 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeActionNex: A Virtual Outage Manager for Cloud
Apr 03, 2026Outage management in large-scale cloud operations remains heavily manual, requiring rapid triage, cross-team coordination, and experience-driven decisions under partial observability. We present \textbf{ActionNex}, a production-grade agentic system that supports end-to-end outage assistance, including real-time updates, knowledge distillation, and role- and stage-conditioned next-best action recommendations. ActionNex ingests multimodal operational signals (e.g., outage content, telemetry, and human communications) and compresses them into critical events that represent meaningful state transitions. It couples this perception layer with a hierarchical memory subsystem: long-term Key-Condition-Action (KCA) knowledge distilled from playbooks and historical executions, episodic memory of prior outages, and working memory of the live context. A reasoning agent aligns current critical events to preconditions, retrieves relevant memories, and generates actionable recommendations; executed human actions serve as an implicit feedback signal to enable continual self-evolution in a human-agent hybrid system. We evaluate ActionNex on eight real Azure outages (8M tokens, 4,000 critical events) using two complementary ground-truth action sets, achieving 71.4\% precision and 52.8-54.8\% recall. The system has been piloted in production and has received positive early feedback.
Fast Low-light Enhancement and Deblurring for 3D Dark Scenes
Mar 09, 2026Novel view synthesis from low-light, noisy, and motion-blurred imagery remains a valuable and challenging task. Current volumetric rendering methods struggle with compound degradation, and sequential 2D preprocessing introduces artifacts due to interdependencies. In this work, we introduce FLED-GS, a fast low-light enhancement and deblurring framework that reformulates 3D scene restoration as an alternating cycle of enhancement and reconstruction. Specifically, FLED-GS inserts several intermediate brightness anchors to enable progressive recovery, preventing noise blow-up from harming deblurring or geometry. Each iteration sharpens inputs with an off-the-shelf 2D deblurrer and then performs noise-aware 3DGS reconstruction that estimates and suppresses noise while producing clean priors for the next level. Experiments show FLED-GS outperforms state-of-the-art LuSh-NeRF, achieving 21$\times$ faster training and 11$\times$ faster rendering.
Language-Invariant Multilingual Speaker Verification for the TidyVoice 2026 Challenge
Mar 09, 2026Multilingual speaker verification (SV) remains challenging due to limited cross-lingual data and language-dependent information in speaker embeddings. This paper presents a language-invariant multilingual SV system for the TidyVoice 2026 Challenge. We adopt the multilingual self-supervised w2v-BERT 2.0 model as the backbone, enhanced with Layer Adapters and Multi-scale Feature Aggregation to better exploit multi-layer representations. A language-adversarial training strategy with a Gradient Reversal Layer is applied to promote language-invariant speaker embeddings. Moreover, a multilingual zero-shot text-to-speech system is used to synthesize speech in multiple languages, improving language diversity. Experimental results demonstrate that fine-tuning the large-scale pretrained model yields competitive performance, while language-adversarial training further enhances robustness. In addition, synthetic speech augmentation provides additional gains under limited training data conditions. Source code is available at https://github.com/ZXHY-82/LI-MSV-TidyVoice2026.
