train our network. More specifically, the proposed method first uses a large-scale NTU RGB+D dataset to pre-train the Transformer-based network for action recognition to extract common features among human motion. Then we freeze the network weights except for the fully connected (FC) layer and take our Tai Chi actions as inputs only to train the initialized FC weights. Experimental results show that our general model pipeline can reach a high accuracy of small-scale fine-grained Tai Chi action recognition with even few inputs and demonstrate that our method achieves the state-of-the-art performance compared with previous Tai Chi action recognition methods.