 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVclip: Face-based Speaker Generation by Face-voice Association Learning
Jan 06, 2026This paper discusses the task of face-based speech synthesis, a kind of personalized speech synthesis where the synthesized voices are constrained to perceptually match with a reference face image. Due to the lack of TTS-quality audio-visual corpora, previous approaches suffer from either low synthesis quality or domain mismatch induced by a knowledge transfer scheme. This paper proposes a new approach called Vclip that utilizes the facial-semantic knowledge of the CLIP encoder on noisy audio-visual data to learn the association between face and voice efficiently, achieving 89.63% cross-modal verification AUC score on Voxceleb testset. The proposed method then uses a retrieval-based strategy, combined with GMM-based speaker generation module for a downstream TTS system, to produce probable target speakers given reference images. Experimental results demonstrate that the proposed Vclip system in conjunction with the retrieval step can bridge the gap between face and voice features for face-based speech synthesis. And using the feedback information distilled from downstream TTS helps to synthesize voices that match closely with reference faces. Demos available at sos1sos2sixteen.github.io/vclip.
The Database and Benchmark for Source Speaker Verification Against Voice Conversion
Jun 07, 2024Voice conversion systems can transform audio to mimic another speaker's voice, thereby attacking speaker verification systems. However, ongoing studies on source speaker verification are hindered by limited data availability and methodological constraints. In this paper, we generate a large-scale converted speech database and train a batch of baseline systems based on the MFA-Conformer architecture to promote the source speaker verification task. In addition, we introduce a related task called conversion method recognition. An adapter-based multi-task learning approach is employed to achieve effective conversion method recognition without compromising source speaker verification performance. Additionally, we investigate and effectively address the open-set conversion method recognition problem through the implementation of an open-set nearest neighbor approach.
Outlier-aware Inlier Modeling and Multi-scale Scoring for Anomalous Sound Detection via Multitask Learning
Sep 14, 2023This paper proposes an approach for anomalous sound detection that incorporates outlier exposure and inlier modeling within a unified framework by multitask learning. While outlier exposure-based methods can extract features efficiently, it is not robust. Inlier modeling is good at generating robust features, but the features are not very effective. Recently, serial approaches are proposed to combine these two methods, but it still requires a separate training step for normal data modeling. To overcome these limitations, we use multitask learning to train a conformer-based encoder for outlier-aware inlier modeling. Moreover, our approach provides multi-scale scores for detecting anomalies. Experimental results on the MIMII and DCASE 2020 task 2 datasets show that our approach outperforms state-of-the-art single-model systems and achieves comparable results with top-ranked multi-system ensembles.
Task-Agnostic Structured Pruning of Speech Representation Models
Jun 02, 2023Self-supervised pre-trained models such as Wav2vec2, Hubert, and WavLM have been shown to significantly improve many speech tasks. However, their large memory and strong computational requirements hinder their industrial applicability. Structured pruning is a hardware-friendly model compression technique but usually results in a larger loss of accuracy. In this paper, we propose a fine-grained attention head pruning method to compensate for the performance degradation. In addition, we also introduce the straight through estimator into the L0 regularization to further accelerate the pruned model. Experiments on the SUPERB benchmark show that our model can achieve comparable performance to the dense model in multiple tasks and outperforms the Wav2vec 2.0 base model on average, with 72% fewer parameters and 2 times faster inference speed.
Multilingual Zero Resource Speech Recognition Base on Self-Supervise Pre-Trained Acoustic Models
Oct 13, 2022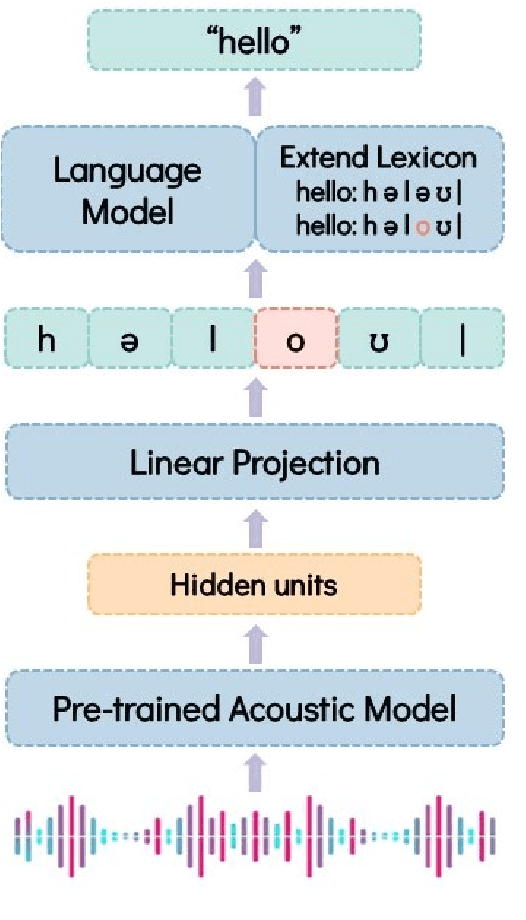


