 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeM2S-AVSR: Modality-aware Multi-view Self-supervised Representation for Robust Audio-Visual Speech Recognition
Jun 04, 2026Audio-Visual Speech Recognition (AVSR) enhances speech recognition robustness by leveraging visual cues, while real-world scenarios remain challenging due to viewpoint variation, audio distortion, and visual occlusion, which degrade modality quality and increase audio-visual asynchrony. In this paper, we propose a novel Modality-aware Multi-view Self-supervised representation framework for robust Audio-Visual Speech Recognition (M2S-AVSR). First, we introduce a multi-view representation learning encoder to learn view-invariant visual speech representations. Next, we employ a modality-aware module that explicitly models modality quality and cross-modal synchrony to perform fine-grained modality-aware fusion, enabling fine-grained visual information injection during decoding. In addition, we present AISHELL8-RealScene, a public multi-scenario, multi-view conversational audio-visual dataset recorded in real-world environments, and establish a speech recognition benchmark on it. Experiments on English and Mandarin benchmarks demonstrate the effectiveness of the proposed method under challenging conditions. On LRS3, M2S-AVSR achieves up to 29.4% relative improvement under viewpoint perturbation and visual degradation settings. Our method also achieves new state-of-the-art performance on the MISP2021-AVSR test set. On AISHELL8-RealScene, it achieves the best result in outdoor scenes. The proposed method and dataset provide useful support for future research on robust speech and multimodal tasks under realistic conditions.
DM-ASR: Diarization-aware Multi-speaker ASR with Large Language Models
Apr 24, 2026Multi-speaker automatic speech recognition (ASR) aims to transcribe conversational speech involving multiple speakers, requiring the model to capture not only what was said, but also who said it and sometimes when it was spoken. Recent Speech-LLM approaches have shown the potential of unified modeling for this task, but jointly learning speaker attribution, temporal structure, and lexical recognition remains difficult and data-intensive. At the current stage, leveraging reliable speaker diarization as an explicit structural prior provides a practical and efficient way to simplify this task. To effectively exploit such priors, we propose DM-ASR, a diarization-aware multi-speaker ASR framework that reformulates the task as a multi-turn dialogue generation process. Given an audio chunk and diarization results, DM-ASR decomposes transcription into a sequence of speaker- and time-conditioned queries, each corresponding to one speaker in one time segment. This formulation converts multi-speaker recognition into a series of structured sub-tasks, explicitly decoupling speaker-temporal structure from linguistic content and enabling effective integration of diarization cues with the reasoning capability of large language models. We further introduce an optional word-level timestamp prediction mechanism that interleaves word and timestamp tokens, yielding richer structured outputs and better transcription quality. Our analysis shows that diarization systems provide more reliable speaker identities and segment-level boundaries, while LLMs excel at modeling linguistic content and long-range dependencies, demonstrating their complementary strengths. Experiments on Mandarin and English benchmarks show that the proposed approach achieves strong performance with relatively small models and training data, while remaining competitive with or outperforming existing unified approaches.