EvolvTrip: Enhancing Literary Character Understanding with Temporal Theory-of-Mind Graphs
Jun 16, 2025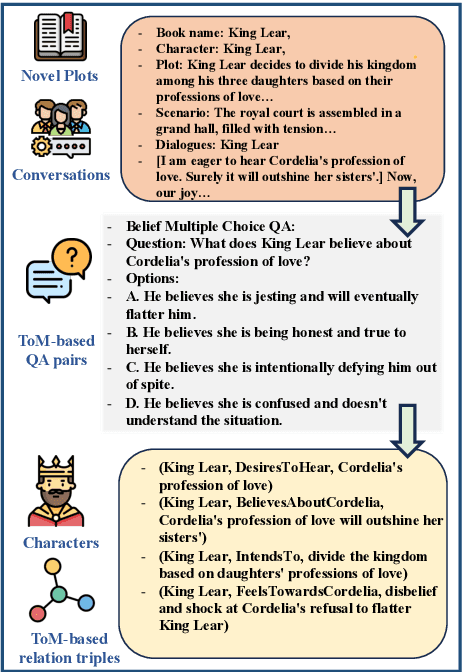
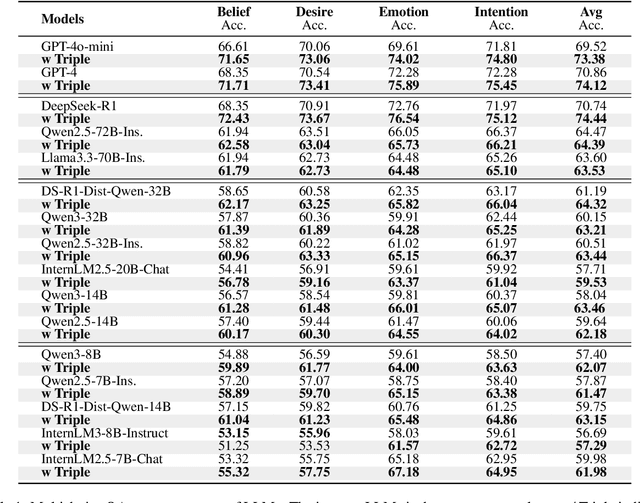
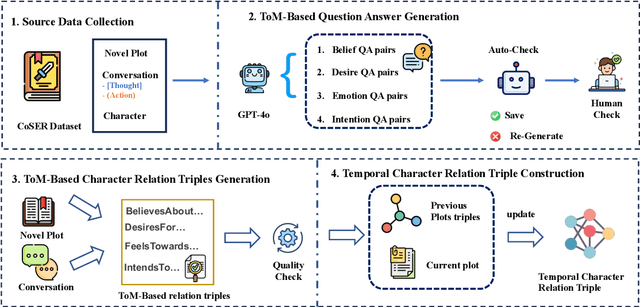
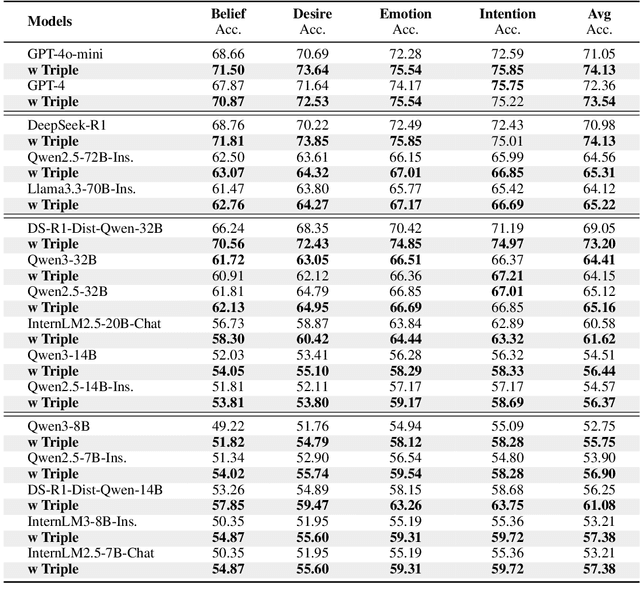
A compelling portrayal of characters is essential to the success of narrative writing. For readers, appreciating a character's traits requires the ability to infer their evolving beliefs, desires, and intentions over the course of a complex storyline, a cognitive skill known as Theory-of-Mind (ToM). Performing ToM reasoning in prolonged narratives requires readers to integrate historical context with current narrative information, a task at which humans excel but Large Language Models (LLMs) often struggle. To systematically evaluate LLMs' ToM reasoning capability in long narratives, we construct LitCharToM, a benchmark of character-centric questions across four ToM dimensions from classic literature. Further, we introduce EvolvTrip, a perspective-aware temporal knowledge graph that tracks psychological development throughout narratives. Our experiments demonstrate that EvolvTrip consistently enhances performance of LLMs across varying scales, even in challenging extended-context scenarios. EvolvTrip proves to be particularly valuable for smaller models, partially bridging the performance gap with larger LLMs and showing great compatibility with lengthy narratives. Our findings highlight the importance of explicit representation of temporal character mental states in narrative comprehension and offer a foundation for more sophisticated character understanding. Our data and code are publicly available at https://github.com/Bernard-Yang/EvolvTrip.
Diarization-Aware Multi-Speaker Automatic Speech Recognition via Large Language Models
Jun 06, 2025Multi-speaker automatic speech recognition (MS-ASR) faces significant challenges in transcribing overlapped speech, a task critical for applications like meeting transcription and conversational analysis. While serialized output training (SOT)-style methods serve as common solutions, they often discard absolute timing information, limiting their utility in time-sensitive scenarios. Leveraging recent advances in large language models (LLMs) for conversational audio processing, we propose a novel diarization-aware multi-speaker ASR system that integrates speaker diarization with LLM-based transcription. Our framework processes structured diarization inputs alongside frame-level speaker and semantic embeddings, enabling the LLM to generate segment-level transcriptions. Experiments demonstrate that the system achieves robust performance in multilingual dyadic conversations and excels in complex, high-overlap multi-speaker meeting scenarios. This work highlights the potential of LLMs as unified back-ends for joint speaker-aware segmentation and transcription.
