 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLoViF 2026 Challenge on Human-oriented Semantic Image Quality Assessment: Methods and Results
Apr 13, 2026This paper reviews the LoViF 2026 Challenge on Human-oriented Semantic Image Quality Assessment. This challenge aims to raise a new direction, i.e., how to evaluate the loss of semantic information from the human perspective, intending to promote the development of some new directions, like semantic coding, processing, and semantic-oriented optimization, etc. Unlike existing datasets of quality assessment, we form a dataset of human-oriented semantic quality assessment, termed the SeIQA dataset. This dataset is divided into three parts for this competition: (i) training data: 510 pairs of degraded images and their corresponding ground truth references; (ii) validation data: 80 pairs of degraded images and their corresponding ground-truth references; (iii) testing data: 160 pairs of degraded images and their corresponding ground-truth references. The primary objective of this challenge is to establish a new and powerful benchmark for human-oriented semantic image quality assessment. There are a total of 58 teams registered in this competition, and 6 teams submitted valid solutions and fact sheets for the final testing phase. These submissions achieved state-of-the-art (SOTA) performance on the SeIQA dataset.
Chatting with Images for Introspective Visual Thinking
Feb 12, 2026Current large vision-language models (LVLMs) typically rely on text-only reasoning based on a single-pass visual encoding, which often leads to loss of fine-grained visual information. Recently the proposal of ''thinking with images'' attempts to alleviate this limitation by manipulating images via external tools or code; however, the resulting visual states are often insufficiently grounded in linguistic semantics, impairing effective cross-modal alignment - particularly when visual semantics or geometric relationships must be reasoned over across distant regions or multiple images. To address these challenges, we propose ''chatting with images'', a new framework that reframes visual manipulation as language-guided feature modulation. Under the guidance of expressive language prompts, the model dynamically performs joint re-encoding over multiple image regions, enabling tighter coupling between linguistic reasoning and visual state updates. We instantiate this paradigm in ViLaVT, a novel LVLM equipped with a dynamic vision encoder explicitly designed for such interactive visual reasoning, and trained it with a two-stage curriculum combining supervised fine-tuning and reinforcement learning to promote effective reasoning behaviors. Extensive experiments across eight benchmarks demonstrate that ViLaVT achieves strong and consistent improvements, with particularly pronounced gains on complex multi-image and video-based spatial reasoning tasks.
LLaDA2.1: Speeding Up Text Diffusion via Token Editing
Feb 09, 2026While LLaDA2.0 showcased the scaling potential of 100B-level block-diffusion models and their inherent parallelization, the delicate equilibrium between decoding speed and generation quality has remained an elusive frontier. Today, we unveil LLaDA2.1, a paradigm shift designed to transcend this trade-off. By seamlessly weaving Token-to-Token (T2T) editing into the conventional Mask-to-Token (M2T) scheme, we introduce a joint, configurable threshold-decoding scheme. This structural innovation gives rise to two distinct personas: the Speedy Mode (S Mode), which audaciously lowers the M2T threshold to bypass traditional constraints while relying on T2T to refine the output; and the Quality Mode (Q Mode), which leans into conservative thresholds to secure superior benchmark performances with manageable efficiency degrade. Furthering this evolution, underpinned by an expansive context window, we implement the first large-scale Reinforcement Learning (RL) framework specifically tailored for dLLMs, anchored by specialized techniques for stable gradient estimation. This alignment not only sharpens reasoning precision but also elevates instruction-following fidelity, bridging the chasm between diffusion dynamics and complex human intent. We culminate this work by releasing LLaDA2.1-Mini (16B) and LLaDA2.1-Flash (100B). Across 33 rigorous benchmarks, LLaDA2.1 delivers strong task performance and lightning-fast decoding speed. Despite its 100B volume, on coding tasks it attains an astounding 892 TPS on HumanEval+, 801 TPS on BigCodeBench, and 663 TPS on LiveCodeBench.