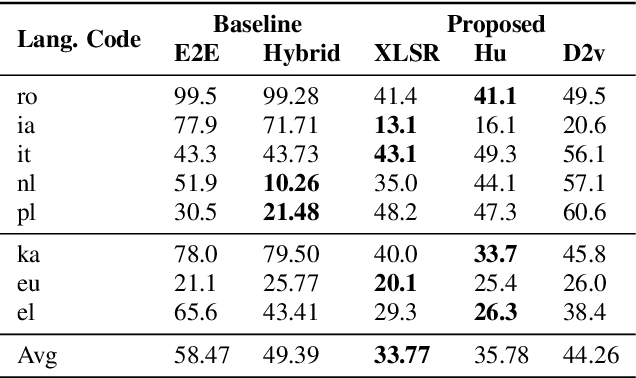
Labeled audio data is insufficient to build satisfying speech recognition systems for most of the languages in the world. There have been some zero-resource methods trying to perform phoneme or word-level speech recognition without labeled audio data of the target language, but the error rate of these methods is usually too high to be applied in real-world scenarios. Recently, the representation ability of self-supervise pre-trained models has been found to be extremely beneficial in zero-resource phoneme recognition. As far as we are concerned, this paper is the first attempt to extend the use of pre-trained models into word-level zero-resource speech recognition. This is done by fine-tuning the pre-trained models on IPA phoneme transcriptions and decoding with a language model trained on extra texts. Experiments on Wav2vec 2.0 and HuBERT models show that this method can achieve less than 20% word error rate on some languages, and the average error rate on 8 languages is 33.77%.
PRISM: Pre-trained Indeterminate Speaker Representation Model for Speaker Diarization and Speaker Verification
May 16, 2022

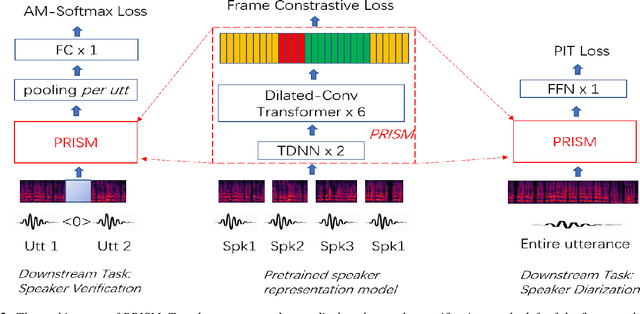

Speaker embedding has been a fundamental feature for speaker-related tasks such as verification, clustering, and diarization. Traditionally, speaker embeddings are represented as fixed vectors in high-dimensional space. This could lead to biased estimations, especially when handling shorter utterances. In this paper we propose to represent a speaker utterance as "floating" vector whose state is indeterminate without knowing the context. The state of a speaker representation is jointly determined by itself, other speech from the same speaker, as well as other speakers it is being compared to. The content of the speech also contributes to determining the final state of a speaker representation. We pre-train an indeterminate speaker representation model that estimates the state of an utterance based on the context. The pre-trained model can be fine-tuned for downstream tasks such as speaker verification, speaker clustering, and speaker diarization. Substantial improvements are observed across all downstream tasks.
Reformulating Speaker Diarization as Community Detection With Emphasis On Topological Structure
Apr 26, 2022
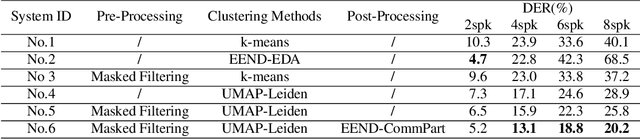