Multi-View Based Audio Visual Target Speaker Extraction
Mar 11, 2026Audio-Visual Target Speaker Extraction (AVTSE) aims to separate a target speaker's voice from a mixed audio signal using the corresponding visual cues. While most existing AVTSE methods rely exclusively on frontal-view videos, this limitation restricts their robustness in real-world scenarios where non-frontal views are prevalent. Such visual perspectives often contain complementary articulatory information that could enhance speech extraction. In this work, we propose Multi-View Tensor Fusion (MVTF), a novel framework that transforms multi-view learning into single-view performance gains. During the training stage, we leverage synchronized multi-perspective lip videos to learn cross-view correlations through MVTF, where pairwise outer products explicitly model multiplicative interactions between different views of input lip embeddings. At the inference stage, the system supports both single-view and multi-view inputs. Experimental results show that in the single-view inputs, our framework leverages multi-view knowledge to achieve significant performance gains, while in the multi-view mode, it further improves overall performance and enhances the robustness. Our demo, code and data are available at https://anonymous.4open.science/w/MVTF-Gridnet-209C/
Language-Invariant Multilingual Speaker Verification for the TidyVoice 2026 Challenge
Mar 09, 2026Multilingual speaker verification (SV) remains challenging due to limited cross-lingual data and language-dependent information in speaker embeddings. This paper presents a language-invariant multilingual SV system for the TidyVoice 2026 Challenge. We adopt the multilingual self-supervised w2v-BERT 2.0 model as the backbone, enhanced with Layer Adapters and Multi-scale Feature Aggregation to better exploit multi-layer representations. A language-adversarial training strategy with a Gradient Reversal Layer is applied to promote language-invariant speaker embeddings. Moreover, a multilingual zero-shot text-to-speech system is used to synthesize speech in multiple languages, improving language diversity. Experimental results demonstrate that fine-tuning the large-scale pretrained model yields competitive performance, while language-adversarial training further enhances robustness. In addition, synthetic speech augmentation provides additional gains under limited training data conditions. Source code is available at https://github.com/ZXHY-82/LI-MSV-TidyVoice2026.
Robust LLM-based Audio-Visual Speech Recognition with Sparse Modality Alignment and Visual Unit-Guided Refinement
Mar 04, 2026Audio-Visual Speech Recognition (AVSR) integrates acoustic and visual information to enhance robustness in adverse acoustic conditions. Recent advances in Large Language Models (LLMs) have yielded competitive automatic speech recognition performance and shown effectiveness for AVSR. However, prior approaches project audio and visual features independently or apply shallow fusion, limiting cross-modal alignment and complementary exchange while increasing the LLM's computational load. To address this, we propose AVUR-LLM, an LLM-based Audio-Visual Speech Recognition via Sparse Modality Alignment and Visual Unit-Guided Refinement. Experiments on LRS3 demonstrate state-of-the-art results for AVSR. Under additive-noise conditions at 0 dB SNR, it achieves 37% relative improvement over the baseline system.
Spatially-Augmented Sequence-to-Sequence Neural Diarization for Meetings
Oct 10, 2025This paper proposes a Spatially-Augmented Sequence-to-Sequence Neural Diarization (SA-S2SND) framework, which integrates direction-of-arrival (DOA) cues estimated by SRP-DNN into the S2SND backbone. A two-stage training strategy is adopted: the model is first trained with single-channel audio and DOA features, and then further optimized with multi-channel inputs under DOA guidance. In addition, a simulated DOA generation scheme is introduced to alleviate dependence on matched multi-channel corpora. On the AliMeeting dataset, SA-S2SND consistently outperform the S2SND baseline, achieving a 7.4% relative DER reduction in the offline mode and over 19% improvement when combined with channel attention. These results demonstrate that spatial cues are highly complementary to cross-channel modeling, yielding good performance in both online and offline settings.
ECHO: Frequency-aware Hierarchical Encoding for Variable-length Signal
Aug 20, 2025


Pre-trained foundation models have demonstrated remarkable success in vision and language, yet their potential for general machine signal modeling-covering acoustic, vibration, and other industrial sensor data-remains under-explored. Existing approach using sub-band-based encoders has achieved competitive results but are limited by fixed input lengths, and the absence of explicit frequency positional encoding. In this work, we propose a novel foundation model that integrates an advanced band-split architecture with relative frequency positional embeddings, enabling precise spectral localization across arbitrary sampling configurations. The model supports inputs of arbitrary length without padding or segmentation, producing a concise embedding that retains both temporal and spectral fidelity. We evaluate our method on SIREN (https://github.com/yucongzh/SIREN), a newly introduced large-scale benchmark for machine signal encoding that unifies multiple datasets, including all DCASE task 2 challenges (2020-2025) and widely-used industrial signal corpora. Experimental results demonstrate consistent state-of-the-art performance in anomaly detection and fault identification, confirming the effectiveness and generalization capability of the proposed model. We open-sourced ECHO on https://github.com/yucongzh/ECHO.
