 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Agentic AI System for Multi-Framework Communication Coding
Dec 09, 2025Clinical communication is central to patient outcomes, yet large-scale human annotation of patient-provider conversation remains labor-intensive, inconsistent, and difficult to scale. Existing approaches based on large language models typically rely on single-task models that lack adaptability, interpretability, and reliability, especially when applied across various communication frameworks and clinical domains. In this study, we developed a Multi-framework Structured Agentic AI system for Clinical Communication (MOSAIC), built on a LangGraph-based architecture that orchestrates four core agents, including a Plan Agent for codebook selection and workflow planning, an Update Agent for maintaining up-to-date retrieval databases, a set of Annotation Agents that applies codebook-guided retrieval-augmented generation (RAG) with dynamic few-shot prompting, and a Verification Agent that provides consistency checks and feedback. To evaluate performance, we compared MOSAIC outputs against gold-standard annotations created by trained human coders. We developed and evaluated MOSAIC using 26 gold standard annotated transcripts for training and 50 transcripts for testing, spanning rheumatology and OB/GYN domains. On the test set, MOSAIC achieved an overall F1 score of 0.928. Performance was highest in the Rheumatology subset (F1 = 0.962) and strongest for Patient Behavior (e.g., patients asking questions, expressing preferences, or showing assertiveness). Ablations revealed that MOSAIC outperforms baseline benchmarking.
Exploring Task Performance with Interpretable Models via Sparse Auto-Encoders
Jul 08, 2025



Large Language Models (LLMs) are traditionally viewed as black-box algorithms, therefore reducing trustworthiness and obscuring potential approaches to increasing performance on downstream tasks. In this work, we apply an effective LLM decomposition method using a dictionary-learning approach with sparse autoencoders. This helps extract monosemantic features from polysemantic LLM neurons. Remarkably, our work identifies model-internal misunderstanding, allowing the automatic reformulation of the prompts with additional annotations to improve the interpretation by LLMs. Moreover, this approach demonstrates a significant performance improvement in downstream tasks, such as mathematical reasoning and metaphor detection.
EvolvTrip: Enhancing Literary Character Understanding with Temporal Theory-of-Mind Graphs
Jun 16, 2025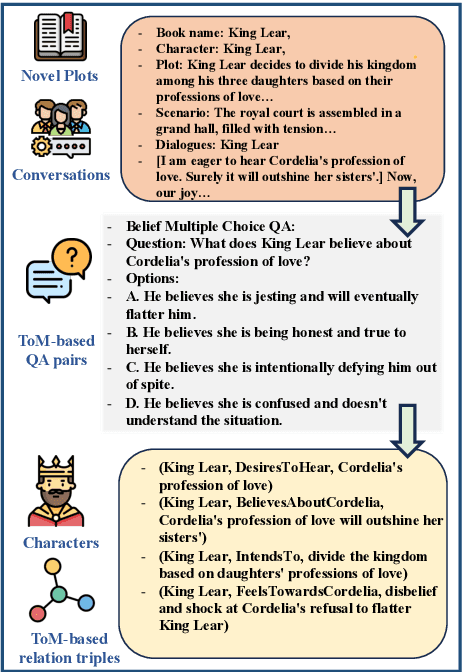
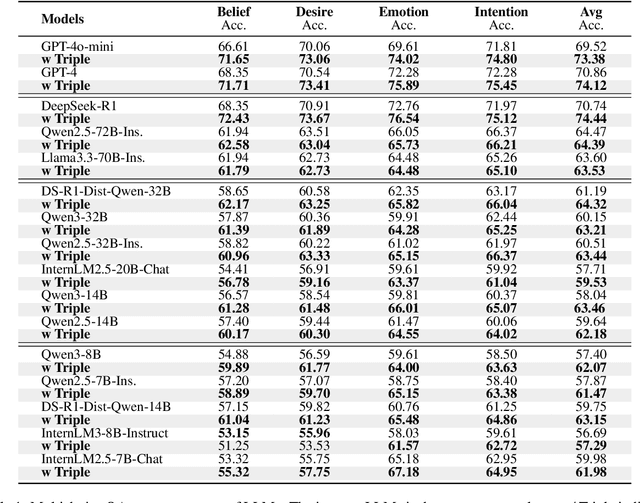
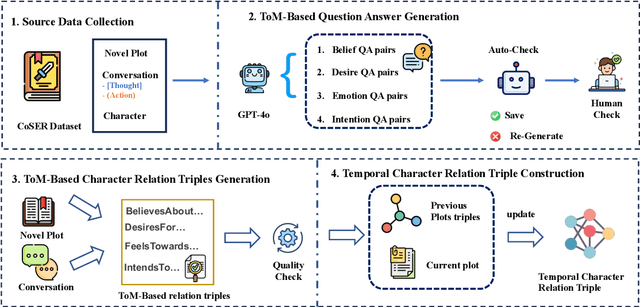
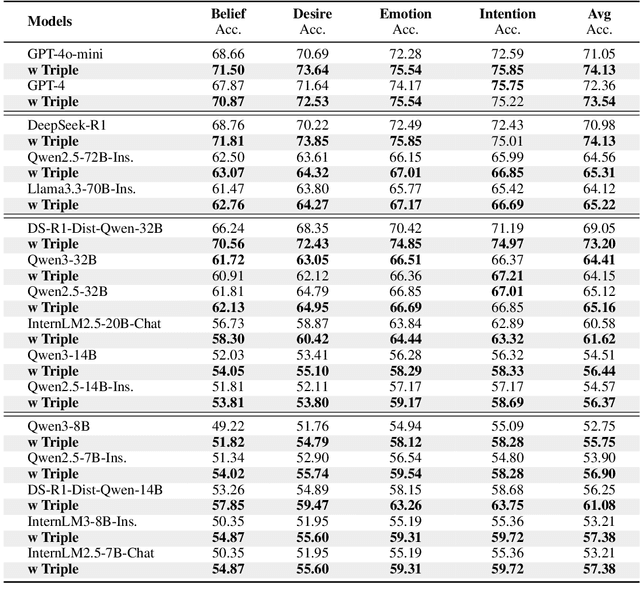
