 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMultilingual Zero Resource Speech Recognition Base on Self-Supervise Pre-Trained Acoustic Models
Paper and Code
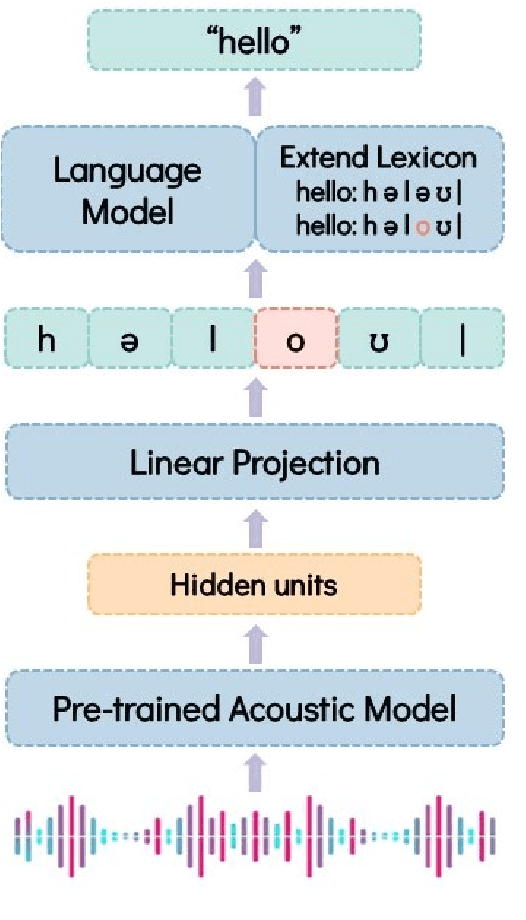


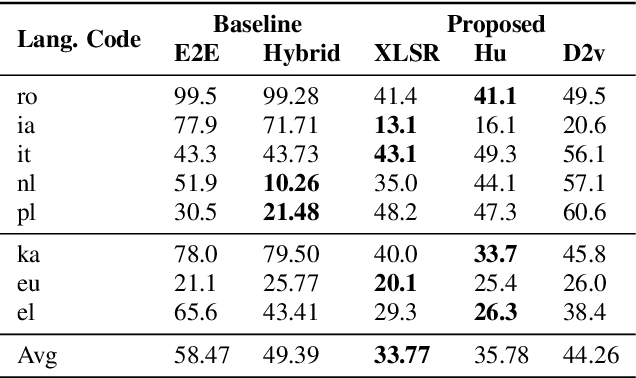
Labeled audio data is insufficient to build satisfying speech recognition systems for most of the languages in the world. There have been some zero-resource methods trying to perform phoneme or word-level speech recognition without labeled audio data of the target language, but the error rate of these methods is usually too high to be applied in real-world scenarios. Recently, the representation ability of self-supervise pre-trained models has been found to be extremely beneficial in zero-resource phoneme recognition. As far as we are concerned, this paper is the first attempt to extend the use of pre-trained models into word-level zero-resource speech recognition. This is done by fine-tuning the pre-trained models on IPA phoneme transcriptions and decoding with a language model trained on extra texts. Experiments on Wav2vec 2.0 and HuBERT models show that this method can achieve less than 20% word error rate on some languages, and the average error rate on 8 languages is 33.77%.