 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBiDeV: Bilateral Defusing Verification for Complex Claim Fact-Checking
Feb 22, 2025

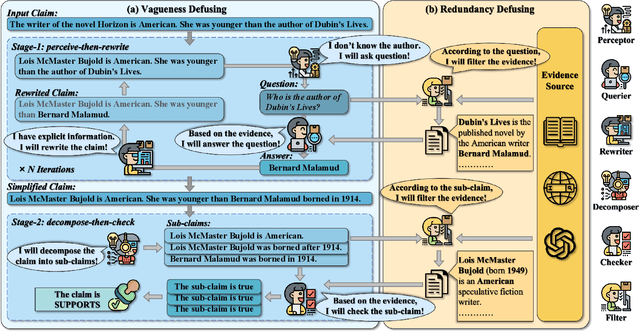
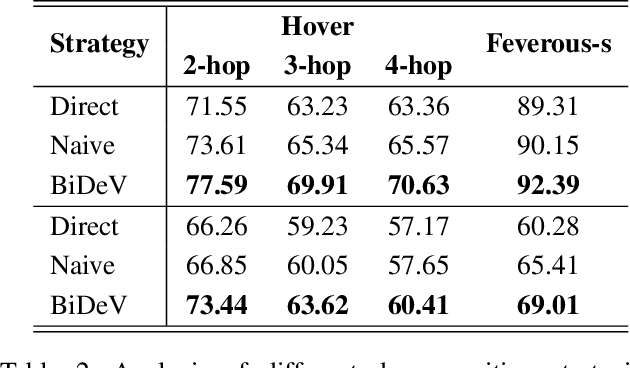
Complex claim fact-checking performs a crucial role in disinformation detection. However, existing fact-checking methods struggle with claim vagueness, specifically in effectively handling latent information and complex relations within claims. Moreover, evidence redundancy, where nonessential information complicates the verification process, remains a significant issue. To tackle these limitations, we propose Bilateral Defusing Verification (BiDeV), a novel fact-checking working-flow framework integrating multiple role-played LLMs to mimic the human-expert fact-checking process. BiDeV consists of two main modules: Vagueness Defusing identifies latent information and resolves complex relations to simplify the claim, and Redundancy Defusing eliminates redundant content to enhance the evidence quality. Extensive experimental results on two widely used challenging fact-checking benchmarks (Hover and Feverous-s) demonstrate that our BiDeV can achieve the best performance under both gold and open settings. This highlights the effectiveness of BiDeV in handling complex claims and ensuring precise fact-checking
StreamingDialogue: Prolonged Dialogue Learning via Long Context Compression with Minimal Losses
Mar 13, 2024Standard Large Language Models (LLMs) struggle with handling dialogues with long contexts due to efficiency and consistency issues. According to our observation, dialogue contexts are highly structured, and the special token of \textit{End-of-Utterance} (EoU) in dialogues has the potential to aggregate information. We refer to the EoU tokens as ``conversational attention sinks'' (conv-attn sinks). Accordingly, we introduce StreamingDialogue, which compresses long dialogue history into conv-attn sinks with minimal losses, and thus reduces computational complexity quadratically with the number of sinks (i.e., the number of utterances). Current LLMs already demonstrate the ability to handle long context window, e.g., a window size of 200k or more. To this end, by compressing utterances into EoUs, our method has the potential to handle more than 200k of utterances, resulting in a prolonged dialogue learning. In order to minimize information losses from reconstruction after compression, we design two learning strategies of short-memory reconstruction (SMR) and long-memory reactivation (LMR). Our method outperforms strong baselines in dialogue tasks and achieves a 4 $\times$ speedup while reducing memory usage by 18 $\times$ compared to dense attention recomputation.
"In Dialogues We Learn": Towards Personalized Dialogue Without Pre-defined Profiles through In-Dialogue Learning
Mar 12, 2024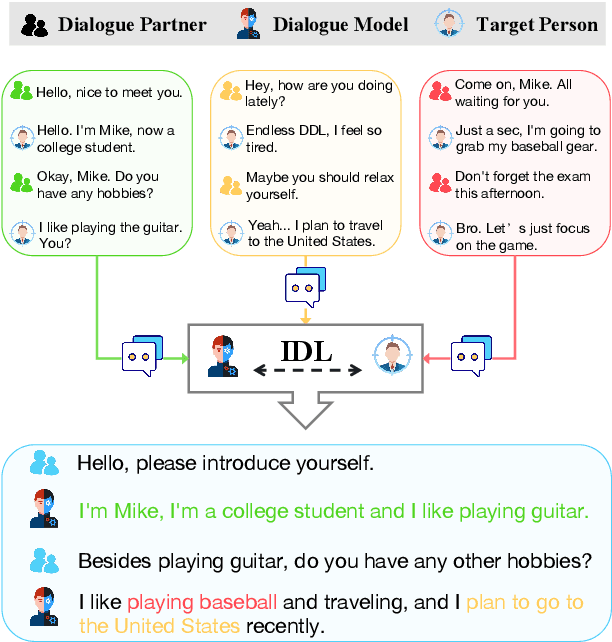
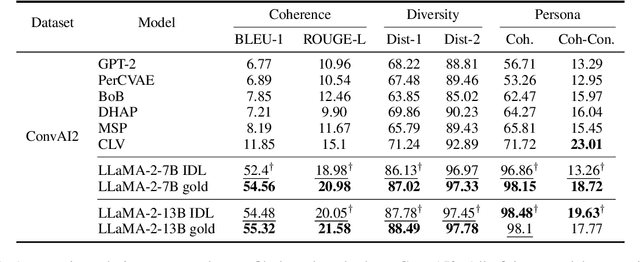
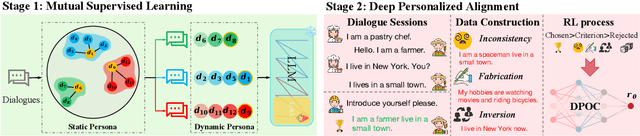
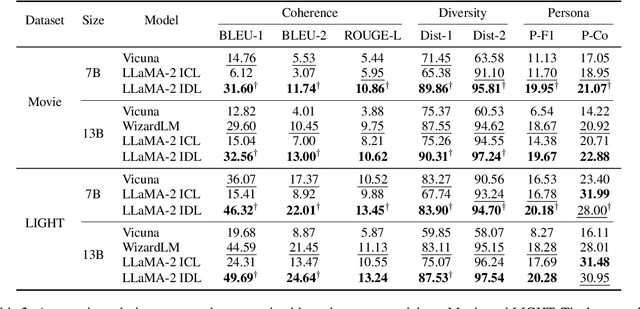
Personalized dialogue systems have gained significant attention in recent years for their ability to generate responses in alignment with different personas. However, most existing approaches rely on pre-defined personal profiles, which are not only time-consuming and labor-intensive to create but also lack flexibility. We propose In-Dialogue Learning (IDL), a fine-tuning framework that enhances the ability of pre-trained large language models to leverage dialogue history to characterize persona for completing personalized dialogue generation tasks without pre-defined profiles. Our experiments on three datasets demonstrate that IDL brings substantial improvements, with BLEU and ROUGE scores increasing by up to 200% and 247%, respectively. Additionally, the results of human evaluations further validate the efficacy of our proposed method.