Clustering-based speaker diarization has stood firm as one of the major approaches in reality, despite recent development in end-to-end diarization. However, clustering methods have not been explored extensively for speaker diarization. Commonly-used methods such as k-means, spectral clustering, and agglomerative hierarchical clustering only take into account properties such as proximity and relative densities. In this paper we propose to view clustering-based diarization as a community detection problem. By doing so the topological structure is considered. This work has four major contributions. First it is shown that Leiden community detection algorithm significantly outperforms the previous methods on the clustering of speaker-segments. Second, we propose to use uniform manifold approximation to reduce dimension while retaining global and local topological structure. Third, a masked filtering approach is introduced to extract "clean" speaker embeddings. Finally, the community structure is applied to an end-to-end post-processing network to obtain diarization results. The final system presents a relative DER reduction of up to 70 percent. The breakdown contribution of each component is analyzed.
Graph Convolutional Network Based Semi-Supervised Learning on Multi-Speaker Meeting Data
Apr 25, 2022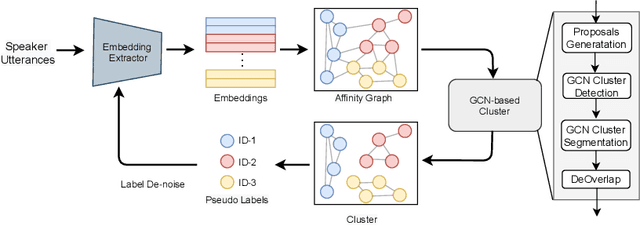

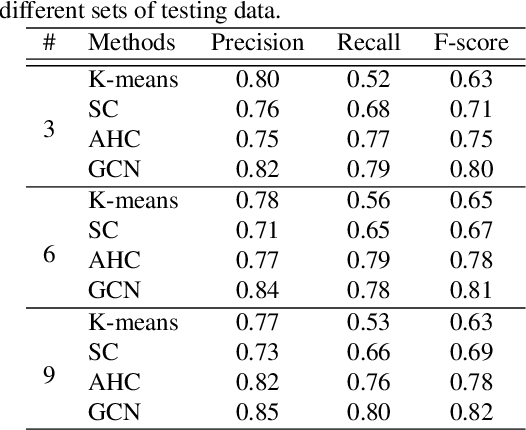

Unsupervised clustering on speakers is becoming increasingly important for its potential uses in semi-supervised learning. In reality, we are often presented with enormous amounts of unlabeled data from multi-party meetings and discussions. An effective unsupervised clustering approach would allow us to significantly increase the amount of training data without additional costs for annotations. Recently, methods based on graph convolutional networks (GCN) have received growing attention for unsupervised clustering, as these methods exploit the connectivity patterns between nodes to improve learning performance. In this work, we present a GCN-based approach for semi-supervised learning. Given a pre-trained embedding extractor, a graph convolutional network is trained on the labeled data and clusters unlabeled data with "pseudo-labels". We present a self-correcting training mechanism that iteratively runs the cluster-train-correct process on pseudo-labels. We show that this proposed approach effectively uses unlabeled data and improves speaker recognition accuracy.
BeamTransformer: Microphone Array-based Overlapping Speech Detection
Sep 09, 2021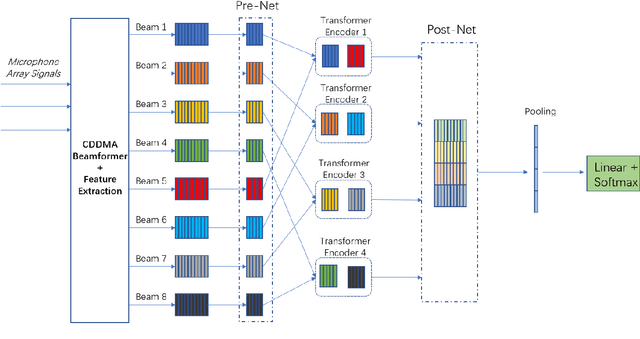