Robust Low-Light Human Pose Estimation through Illumination-Texture Modulation
Jan 14, 2025



As critical visual details become obscured, the low visibility and high ISO noise in extremely low-light images pose a significant challenge to human pose estimation. Current methods fail to provide high-quality representations due to reliance on pixel-level enhancements that compromise semantics and the inability to effectively handle extreme low-light conditions for robust feature learning. In this work, we propose a frequency-based framework for low-light human pose estimation, rooted in the "divide-and-conquer" principle. Instead of uniformly enhancing the entire image, our method focuses on task-relevant information. By applying dynamic illumination correction to the low-frequency components and low-rank denoising to the high-frequency components, we effectively enhance both the semantic and texture information essential for accurate pose estimation. As a result, this targeted enhancement method results in robust, high-quality representations, significantly improving pose estimation performance. Extensive experiments demonstrating its superiority over state-of-the-art methods in various challenging low-light scenarios.
Adversarial Attacks and Robust Defenses in Speaker Embedding based Zero-Shot Text-to-Speech System
Oct 05, 2024Speaker embedding based zero-shot Text-to-Speech (TTS) systems enable high-quality speech synthesis for unseen speakers using minimal data. However, these systems are vulnerable to adversarial attacks, where an attacker introduces imperceptible perturbations to the original speaker's audio waveform, leading to synthesized speech sounds like another person. This vulnerability poses significant security risks, including speaker identity spoofing and unauthorized voice manipulation. This paper investigates two primary defense strategies to address these threats: adversarial training and adversarial purification. Adversarial training enhances the model's robustness by integrating adversarial examples during the training process, thereby improving resistance to such attacks. Adversarial purification, on the other hand, employs diffusion probabilistic models to revert adversarially perturbed audio to its clean form. Experimental results demonstrate that these defense mechanisms can significantly reduce the impact of adversarial perturbations, enhancing the security and reliability of speaker embedding based zero-shot TTS systems in adversarial environments.
The Database and Benchmark for Source Speaker Verification Against Voice Conversion
Jun 07, 2024


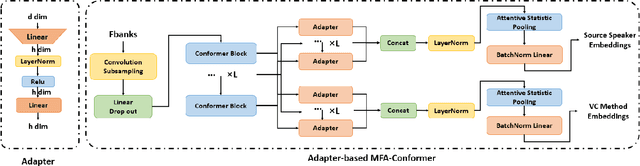
Voice conversion systems can transform audio to mimic another speaker's voice, thereby attacking speaker verification systems. However, ongoing studies on source speaker verification are hindered by limited data availability and methodological constraints. In this paper, we generate a large-scale converted speech database and train a batch of baseline systems based on the MFA-Conformer architecture to promote the source speaker verification task. In addition, we introduce a related task called conversion method recognition. An adapter-based multi-task learning approach is employed to achieve effective conversion method recognition without compromising source speaker verification performance. Additionally, we investigate and effectively address the open-set conversion method recognition problem through the implementation of an open-set nearest neighbor approach.
Positional encoding is not the same as context: A study on positional encoding for Sequential recommendation
May 16, 2024The expansion of streaming media and e-commerce has led to a boom in recommendation systems, including Sequential recommendation systems, which consider the user's previous interactions with items. In recent years, research has focused on architectural improvements such as transformer blocks and feature extraction that can augment model information. Among these features are context and attributes. Of particular importance is the temporal footprint, which is often considered part of the context and seen in previous publications as interchangeable with positional information. Other publications use positional encodings with little attention to them. In this paper, we analyse positional encodings, showing that they provide relative information between items that are not inferable from the temporal footprint. Furthermore, we evaluate different encodings and how they affect metrics and stability using Amazon datasets. We added some new encodings to help with these problems along the way. We found that we can reach new state-of-the-art results by finding the correct positional encoding, but more importantly, certain encodings stabilise the training.
