 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVclip: Face-based Speaker Generation by Face-voice Association Learning
Jan 06, 2026This paper discusses the task of face-based speech synthesis, a kind of personalized speech synthesis where the synthesized voices are constrained to perceptually match with a reference face image. Due to the lack of TTS-quality audio-visual corpora, previous approaches suffer from either low synthesis quality or domain mismatch induced by a knowledge transfer scheme. This paper proposes a new approach called Vclip that utilizes the facial-semantic knowledge of the CLIP encoder on noisy audio-visual data to learn the association between face and voice efficiently, achieving 89.63% cross-modal verification AUC score on Voxceleb testset. The proposed method then uses a retrieval-based strategy, combined with GMM-based speaker generation module for a downstream TTS system, to produce probable target speakers given reference images. Experimental results demonstrate that the proposed Vclip system in conjunction with the retrieval step can bridge the gap between face and voice features for face-based speech synthesis. And using the feedback information distilled from downstream TTS helps to synthesize voices that match closely with reference faces. Demos available at sos1sos2sixteen.github.io/vclip.
Detecting Emotional Dynamic Trajectories: An Evaluation Framework for Emotional Support in Language Models
Nov 12, 2025



Emotional support is a core capability in human-AI interaction, with applications including psychological counseling, role play, and companionship. However, existing evaluations of large language models (LLMs) often rely on short, static dialogues and fail to capture the dynamic and long-term nature of emotional support. To overcome this limitation, we shift from snapshot-based evaluation to trajectory-based assessment, adopting a user-centered perspective that evaluates models based on their ability to improve and stabilize user emotional states over time. Our framework constructs a large-scale benchmark consisting of 328 emotional contexts and 1,152 disturbance events, simulating realistic emotional shifts under evolving dialogue scenarios. To encourage psychologically grounded responses, we constrain model outputs using validated emotion regulation strategies such as situation selection and cognitive reappraisal. User emotional trajectories are modeled as a first-order Markov process, and we apply causally-adjusted emotion estimation to obtain unbiased emotional state tracking. Based on this framework, we introduce three trajectory-level metrics: Baseline Emotional Level (BEL), Emotional Trajectory Volatility (ETV), and Emotional Centroid Position (ECP). These metrics collectively capture user emotional dynamics over time and support comprehensive evaluation of long-term emotional support performance of LLMs. Extensive evaluations across a diverse set of LLMs reveal significant disparities in emotional support capabilities and provide actionable insights for model development.
Outlier-aware Inlier Modeling and Multi-scale Scoring for Anomalous Sound Detection via Multitask Learning
Sep 14, 2023This paper proposes an approach for anomalous sound detection that incorporates outlier exposure and inlier modeling within a unified framework by multitask learning. While outlier exposure-based methods can extract features efficiently, it is not robust. Inlier modeling is good at generating robust features, but the features are not very effective. Recently, serial approaches are proposed to combine these two methods, but it still requires a separate training step for normal data modeling. To overcome these limitations, we use multitask learning to train a conformer-based encoder for outlier-aware inlier modeling. Moreover, our approach provides multi-scale scores for detecting anomalies. Experimental results on the MIMII and DCASE 2020 task 2 datasets show that our approach outperforms state-of-the-art single-model systems and achieves comparable results with top-ranked multi-system ensembles.
Task-Agnostic Structured Pruning of Speech Representation Models
Jun 02, 2023



Self-supervised pre-trained models such as Wav2vec2, Hubert, and WavLM have been shown to significantly improve many speech tasks. However, their large memory and strong computational requirements hinder their industrial applicability. Structured pruning is a hardware-friendly model compression technique but usually results in a larger loss of accuracy. In this paper, we propose a fine-grained attention head pruning method to compensate for the performance degradation. In addition, we also introduce the straight through estimator into the L0 regularization to further accelerate the pruned model. Experiments on the SUPERB benchmark show that our model can achieve comparable performance to the dense model in multiple tasks and outperforms the Wav2vec 2.0 base model on average, with 72% fewer parameters and 2 times faster inference speed.
Multilingual Zero Resource Speech Recognition Base on Self-Supervise Pre-Trained Acoustic Models
Oct 13, 2022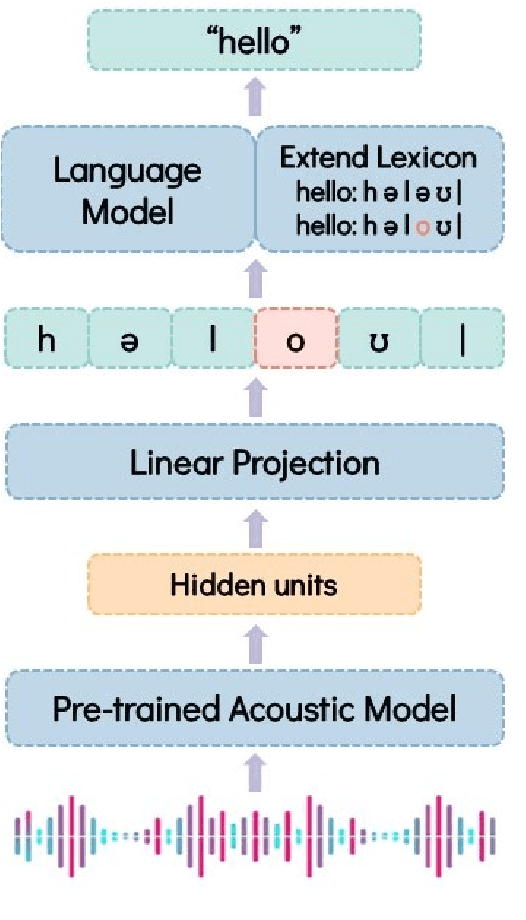


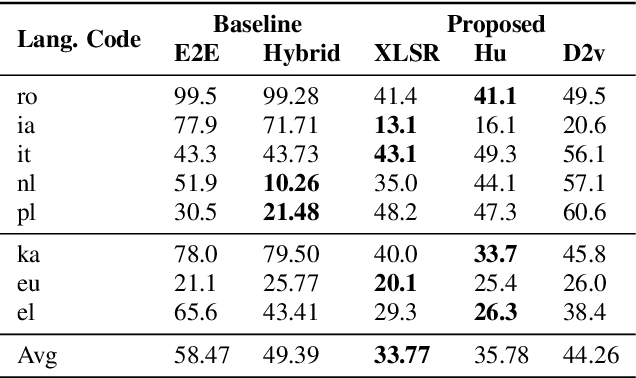
Labeled audio data is insufficient to build satisfying speech recognition systems for most of the languages in the world. There have been some zero-resource methods trying to perform phoneme or word-level speech recognition without labeled audio data of the target language, but the error rate of these methods is usually too high to be applied in real-world scenarios. Recently, the representation ability of self-supervise pre-trained models has been found to be extremely beneficial in zero-resource phoneme recognition. As far as we are concerned, this paper is the first attempt to extend the use of pre-trained models into word-level zero-resource speech recognition. This is done by fine-tuning the pre-trained models on IPA phoneme transcriptions and decoding with a language model trained on extra texts. Experiments on Wav2vec 2.0 and HuBERT models show that this method can achieve less than 20% word error rate on some languages, and the average error rate on 8 languages is 33.77%.