Text as a Universal Interface for Transferable Personalization
Jan 08, 2026We study the problem of personalization in large language models (LLMs). Prior work predominantly represents user preferences as implicit, model-specific vectors or parameters, yielding opaque ``black-box'' profiles that are difficult to interpret and transfer across models and tasks. In contrast, we advocate natural language as a universal, model- and task-agnostic interface for preference representation. The formulation leads to interpretable and reusable preference descriptions, while naturally supporting continual evolution as new interactions are observed. To learn such representations, we introduce a two-stage training framework that combines supervised fine-tuning on high-quality synthesized data with reinforcement learning to optimize long-term utility and cross-task transferability. Based on this framework, we develop AlignXplore+, a universal preference reasoning model that generates textual preference summaries. Experiments on nine benchmarks show that our 8B model achieves state-of-the-art performanc -- outperforming substantially larger open-source models -- while exhibiting strong transferability across tasks, model families, and interaction formats.
Trust-Region Adaptive Policy Optimization
Dec 19, 2025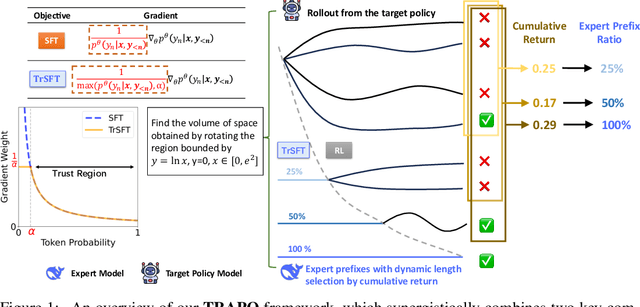
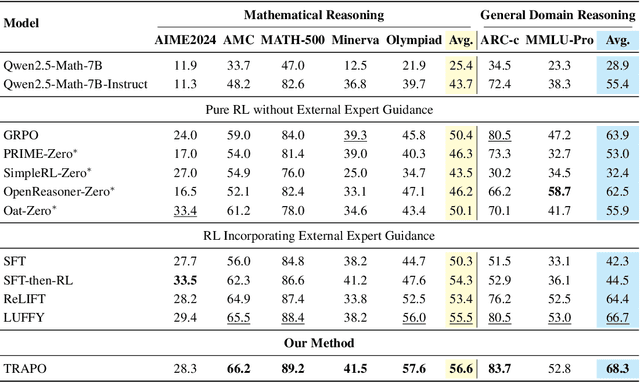
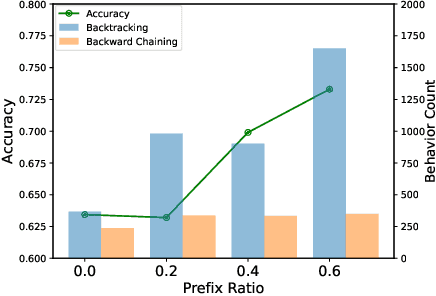

Post-training methods, especially Supervised Fine-Tuning (SFT) and Reinforcement Learning (RL), play an important role in improving large language models' (LLMs) complex reasoning abilities. However, the dominant two-stage pipeline (SFT then RL) suffers from a key inconsistency: SFT enforces rigid imitation that suppresses exploration and induces forgetting, limiting RL's potential for improvements. We address this inefficiency with TRAPO (\textbf{T}rust-\textbf{R}egion \textbf{A}daptive \textbf{P}olicy \textbf{O}ptimization), a hybrid framework that interleaves SFT and RL within each training instance by optimizing SFT loss on expert prefixes and RL loss on the model's own completions, unifying external supervision and self-exploration. To stabilize training, we introduce Trust-Region SFT (TrSFT), which minimizes forward KL divergence inside a trust region but attenuates optimization outside, effectively shifting toward reverse KL and yielding stable, mode-seeking updates favorable for RL. An adaptive prefix-selection mechanism further allocates expert guidance based on measured utility. Experiments on five mathematical reasoning benchmarks show that TRAPO consistently surpasses standard SFT, RL, and SFT-then-RL pipelines, as well as recent state-of-the-art approaches, establishing a strong new paradigm for reasoning-enhanced LLMs.
