 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFocal Reward: Balanced Reinforcement Learning under Rubric-Based Rewards
May 26, 2026The open-ended generation in LLMs usually requires multi-dimensional rubrics to adequately assess quality and guide the improvement of reinforcement learning. However, a critical dilemma inherent in this training paradigm is the imbalanced reward polarization along different rubric dimensions. Under this bottleneck, even if LLMs achieve relatively high rewards after training, they may still exhibit severe deficiencies in certain dimensions, leading to a direct deterioration in user experience. To address this problem, we propose Focal Reward, a novel objective to automatically balance the training of reinforcement learning under rubric-based rewards. Specifically, we first leverage an inverse reward projection mechanism to estimate the saturation degree of each criterion in the rubric, which forms the basis to calibrate the reward direction. Then, the final objective is designed with an automatically reweighting coefficient for each criterion to achieve the fine-grained balancing. Extensive experiments across three model scales and six benchmarks demonstrate that our Focal Reward method outperforms the strongest static aggregation baseline in all 18 model-benchmark comparisons. Rollout, mechanism, and ablation analyses further show that these gains arise from online, saturation-aware reallocation toward rubrics that still have room for improvement.
Breaking the Generator Barrier: Disentangled Representation for Generalizable AI-Text Detection
Apr 15, 2026As large language models (LLMs) generate text that increasingly resembles human writing, the subtle cues that distinguish AI-generated content from human-written content become increasingly challenging to capture. Reliance on generator-specific artifacts is inherently unstable, since new models emerge rapidly and reduce the robustness of such shortcuts. This generalizes unseen generators as a central and challenging problem for AI-text detection. To tackle this challenge, we propose a progressively structured framework that disentangles AI-detection semantics from generator-aware artifacts. This is achieved through a compact latent encoding that encourages semantic minimality, followed by perturbation-based regularization to reduce residual entanglement, and finally a discriminative adaptation stage that aligns representations with task objectives. Experiments on MAGE benchmark, covering 20 representative LLMs across 7 categories, demonstrate consistent improvements over state-of-the-art methods, achieving up to 24.2% accuracy gain and 26.2% F1 improvement. Notably, performance continues to improve as the diversity of training generators increases, confirming strong scalability and generalization in open-set scenarios. Our source code will be publicly available at https://github.com/PuXiao06/DRGD.
Thinker: Training LLMs in Hierarchical Thinking for Deep Search via Multi-Turn Interaction
Nov 14, 2025
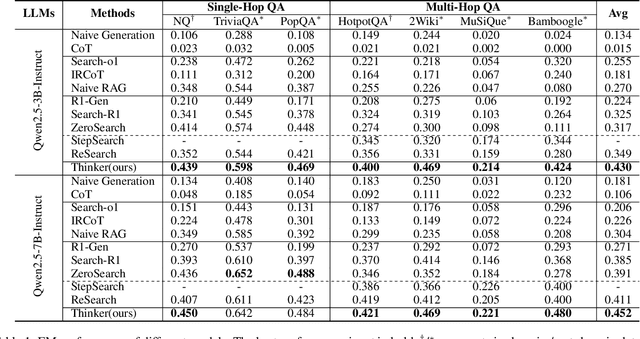
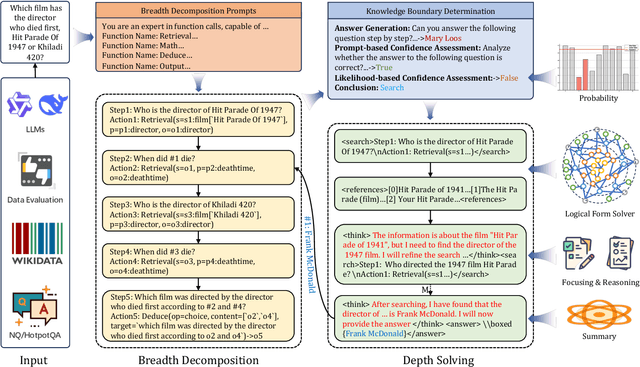
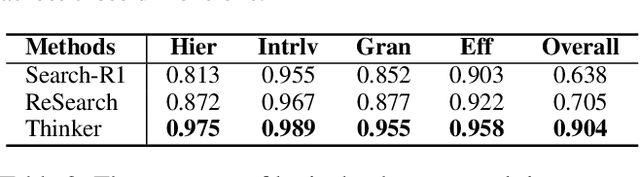
