 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScaling Video-Language Models to 10K Frames via Hierarchical Differential Distillation
Apr 03, 2025Long-form video processing fundamentally challenges vision-language models (VLMs) due to the high computational costs of handling extended temporal sequences. Existing token pruning and feature merging methods often sacrifice critical temporal dependencies or dilute semantic information. We introduce differential distillation, a principled approach that systematically preserves task-relevant information while suppressing redundancy. Based on this principle, we develop ViLaMP, a hierarchical video-language model that processes hour-long videos at ``mixed precision'' through two key mechanisms: (1) differential keyframe selection that maximizes query relevance while maintaining temporal distinctiveness at the frame level and (2) differential feature merging that preserves query-salient features in non-keyframes at the patch level. Hence, ViLaMP retains full information in keyframes while reducing non-keyframes to their most salient features, resembling mixed-precision training. Extensive experiments demonstrate ViLaMP's superior performance across four video understanding benchmarks, particularly on long-form content. Notably, ViLaMP can process ultra-long videos (up to 10K frames) on a single NVIDIA A100 GPU, achieving substantial computational efficiency while maintaining state-of-the-art performance.
From the Least to the Most: Building a Plug-and-Play Visual Reasoner via Data Synthesis
Jun 28, 2024



We explore multi-step reasoning in vision-language models (VLMs). The problem is challenging, as reasoning data consisting of multiple steps of visual and language processing are barely available. To overcome the challenge, we first introduce a least-to-most visual reasoning paradigm, which interleaves steps of decomposing a question into sub-questions and invoking external tools for resolving sub-questions. Based on the paradigm, we further propose a novel data synthesis approach that can automatically create questions and multi-step reasoning paths for an image in a bottom-up manner. Our approach divides the complex synthesis task into a few simple sub-tasks, and (almost entirely) relies on open-sourced models to accomplish the sub-tasks. Therefore, the entire synthesis process is reproducible and cost-efficient, and the synthesized data is quality guaranteed. With the approach, we construct $50$k visual reasoning examples. Then, we develop a visual reasoner through supervised fine-tuning, which is capable of generally enhancing the reasoning abilities of a wide range of existing VLMs in a plug-and-play fashion. Extensive experiments indicate that the visual reasoner can consistently and significantly improve four VLMs on four VQA benchmarks. Our code and dataset are available at https://github.com/steven-ccq/VisualReasoner.
"In Dialogues We Learn": Towards Personalized Dialogue Without Pre-defined Profiles through In-Dialogue Learning
Mar 12, 2024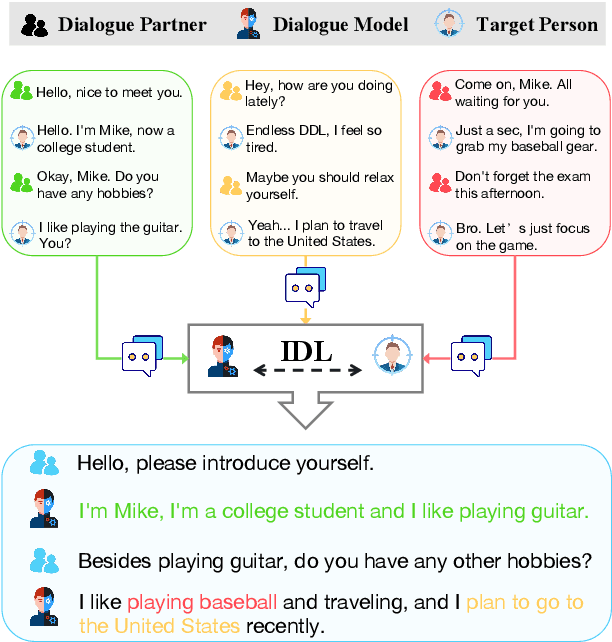
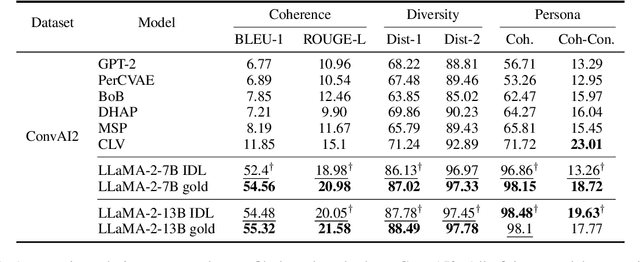
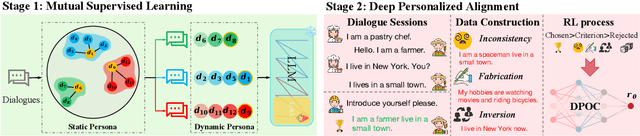
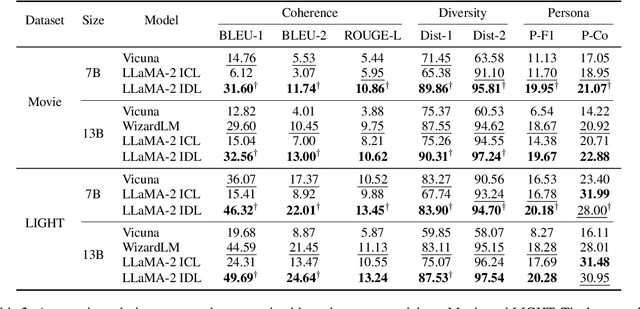
Personalized dialogue systems have gained significant attention in recent years for their ability to generate responses in alignment with different personas. However, most existing approaches rely on pre-defined personal profiles, which are not only time-consuming and labor-intensive to create but also lack flexibility. We propose In-Dialogue Learning (IDL), a fine-tuning framework that enhances the ability of pre-trained large language models to leverage dialogue history to characterize persona for completing personalized dialogue generation tasks without pre-defined profiles. Our experiments on three datasets demonstrate that IDL brings substantial improvements, with BLEU and ROUGE scores increasing by up to 200% and 247%, respectively. Additionally, the results of human evaluations further validate the efficacy of our proposed method.