ReFusion: A Diffusion Large Language Model with Parallel Autoregressive Decoding
Dec 15, 2025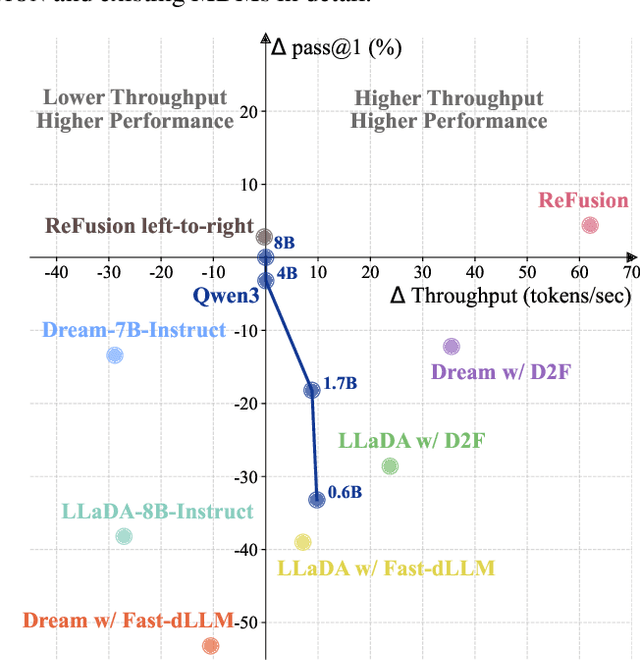
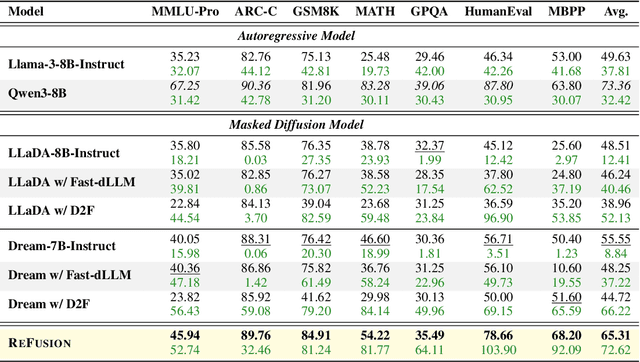
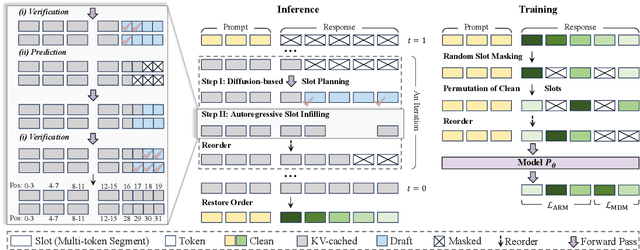
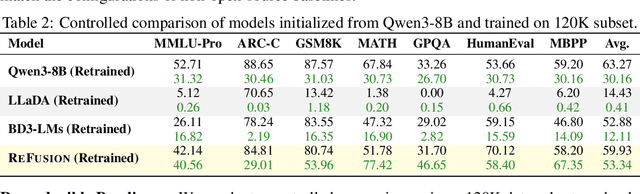
Autoregressive models (ARMs) are hindered by slow sequential inference. While masked diffusion models (MDMs) offer a parallel alternative, they suffer from critical drawbacks: high computational overhead from precluding Key-Value (KV) caching, and incoherent generation arising from learning dependencies over an intractable space of token combinations. To address these limitations, we introduce ReFusion, a novel masked diffusion model that achieves superior performance and efficiency by elevating parallel decoding from the token level to a higher slot level, where each slot is a fixed-length, contiguous sub-sequence. This is achieved through an iterative ``plan-and-infill'' decoding process: a diffusion-based planning step first identifies a set of weakly dependent slots, and an autoregressive infilling step then decodes these selected slots in parallel. The slot-based design simultaneously unlocks full KV cache reuse with a unified causal framework and reduces the learning complexity from the token combination space to a manageable slot-level permutation space. Extensive experiments on seven diverse benchmarks show that ReFusion not only overwhelmingly surpasses prior MDMs with 34% performance gains and an over 18$\times$ speedup on average, but also bridges the performance gap to strong ARMs while maintaining a 2.33$\times$ average speedup.