SE-VLN: A Self-Evolving Vision-Language Navigation Framework Based on Multimodal Large Language Models
Jul 17, 2025Recent advances in vision-language navigation (VLN) were mainly attributed to emerging large language models (LLMs). These methods exhibited excellent generalization capabilities in instruction understanding and task reasoning. However, they were constrained by the fixed knowledge bases and reasoning abilities of LLMs, preventing fully incorporating experiential knowledge and thus resulting in a lack of efficient evolutionary capacity. To address this, we drew inspiration from the evolution capabilities of natural agents, and proposed a self-evolving VLN framework (SE-VLN) to endow VLN agents with the ability to continuously evolve during testing. To the best of our knowledge, it was the first time that an multimodal LLM-powered self-evolving VLN framework was proposed. Specifically, SE-VLN comprised three core modules, i.e., a hierarchical memory module to transfer successful and failure cases into reusable knowledge, a retrieval-augmented thought-based reasoning module to retrieve experience and enable multi-step decision-making, and a reflection module to realize continual evolution. Comprehensive tests illustrated that the SE-VLN achieved navigation success rates of 57% and 35.2% in unseen environments, representing absolute performance improvements of 23.9% and 15.0% over current state-of-the-art methods on R2R and REVERSE datasets, respectively. Moreover, the SE-VLN showed performance improvement with increasing experience repository, elucidating its great potential as a self-evolving agent framework for VLN.
Self-Supervised and Generalizable Tokenization for CLIP-Based 3D Understanding
May 24, 2025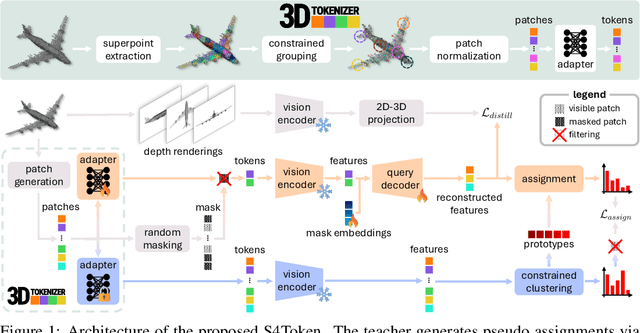


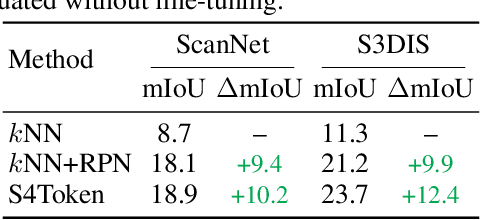
Vision-language models like CLIP can offer a promising foundation for 3D scene understanding when extended with 3D tokenizers. However, standard approaches, such as k-nearest neighbor or radius-based tokenization, struggle with cross-domain generalization due to sensitivity to dataset-specific spatial scales. We present a universal 3D tokenizer designed for scale-invariant representation learning with a frozen CLIP backbone. We show that combining superpoint-based grouping with coordinate scale normalization consistently outperforms conventional methods through extensive experimental analysis. Specifically, we introduce S4Token, a tokenization pipeline that produces semantically-informed tokens regardless of scene scale. Our tokenizer is trained without annotations using masked point modeling and clustering-based objectives, along with cross-modal distillation to align 3D tokens with 2D multi-view image features. For dense prediction tasks, we propose a superpoint-level feature propagation module to recover point-level detail from sparse tokens.
Multi-Channel Sequence-to-Sequence Neural Diarization: Experimental Results for The MISP 2025 Challenge
May 22, 2025This paper describes the speaker diarization system developed for the Multimodal Information-Based Speech Processing (MISP) 2025 Challenge. First, we utilize the Sequence-to-Sequence Neural Diarization (S2SND) framework to generate initial predictions using single-channel audio. Then, we extend the original S2SND framework to create a new version, Multi-Channel Sequence-to-Sequence Neural Diarization (MC-S2SND), which refines the initial results using multi-channel audio. The final system achieves a diarization error rate (DER) of 8.09% on the evaluation set of the competition database, ranking first place in the speaker diarization task of the MISP 2025 Challenge.