A compelling portrayal of characters is essential to the success of narrative writing. For readers, appreciating a character's traits requires the ability to infer their evolving beliefs, desires, and intentions over the course of a complex storyline, a cognitive skill known as Theory-of-Mind (ToM). Performing ToM reasoning in prolonged narratives requires readers to integrate historical context with current narrative information, a task at which humans excel but Large Language Models (LLMs) often struggle. To systematically evaluate LLMs' ToM reasoning capability in long narratives, we construct LitCharToM, a benchmark of character-centric questions across four ToM dimensions from classic literature. Further, we introduce EvolvTrip, a perspective-aware temporal knowledge graph that tracks psychological development throughout narratives. Our experiments demonstrate that EvolvTrip consistently enhances performance of LLMs across varying scales, even in challenging extended-context scenarios. EvolvTrip proves to be particularly valuable for smaller models, partially bridging the performance gap with larger LLMs and showing great compatibility with lengthy narratives. Our findings highlight the importance of explicit representation of temporal character mental states in narrative comprehension and offer a foundation for more sophisticated character understanding. Our data and code are publicly available at https://github.com/Bernard-Yang/EvolvTrip.
DRE: An Effective Dual-Refined Method for Integrating Small and Large Language Models in Open-Domain Dialogue Evaluation
Jun 04, 2025Large Language Models (LLMs) excel at many tasks but struggle with ambiguous scenarios where multiple valid responses exist, often yielding unreliable results. Conversely, Small Language Models (SLMs) demonstrate robustness in such scenarios but are susceptible to misleading or adversarial inputs. We observed that LLMs handle negative examples effectively, while SLMs excel with positive examples. To leverage their complementary strengths, we introduce SLIDE (Small and Large Integrated for Dialogue Evaluation), a method integrating SLMs and LLMs via adaptive weighting. Building on SLIDE, we further propose a Dual-Refinement Evaluation (DRE) method to enhance SLM-LLM integration: (1) SLM-generated insights guide the LLM to produce initial evaluations; (2) SLM-derived adjustments refine the LLM's scores for improved accuracy. Experiments demonstrate that DRE outperforms existing methods, showing stronger alignment with human judgment across diverse benchmarks. This work illustrates how combining small and large models can yield more reliable evaluation tools, particularly for open-ended tasks such as dialogue evaluation.