Efficient retrieval of external knowledge bases and web pages is crucial for enhancing the reasoning abilities of LLMs. Previous works on training LLMs to leverage external retrievers for solving complex problems have predominantly employed end-to-end reinforcement learning. However, these approaches neglect supervision over the reasoning process, making it difficult to guarantee logical coherence and rigor. To address these limitations, we propose Thinker, a hierarchical thinking model for deep search through multi-turn interaction, making the reasoning process supervisable and verifiable. It decomposes complex problems into independently solvable sub-problems, each dually represented in both natural language and an equivalent logical function to support knowledge base and web searches. Concurrently, dependencies between sub-problems are passed as parameters via these logical functions, enhancing the logical coherence of the problem-solving process. To avoid unnecessary external searches, we perform knowledge boundary determination to check if a sub-problem is within the LLM's intrinsic knowledge, allowing it to answer directly. Experimental results indicate that with as few as several hundred training samples, the performance of Thinker is competitive with established baselines. Furthermore, when scaled to the full training set, Thinker significantly outperforms these methods across various datasets and model sizes. The source code is available at https://github.com/OpenSPG/KAG-Thinker.
Towards Generalized Proactive Defense against Face Swappingwith Contour-Hybrid Watermark
May 25, 2025Face swapping, recognized as a privacy and security concern, has prompted considerable defensive research. With the advancements in AI-generated content, the discrepancies between the real and swapped faces have become nuanced. Considering the difficulty of forged traces detection, we shift the focus to the face swapping purpose and proactively embed elaborate watermarks against unknown face swapping techniques. Given that the constant purpose is to swap the original face identity while preserving the background, we concentrate on the regions surrounding the face to ensure robust watermark generation, while embedding the contour texture and face identity information to achieve progressive image determination. The watermark is located in the facial contour and contains hybrid messages, dubbed the contour-hybrid watermark (CMark). Our approach generalizes face swapping detection without requiring any swapping techniques during training and the storage of large-scale messages in advance. Experiments conducted across 8 face swapping techniques demonstrate the superiority of our approach compared with state-of-the-art passive and proactive detectors while achieving a favorable balance between the image quality and watermark robustness.
MLEP: Multi-granularity Local Entropy Patterns for Universal AI-generated Image Detection
Apr 18, 2025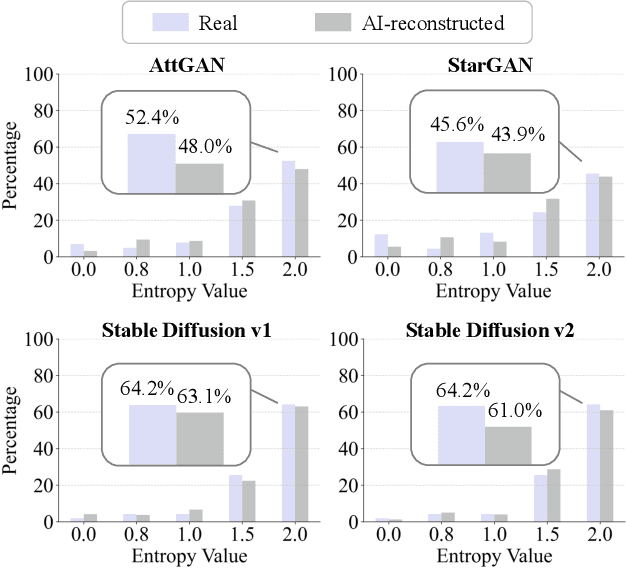
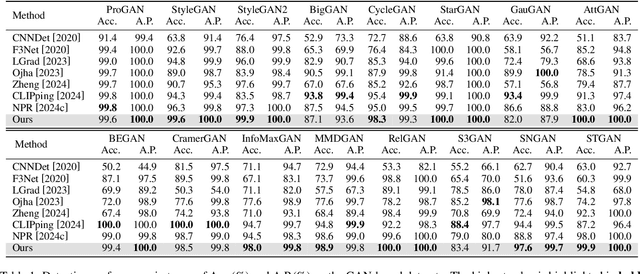
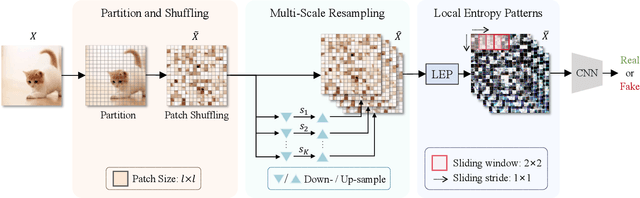
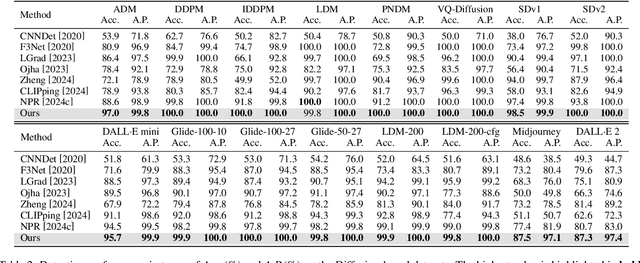