Scalable Motif Counting for Large-scale Temporal Graphs
Apr 20, 2022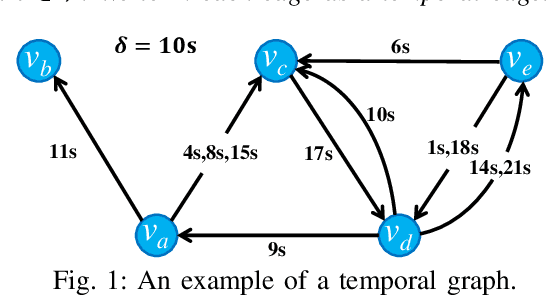
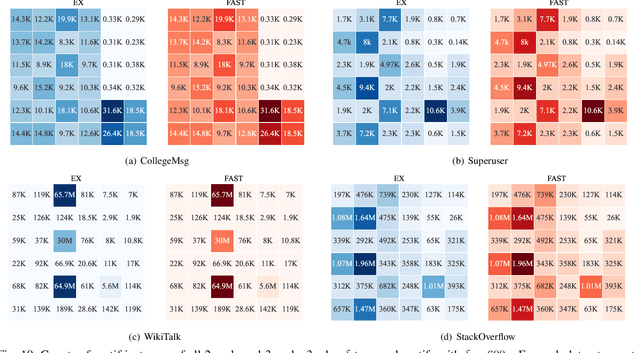
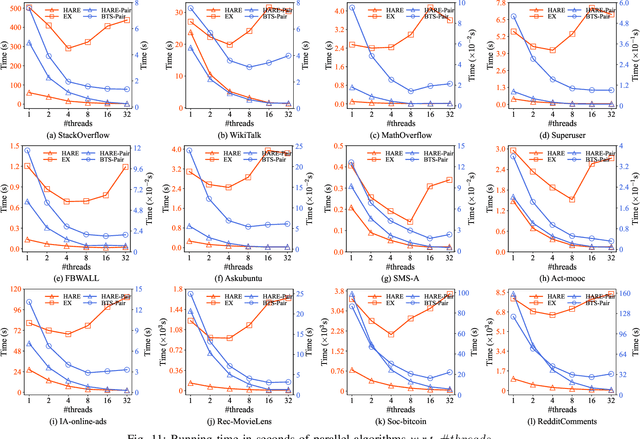
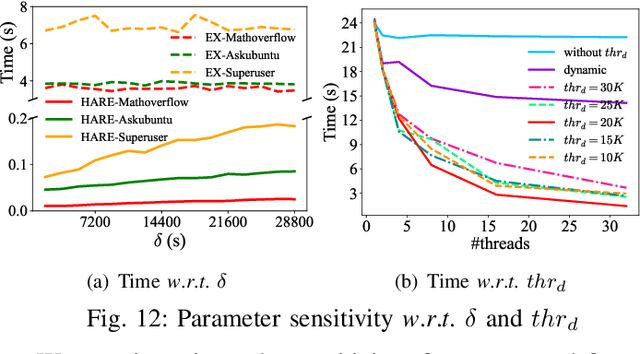
One fundamental problem in temporal graph analysis is to count the occurrences of small connected subgraph patterns (i.e., motifs), which benefits a broad range of real-world applications, such as anomaly detection, structure prediction, and network representation learning. However, existing works focused on exacting temporal motif are not scalable to large-scale temporal graph data, due to their heavy computational costs or inherent inadequacy of parallelism. In this work, we propose a scalable parallel framework for exactly counting temporal motifs in large-scale temporal graphs. We first categorize the temporal motifs based on their distinct properties, and then design customized algorithms that offer efficient strategies to exactly count the motif instances of each category. Moreover, our compact data structures, namely triple and quadruple counters, enable our algorithms to directly identify the temporal motif instances of each category, according to edge information and the relationship between edges, therefore significantly improving the counting efficiency. Based on the proposed counting algorithms, we design a hierarchical parallel framework that features both inter- and intra-node parallel strategies, and fully leverages the multi-threading capacity of modern CPU to concurrently count all temporal motifs. Extensive experiments on sixteen real-world temporal graph datasets demonstrate the superiority and capability of our proposed framework for temporal motif counting, achieving up to 538* speedup compared to the state-of-the-art methods. The source code of our method is available at: https://github.com/steven-ccq/FAST-temporal-motif.