GRAPHMOE: Amplifying Cognitive Depth of Mixture-of-Experts Network via Introducing Self-Rethinking Mechanism
Jan 14, 2025



Traditional Mixture-of-Experts (MoE) networks benefit from utilizing multiple smaller expert models as opposed to a single large network. However, these experts typically operate independently, leaving a question open about whether interconnecting these models could enhance the performance of MoE networks. In response, we introduce GRAPHMOE, a novel method aimed at augmenting the cognitive depth of language models via a self-rethinking mechanism constructed on Pseudo GraphMoE networks. GRAPHMOE employs a recurrent routing strategy to simulate iterative thinking steps, thereby facilitating the flow of information among expert nodes. We implement the GRAPHMOE architecture using Low-Rank Adaptation techniques (LoRA) and conduct extensive experiments on various benchmark datasets. The experimental results reveal that GRAPHMOE outperforms other LoRA based models, achieving state-of-the-art (SOTA) performance. Additionally, this study explores a novel recurrent routing strategy that may inspire further advancements in enhancing the reasoning capabilities of language models.
BioMNER: A Dataset for Biomedical Method Entity Recognition
Jun 28, 2024Named entity recognition (NER) stands as a fundamental and pivotal task within the realm of Natural Language Processing. Particularly within the domain of Biomedical Method NER, this task presents notable challenges, stemming from the continual influx of domain-specific terminologies in scholarly literature. Current research in Biomedical Method (BioMethod) NER suffers from a scarcity of resources, primarily attributed to the intricate nature of methodological concepts, which necessitate a profound understanding for precise delineation. In this study, we propose a novel dataset for biomedical method entity recognition, employing an automated BioMethod entity recognition and information retrieval system to assist human annotation. Furthermore, we comprehensively explore a range of conventional and contemporary open-domain NER methodologies, including the utilization of cutting-edge large-scale language models (LLMs) customised to our dataset. Our empirical findings reveal that the large parameter counts of language models surprisingly inhibit the effective assimilation of entity extraction patterns pertaining to biomedical methods. Remarkably, the approach, leveraging the modestly sized ALBERT model (only 11MB), in conjunction with conditional random fields (CRF), achieves state-of-the-art (SOTA) performance.
SimsChat: A Customisable Persona-Driven Role-Playing Agent
Jun 25, 2024Large Language Models (LLMs) possess the remarkable capability to understand human instructions and generate high-quality text, enabling them to act as agents that simulate human behaviours. This capability allows LLMs to emulate human beings in a more advanced manner, beyond merely replicating simple human behaviours. However, there is a lack of exploring into leveraging LLMs to craft characters from several aspects. In this work, we introduce the Customisable Conversation Agent Framework, which employs LLMs to simulate real-world characters that can be freely customised according to different user preferences. The customisable framework is helpful for designing customisable characters and role-playing agents according to human's preferences. We first propose the SimsConv dataset, which comprises 68 different customised characters, 1,360 multi-turn role-playing dialogues, and encompasses 13,971 interaction dialogues in total. The characters are created from several real-world elements, such as career, aspiration, trait, and skill. Building on these foundations, we present SimsChat, a freely customisable role-playing agent. It incorporates different real-world scenes and topic-specific character interaction dialogues, simulating characters' life experiences in various scenarios and topic-specific interactions with specific emotions. Experimental results show that our proposed framework achieves desirable performance and provides helpful guideline for building better simulacra of human beings in the future. Our data and code are available at https://github.com/Bernard-Yang/SimsChat.