Advancements in image generation technologies have raised significant concerns about their potential misuse, such as producing misinformation and deepfakes. Therefore, there is an urgent need for effective methods to detect AI-generated images (AIGI). Despite progress in AIGI detection, achieving reliable performance across diverse generation models and scenes remains challenging due to the lack of source-invariant features and limited generalization capabilities in existing methods. In this work, we explore the potential of using image entropy as a cue for AIGI detection and propose Multi-granularity Local Entropy Patterns (MLEP), a set of entropy feature maps computed across shuffled small patches over multiple image scaled. MLEP comprehensively captures pixel relationships across dimensions and scales while significantly disrupting image semantics, reducing potential content bias. Leveraging MLEP, a robust CNN-based classifier for AIGI detection can be trained. Extensive experiments conducted in an open-world scenario, evaluating images synthesized by 32 distinct generative models, demonstrate significant improvements over state-of-the-art methods in both accuracy and generalization.
Big Brother is Watching: Proactive Deepfake Detection via Learnable Hidden Face
Apr 15, 2025As deepfake technologies continue to advance, passive detection methods struggle to generalize with various forgery manipulations and datasets. Proactive defense techniques have been actively studied with the primary aim of preventing deepfake operation effectively working. In this paper, we aim to bridge the gap between passive detection and proactive defense, and seek to solve the detection problem utilizing a proactive methodology. Inspired by several watermarking-based forensic methods, we explore a novel detection framework based on the concept of ``hiding a learnable face within a face''. Specifically, relying on a semi-fragile invertible steganography network, a secret template image is embedded into a host image imperceptibly, acting as an indicator monitoring for any malicious image forgery when being restored by the inverse steganography process. Instead of being manually specified, the secret template is optimized during training to resemble a neutral facial appearance, just like a ``big brother'' hidden in the image to be protected. By incorporating a self-blending mechanism and robustness learning strategy with a simulative transmission channel, a robust detector is built to accurately distinguish if the steganographic image is maliciously tampered or benignly processed. Finally, extensive experiments conducted on multiple datasets demonstrate the superiority of the proposed approach over competing passive and proactive detection methods.
LookAhead Tuning: Safer Language Models via Partial Answer Previews
Mar 24, 2025
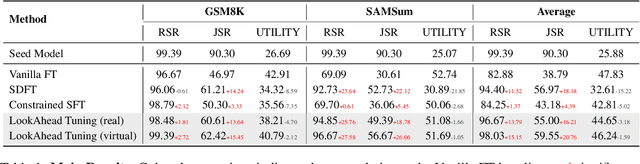
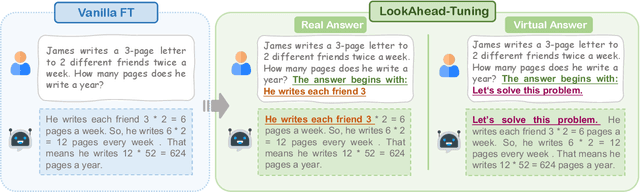
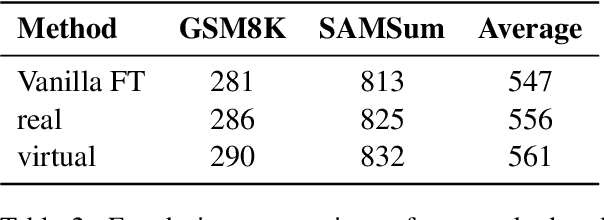
Fine-tuning enables large language models (LLMs) to adapt to specific domains, but often undermines their previously established safety alignment. To mitigate the degradation of model safety during fine-tuning, we introduce LookAhead Tuning, which comprises two simple, low-resource, and effective data-driven methods that modify training data by previewing partial answer prefixes. Both methods aim to preserve the model's inherent safety mechanisms by minimizing perturbations to initial token distributions. Comprehensive experiments demonstrate that LookAhead Tuning effectively maintains model safety without sacrificing robust performance on downstream tasks. Our findings position LookAhead Tuning as a reliable and efficient solution for the safe and effective adaptation of LLMs. Code is released at https://github.com/zjunlp/LookAheadTuning.