Encoder-Decoder Framework for Interactive Free Verses with Generation with Controllable High-Quality Rhyming
May 08, 2024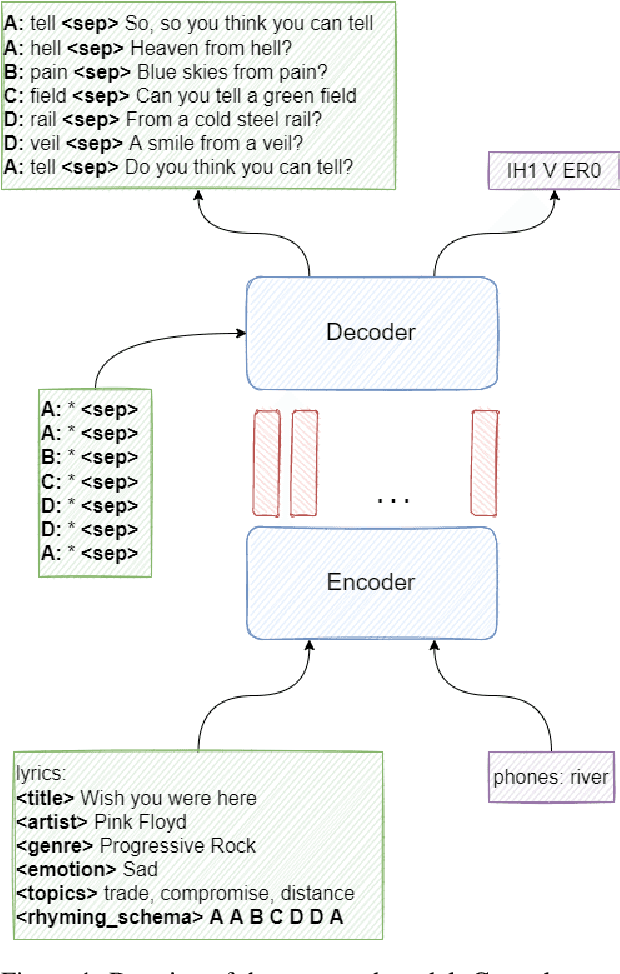
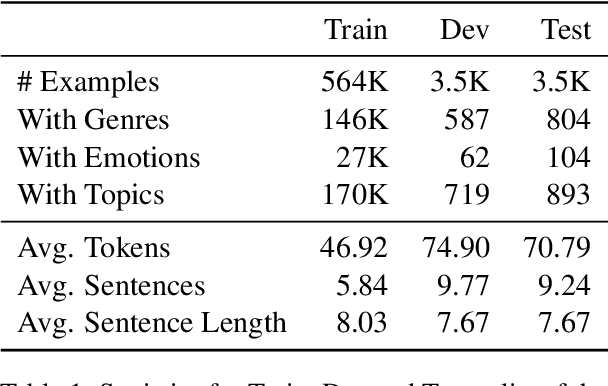
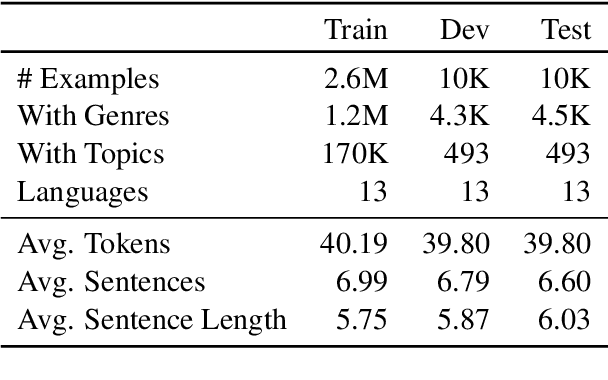
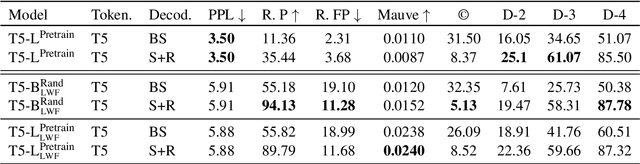
Composing poetry or lyrics involves several creative factors, but a challenging aspect of generation is the adherence to a more or less strict metric and rhyming pattern. To address this challenge specifically, previous work on the task has mainly focused on reverse language modeling, which brings the critical selection of each rhyming word to the forefront of each verse. On the other hand, reversing the word order requires that models be trained from scratch with this task-specific goal and cannot take advantage of transfer learning from a Pretrained Language Model (PLM). We propose a novel fine-tuning approach that prepends the rhyming word at the start of each lyric, which allows the critical rhyming decision to be made before the model commits to the content of the lyric (as during reverse language modeling), but maintains compatibility with the word order of regular PLMs as the lyric itself is still generated in left-to-right order. We conducted extensive experiments to compare this fine-tuning against the current state-of-the-art strategies for rhyming, finding that our approach generates more readable text and better rhyming capabilities. Furthermore, we furnish a high-quality dataset in English and 12 other languages, analyse the approach's feasibility in a multilingual context, provide extensive experimental results shedding light on good and bad practices for lyrics generation, and propose metrics to compare methods in the future.