DynaAct: Large Language Model Reasoning with Dynamic Action Spaces
Nov 11, 2025In modern sequential decision-making systems, the construction of an optimal candidate action space is critical to efficient inference. However, existing approaches either rely on manually defined action spaces that lack scalability or utilize unstructured spaces that render exhaustive search computationally prohibitive. In this paper, we propose a novel framework named \textsc{DynaAct} for automatically constructing a compact action space to enhance sequential reasoning in complex problem-solving scenarios. Our method first estimates a proxy for the complete action space by extracting general sketches observed in a corpus covering diverse complex reasoning problems using large language models. We then formulate a submodular function that jointly evaluates candidate actions based on their utility to the current state and their diversity, and employ a greedy algorithm to select an optimal candidate set. Extensive experiments on six diverse standard benchmarks demonstrate that our approach significantly improves overall performance, while maintaining efficient inference without introducing substantial latency. The implementation is available at https://github.com/zhaoxlpku/DynaAct.
AgentPRM: Process Reward Models for LLM Agents via Step-Wise Promise and Progress
Nov 11, 2025Despite rapid development, large language models (LLMs) still encounter challenges in multi-turn decision-making tasks (i.e., agent tasks) like web shopping and browser navigation, which require making a sequence of intelligent decisions based on environmental feedback. Previous work for LLM agents typically relies on elaborate prompt engineering or fine-tuning with expert trajectories to improve performance. In this work, we take a different perspective: we explore constructing process reward models (PRMs) to evaluate each decision and guide the agent's decision-making process. Unlike LLM reasoning, where each step is scored based on correctness, actions in agent tasks do not have a clear-cut correctness. Instead, they should be evaluated based on their proximity to the goal and the progress they have made. Building on this insight, we propose a re-defined PRM for agent tasks, named AgentPRM, to capture both the interdependence between sequential decisions and their contribution to the final goal. This enables better progress tracking and exploration-exploitation balance. To scalably obtain labeled data for training AgentPRM, we employ a Temporal Difference-based (TD-based) estimation method combined with Generalized Advantage Estimation (GAE), which proves more sample-efficient than prior methods. Extensive experiments across different agentic tasks show that AgentPRM is over $8\times$ more compute-efficient than baselines, and it demonstrates robust improvement when scaling up test-time compute. Moreover, we perform detailed analyses to show how our method works and offer more insights, e.g., applying AgentPRM to the reinforcement learning of LLM agents.
Dual-level Progressive Hardness-Aware Reweighting for Cross-View Geo-Localization
Nov 03, 2025Cross-view geo-localization (CVGL) between drone and satellite imagery remains challenging due to severe viewpoint gaps and the presence of hard negatives, which are visually similar but geographically mismatched samples. Existing mining or reweighting strategies often use static weighting, which is sensitive to distribution shifts and prone to overemphasizing difficult samples too early, leading to noisy gradients and unstable convergence. In this paper, we present a Dual-level Progressive Hardness-aware Reweighting (DPHR) strategy. At the sample level, a Ratio-based Difficulty-Aware (RDA) module evaluates relative difficulty and assigns fine-grained weights to negatives. At the batch level, a Progressive Adaptive Loss Weighting (PALW) mechanism exploits a training-progress signal to attenuate noisy gradients during early optimization and progressively enhance hard-negative mining as training matures. Experiments on the University-1652 and SUES-200 benchmarks demonstrate the effectiveness and robustness of the proposed DPHR, achieving consistent improvements over state-of-the-art methods.
