 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeText as a Universal Interface for Transferable Personalization
Jan 08, 2026We study the problem of personalization in large language models (LLMs). Prior work predominantly represents user preferences as implicit, model-specific vectors or parameters, yielding opaque ``black-box'' profiles that are difficult to interpret and transfer across models and tasks. In contrast, we advocate natural language as a universal, model- and task-agnostic interface for preference representation. The formulation leads to interpretable and reusable preference descriptions, while naturally supporting continual evolution as new interactions are observed. To learn such representations, we introduce a two-stage training framework that combines supervised fine-tuning on high-quality synthesized data with reinforcement learning to optimize long-term utility and cross-task transferability. Based on this framework, we develop AlignXplore+, a universal preference reasoning model that generates textual preference summaries. Experiments on nine benchmarks show that our 8B model achieves state-of-the-art performanc -- outperforming substantially larger open-source models -- while exhibiting strong transferability across tasks, model families, and interaction formats.
ReFusion: A Diffusion Large Language Model with Parallel Autoregressive Decoding
Dec 15, 2025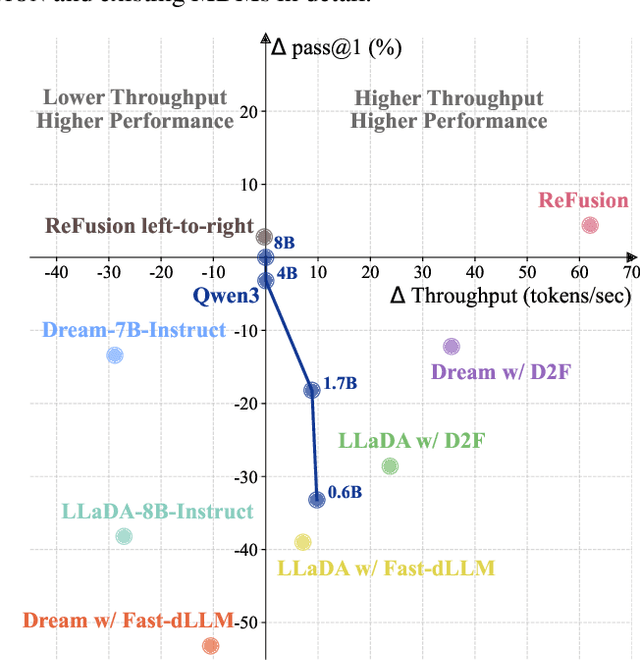
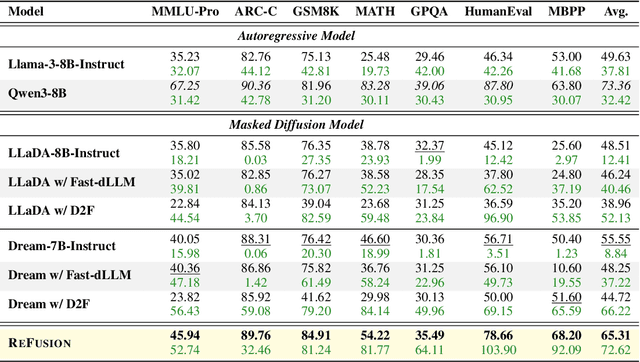
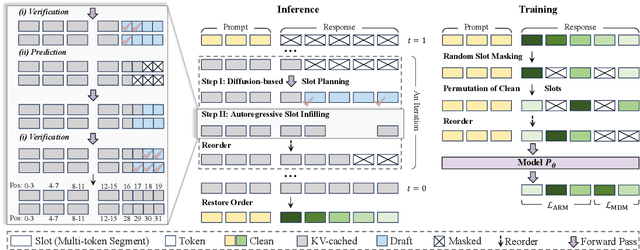
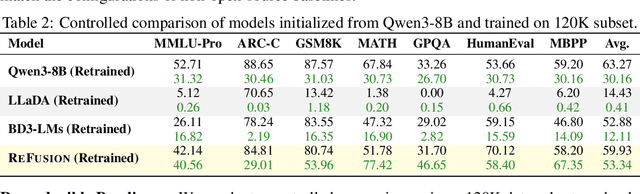
Autoregressive models (ARMs) are hindered by slow sequential inference. While masked diffusion models (MDMs) offer a parallel alternative, they suffer from critical drawbacks: high computational overhead from precluding Key-Value (KV) caching, and incoherent generation arising from learning dependencies over an intractable space of token combinations. To address these limitations, we introduce ReFusion, a novel masked diffusion model that achieves superior performance and efficiency by elevating parallel decoding from the token level to a higher slot level, where each slot is a fixed-length, contiguous sub-sequence. This is achieved through an iterative ``plan-and-infill'' decoding process: a diffusion-based planning step first identifies a set of weakly dependent slots, and an autoregressive infilling step then decodes these selected slots in parallel. The slot-based design simultaneously unlocks full KV cache reuse with a unified causal framework and reduces the learning complexity from the token combination space to a manageable slot-level permutation space. Extensive experiments on seven diverse benchmarks show that ReFusion not only overwhelmingly surpasses prior MDMs with 34% performance gains and an over 18$\times$ speedup on average, but also bridges the performance gap to strong ARMs while maintaining a 2.33$\times$ average speedup.
