 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeECHO: Frequency-aware Hierarchical Encoding for Variable-length Signal
Aug 20, 2025Pre-trained foundation models have demonstrated remarkable success in vision and language, yet their potential for general machine signal modeling-covering acoustic, vibration, and other industrial sensor data-remains under-explored. Existing approach using sub-band-based encoders has achieved competitive results but are limited by fixed input lengths, and the absence of explicit frequency positional encoding. In this work, we propose a novel foundation model that integrates an advanced band-split architecture with relative frequency positional embeddings, enabling precise spectral localization across arbitrary sampling configurations. The model supports inputs of arbitrary length without padding or segmentation, producing a concise embedding that retains both temporal and spectral fidelity. We evaluate our method on SIREN (https://github.com/yucongzh/SIREN), a newly introduced large-scale benchmark for machine signal encoding that unifies multiple datasets, including all DCASE task 2 challenges (2020-2025) and widely-used industrial signal corpora. Experimental results demonstrate consistent state-of-the-art performance in anomaly detection and fault identification, confirming the effectiveness and generalization capability of the proposed model. We open-sourced ECHO on https://github.com/yucongzh/ECHO.
Multimodal Laryngoscopic Video Analysis for Assisted Diagnosis of Vocal Cord Paralysis
Sep 05, 2024



This paper presents the Multimodal Analyzing System for Laryngoscope (MASL), a system that combines audio and video data to automatically extract key segments and metrics from laryngeal videostroboscopic videos for clinical assessment. MASL integrates glottis detection with keyword spotting to analyze patient vocalizations and refine video highlights for better inspection of vocal cord movements. The system includes a strobing video extraction module that identifies frames by analyzing hue, saturation, and value fluctuations. MASL also provides effective metrics for vocal cord paralysis detection, employing a two-stage glottis segmentation process using U-Net followed by diffusion-based refinement to reduce false positives. Instead of glottal area waveforms, MASL estimates anterior glottic angle waveforms (AGAW) from glottis masks, evaluating both left and right vocal cords to detect unilateral vocal cord paralysis (UVFP). By comparing AGAW variances, MASL distinguishes between left and right paralysis. Ablation studies and experiments on public and real-world datasets validate MASL's segmentation module and demonstrate its ability to provide reliable metrics for UVFP diagnosis.
A Dual-Path Framework with Frequency-and-Time Excited Network for Anomalous Sound Detection
Sep 05, 2024



In contrast to human speech, machine-generated sounds of the same type often exhibit consistent frequency characteristics and discernible temporal periodicity. However, leveraging these dual attributes in anomaly detection remains relatively under-explored. In this paper, we propose an automated dual-path framework that learns prominent frequency and temporal patterns for diverse machine types. One pathway uses a novel Frequency-and-Time Excited Network (FTE-Net) to learn the salient features across frequency and time axes of the spectrogram. It incorporates a Frequency-and-Time Chunkwise Encoder (FTC-Encoder) and an excitation network. The other pathway uses a 1D convolutional network for utterance-level spectrum. Experimental results on the DCASE 2023 task 2 dataset show the state-of-the-art performance of our proposed method. Moreover, visualizations of the intermediate feature maps in the excitation network are provided to illustrate the effectiveness of our method.
Outlier-aware Inlier Modeling and Multi-scale Scoring for Anomalous Sound Detection via Multitask Learning
Sep 14, 2023This paper proposes an approach for anomalous sound detection that incorporates outlier exposure and inlier modeling within a unified framework by multitask learning. While outlier exposure-based methods can extract features efficiently, it is not robust. Inlier modeling is good at generating robust features, but the features are not very effective. Recently, serial approaches are proposed to combine these two methods, but it still requires a separate training step for normal data modeling. To overcome these limitations, we use multitask learning to train a conformer-based encoder for outlier-aware inlier modeling. Moreover, our approach provides multi-scale scores for detecting anomalies. Experimental results on the MIMII and DCASE 2020 task 2 datasets show that our approach outperforms state-of-the-art single-model systems and achieves comparable results with top-ranked multi-system ensembles.
Target-Speaker Voice Activity Detection via Sequence-to-Sequence Prediction
Nov 03, 2022Target-speaker voice activity detection is currently a promising approach for speaker diarization in complex acoustic environments. This paper presents a novel Sequence-to-Sequence Target-Speaker Voice Activity Detection (Seq2Seq-TSVAD) method that can efficiently address the joint modeling of large-scale speakers and predict high-resolution voice activities. Experimental results show that larger speaker capacity and higher output resolution can significantly reduce the diarization error rate (DER), which achieves the new state-of-the-art performance of 4.55% on the VoxConverse test set and 10.77% on Track 1 of the DIHARD-III evaluation set under the widely-used evaluation metrics.
The DKU-DukeECE Diarization System for the VoxCeleb Speaker Recognition Challenge 2022
Oct 04, 2022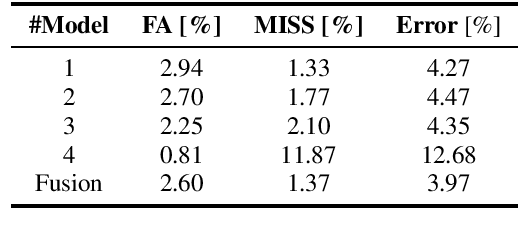

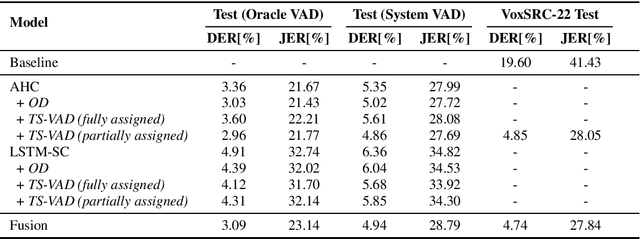
This paper discribes the DKU-DukeECE submission to the 4th track of the VoxCeleb Speaker Recognition Challenge 2022 (VoxSRC-22). Our system contains a fused voice activity detection model, a clustering-based diarization model, and a target-speaker voice activity detection-based overlap detection model. Overall, the submitted system is similar to our previous year's system in VoxSRC-21. The difference is that we use a much better speaker embedding and a fused voice activity detection, which significantly improves the performance. Finally, we fuse 4 different systems using DOVER-lap and achieve 4.75 of the diarization error rate, which ranks the 1st place in track 4.
Online Speaker Diarization with Graph-based Label Generation
Nov 27, 2021



This paper introduces an online speaker diarization system that can handle long-time audio with low latency. First, a new variant of agglomerative hierarchy clustering is built to cluster the speakers in an online fashion. Then, a speaker embedding graph is proposed. We use this graph to exploit a graph-based reclustering method to further improve the performance. Finally, a label matching algorithm is introduced to generate consistent speaker labels, and we evaluate our system on both DIHARD3 and VoxConverse datasets, which contain long audios with various kinds of scenarios. The experimental results show that our online diarization system outperforms the baseline offline system and has comparable performance to our offline system.