Reinforcing Spatial Reasoning in Vision-Language Models with Interwoven Thinking and Visual Drawing
Jun 11, 2025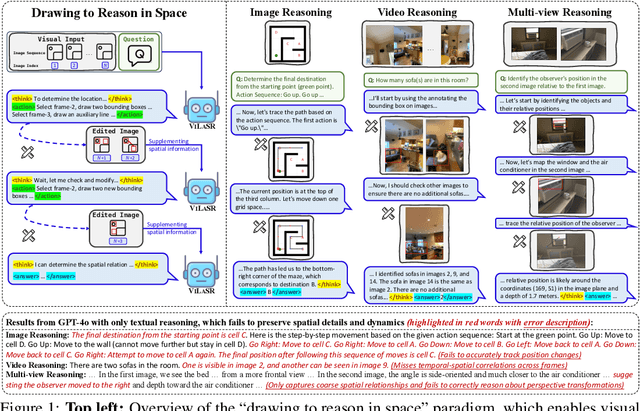
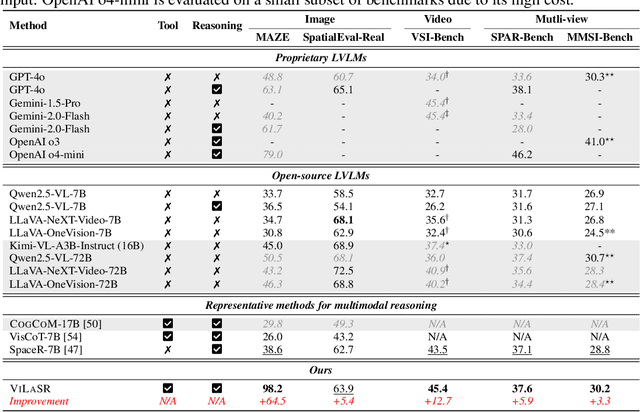
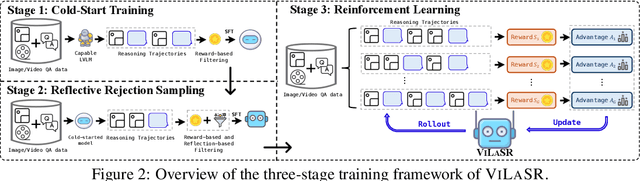

As textual reasoning with large language models (LLMs) has advanced significantly, there has been growing interest in enhancing the multimodal reasoning capabilities of large vision-language models (LVLMs). However, existing methods primarily approach multimodal reasoning in a straightforward, text-centric manner, where both reasoning and answer derivation are conducted purely through text, with the only difference being the presence of multimodal input. As a result, these methods often encounter fundamental limitations in spatial reasoning tasks that demand precise geometric understanding and continuous spatial tracking-capabilities that humans achieve through mental visualization and manipulation. To address the limitations, we propose drawing to reason in space, a novel paradigm that enables LVLMs to reason through elementary drawing operations in the visual space. By equipping models with basic drawing operations, including annotating bounding boxes and drawing auxiliary lines, we empower them to express and analyze spatial relationships through direct visual manipulation, meanwhile avoiding the performance ceiling imposed by specialized perception tools in previous tool-integrated reasoning approaches. To cultivate this capability, we develop a three-stage training framework: cold-start training with synthetic data to establish basic drawing abilities, reflective rejection sampling to enhance self-reflection behaviors, and reinforcement learning to directly optimize for target rewards. Extensive experiments demonstrate that our model, named VILASR, consistently outperforms existing methods across diverse spatial reasoning benchmarks, involving maze navigation, static spatial reasoning, video-based reasoning, and multi-view-based reasoning tasks, with an average improvement of 18.4%.