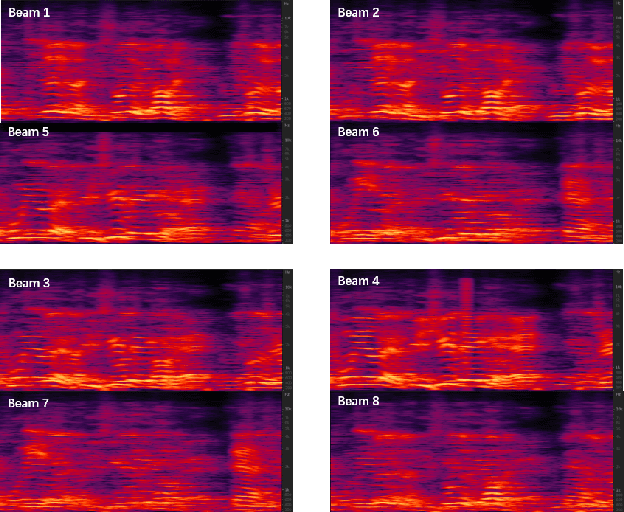
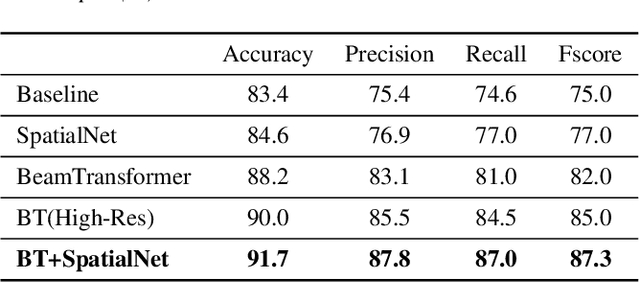
We propose BeamTransformer, an efficient architecture to leverage beamformer's edge in spatial filtering and transformer's capability in context sequence modeling. BeamTransformer seeks to optimize modeling of sequential relationship among signals from different spatial direction. Overlapping speech detection is one of the tasks where such optimization is favorable. In this paper we effectively apply BeamTransformer to detect overlapping segments. Comparing to single-channel approach, BeamTransformer exceeds in learning to identify the relationship among different beam sequences and hence able to make predictions not only from the acoustic signals but also the localization of the source. The results indicate that a successful incorporation of microphone array signals can lead to remarkable gains. Moreover, BeamTransformer takes one step further, as speech from overlapped speakers have been internally separated into different beams.
A Real-time Speaker Diarization System Based on Spatial Spectrum
Jul 20, 2021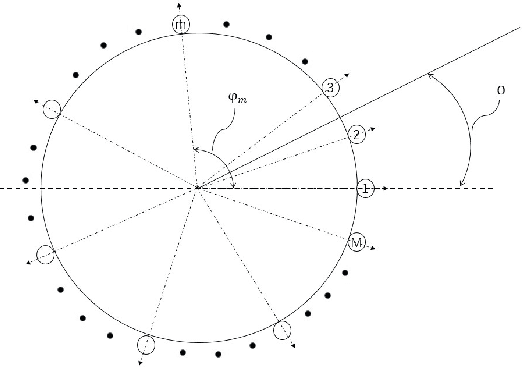

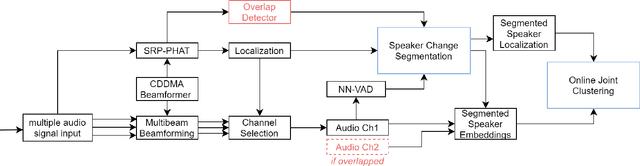

In this paper we describe a speaker diarization system that enables localization and identification of all speakers present in a conversation or meeting. We propose a novel systematic approach to tackle several long-standing challenges in speaker diarization tasks: (1) to segment and separate overlapping speech from two speakers; (2) to estimate the number of speakers when participants may enter or leave the conversation at any time; (3) to provide accurate speaker identification on short text-independent utterances; (4) to track down speakers movement during the conversation; (5) to detect speaker change incidence real-time. First, a differential directional microphone array-based approach is exploited to capture the target speakers' voice in far-field adverse environment. Second, an online speaker-location joint clustering approach is proposed to keep track of speaker location. Third, an instant speaker number detector is developed to trigger the mechanism that separates overlapped speech. The results suggest that our system effectively incorporates spatial information and achieves significant gains.