Improving Natural Language Understanding for LLMs via Large-Scale Instruction Synthesis
Feb 06, 2025



High-quality, large-scale instructions are crucial for aligning large language models (LLMs), however, there is a severe shortage of instruction in the field of natural language understanding (NLU). Previous works on constructing NLU instructions mainly focus on information extraction (IE), neglecting tasks such as machine reading comprehension, question answering, and text classification. Furthermore, the lack of diversity in the data has led to a decreased generalization ability of trained LLMs in other NLU tasks and a noticeable decline in the fundamental model's general capabilities. To address this issue, we propose Hum, a large-scale, high-quality synthetic instruction corpus for NLU tasks, designed to enhance the NLU capabilities of LLMs. Specifically, Hum includes IE (either close IE or open IE), machine reading comprehension, text classification, and instruction generalist tasks, thereby enriching task diversity. Additionally, we introduce a human-LLMs collaborative mechanism to synthesize instructions, which enriches instruction diversity by incorporating guidelines, preference rules, and format variants. We conduct extensive experiments on 5 NLU tasks and 28 general capability evaluation datasets for LLMs. Experimental results show that Hum enhances the NLU capabilities of six LLMs by an average of 3.1\%, with no significant decline observed in other general capabilities.
iFADIT: Invertible Face Anonymization via Disentangled Identity Transform
Jan 08, 2025Face anonymization aims to conceal the visual identity of a face to safeguard the individual's privacy. Traditional methods like blurring and pixelation can largely remove identifying features, but these techniques significantly degrade image quality and are vulnerable to deep reconstruction attacks. Generative models have emerged as a promising solution for anonymizing faces while preserving a natural appearance.However, many still face limitations in visual quality and often overlook the potential to recover the original face from the anonymized version, which can be valuable in specific contexts such as image forensics. This paper proposes a novel framework named iFADIT, an acronym for Invertible Face Anonymization via Disentangled Identity Transform.The framework features a disentanglement architecture coupled with a secure flow-based model: the former decouples identity information from non-identifying attributes, while the latter transforms the decoupled identity into an anonymized version in an invertible manner controlled by a secret key. The anonymized face can then be reconstructed based on a pre-trained StyleGAN that ensures high image quality and realistic facial details. Recovery of the original face (aka de-anonymization) is possible upon the availability of the matching secret, by inverting the anonymization process based on the same set of model parameters. Furthermore, a dedicated secret-key mechanism along with a dual-phase training strategy is devised to ensure the desired properties of face anonymization. Qualitative and quantitative experiments demonstrate the superiority of the proposed approach in anonymity, reversibility, security, diversity, and interpretability over competing methods.
OneKE: A Dockerized Schema-Guided LLM Agent-based Knowledge Extraction System
Dec 28, 2024


We introduce OneKE, a dockerized schema-guided knowledge extraction system, which can extract knowledge from the Web and raw PDF Books, and support various domains (science, news, etc.). Specifically, we design OneKE with multiple agents and a configure knowledge base. Different agents perform their respective roles, enabling support for various extraction scenarios. The configure knowledge base facilitates schema configuration, error case debugging and correction, further improving the performance. Empirical evaluations on benchmark datasets demonstrate OneKE's efficacy, while case studies further elucidate its adaptability to diverse tasks across multiple domains, highlighting its potential for broad applications. We have open-sourced the Code at https://github.com/zjunlp/OneKE and released a Video at http://oneke.openkg.cn/demo.mp4.