X-ray Made Simple: Radiology Report Generation and Evaluation with Layman's Terms
Jun 25, 2024



Radiology Report Generation (RRG) has achieved significant progress with the advancements of multimodal generative models. However, the evaluation in the domain suffers from a lack of fair and robust metrics. We reveal that, high performance on RRG with existing lexical-based metrics (e.g. BLEU) might be more of a mirage - a model can get a high BLEU only by learning the template of reports. This has become an urgent problem for RRG due to the highly patternized nature of these reports. In this work, we un-intuitively approach this problem by proposing the Layman's RRG framework, a layman's terms-based dataset, evaluation and training framework that systematically improves RRG with day-to-day language. We first contribute the translated Layman's terms dataset. Building upon the dataset, we then propose a semantics-based evaluation method, which is proved to mitigate the inflated numbers of BLEU and provides fairer evaluation. Last, we show that training on the layman's terms dataset encourages models to focus on the semantics of the reports, as opposed to overfitting to learning the report templates. We reveal a promising scaling law between the number of training examples and semantics gain provided by our dataset, compared to the inverse pattern brought by the original formats. Our code is available at \url{https://github.com/hegehongcha/LaymanRRG}.
SLIDE: A Framework Integrating Small and Large Language Models for Open-Domain Dialogues Evaluation
May 30, 2024

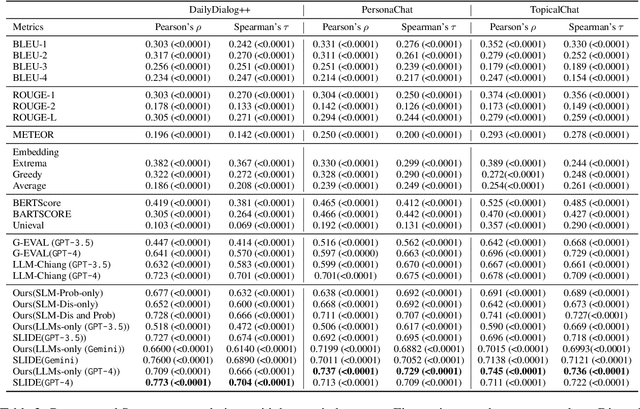

The long-standing one-to-many problem of gold standard responses in open-domain dialogue systems presents challenges for automatic evaluation metrics. Though prior works have demonstrated some success by applying powerful Large Language Models (LLMs), existing approaches still struggle with the one-to-many problem, and exhibit subpar performance in domain-specific scenarios. We assume the commonsense reasoning biases within LLMs may hinder their performance in domainspecific evaluations. To address both issues, we propose a novel framework SLIDE (Small and Large Integrated for Dialogue Evaluation), that leverages both a small, specialised model (SLM), and LLMs for the evaluation of open domain dialogues. Our approach introduces several techniques: (1) Contrastive learning to differentiate between robust and non-robust response embeddings; (2) A novel metric for semantic sensitivity that combines embedding cosine distances with similarity learned through neural networks, and (3) a strategy for incorporating the evaluation results from both the SLM and LLMs. Our empirical results demonstrate that our approach achieves state-of-the-art performance in both the classification and evaluation tasks, and additionally the SLIDE evaluator exhibits better correlation with human judgements. Our code is available at https:// github.com/hegehongcha/SLIDE-ACL2024.
Structured Information Matters: Incorporating Abstract Meaning Representation into LLMs for Improved Open-Domain Dialogue Evaluation
Apr 06, 2024Automatic open-domain dialogue evaluation has attracted increasing attention. Trainable evaluation metrics are commonly trained with true positive and randomly selected negative responses, resulting in a tendency for them to assign a higher score to the responses that share higher content similarity with a given context. However, adversarial negative responses possess high content similarity with the contexts whilst being semantically different. Therefore, existing evaluation metrics are not robust enough to evaluate such responses, resulting in low correlations with human judgments. While recent studies have shown some efficacy in utilizing Large Language Models (LLMs) for open-domain dialogue evaluation, they still encounter challenges in effectively handling adversarial negative examples. In this paper, we propose a simple yet effective framework for open-domain dialogue evaluation, which combines domain-specific language models (SLMs) with LLMs. The SLMs can explicitly incorporate Abstract Meaning Representation (AMR) graph information of the dialogue through a gating mechanism for enhanced semantic representation learning. The evaluation result of SLMs and AMR graph information are plugged into the prompt of LLM, for the enhanced in-context learning performance. Experimental results on open-domain dialogue evaluation tasks demonstrate the superiority of our method compared to a wide range of state-of-the-art baselines, especially in discriminating adversarial negative responses. Our code is available at https://github.com/Bernard-Yang/SIMAMR.