Extended Inductive Reasoning for Personalized Preference Inference from Behavioral Signals
May 23, 2025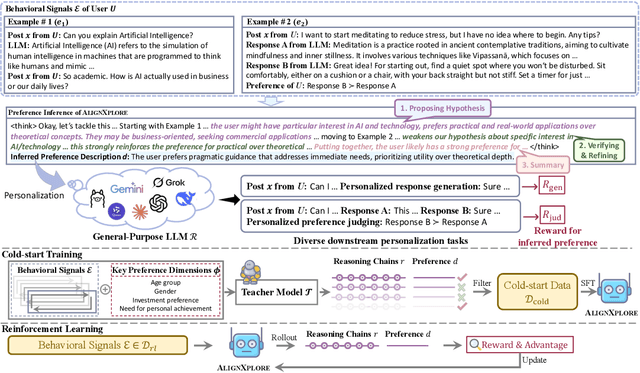

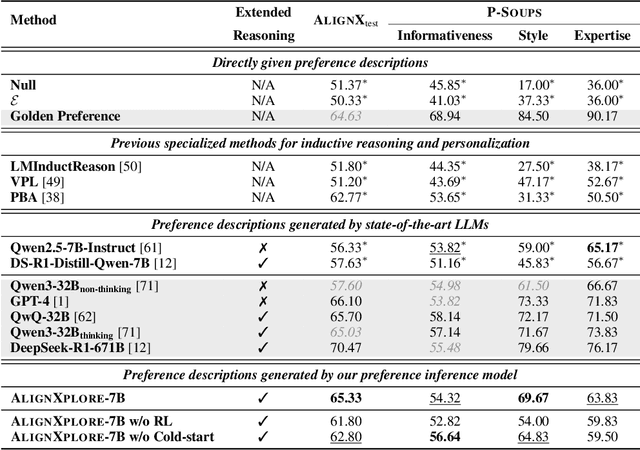
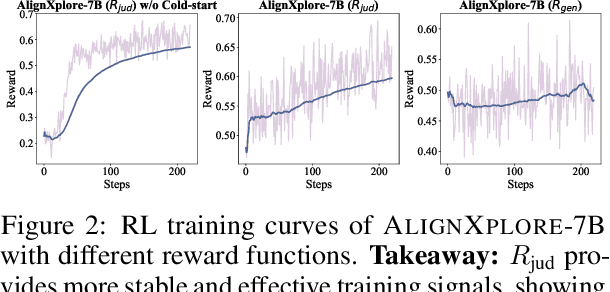
Large language models (LLMs) have demonstrated significant success in complex reasoning tasks such as math and coding. In contrast to these tasks where deductive reasoning predominates, inductive reasoning\textemdash the ability to derive general rules from incomplete evidence, remains underexplored. This paper investigates extended inductive reasoning in LLMs through the lens of personalized preference inference, a critical challenge in LLM alignment where current approaches struggle to capture diverse user preferences. The task demands strong inductive reasoning capabilities as user preferences are typically embedded implicitly across various interaction forms, requiring models to synthesize consistent preference patterns from scattered signals. We propose \textsc{AlignXplore}, a model that leverages extended reasoning chains to enable systematic preference inference from behavioral signals in users' interaction histories. We develop \textsc{AlignXplore} by combining cold-start training based on synthetic data with subsequent online reinforcement learning. Through extensive experiments, we demonstrate that \textsc{AlignXplore} achieves substantial improvements over the backbone model by an average of 11.05\% on in-domain and out-of-domain benchmarks, while maintaining strong generalization ability across different input formats and downstream models. Further analyses establish best practices for preference inference learning through systematic comparison of reward modeling strategies, while revealing the emergence of human-like inductive reasoning patterns during training.
From 1,000,000 Users to Every User: Scaling Up Personalized Preference for User-level Alignment
Mar 21, 2025



Large language models (LLMs) have traditionally been aligned through one-size-fits-all approaches that assume uniform human preferences, fundamentally overlooking the diversity in user values and needs. This paper introduces a comprehensive framework for scalable personalized alignment of LLMs. We establish a systematic preference space characterizing psychological and behavioral dimensions, alongside diverse persona representations for robust preference inference in real-world scenarios. Building upon this foundation, we introduce \textsc{AlignX}, a large-scale dataset of over 1.3 million personalized preference examples, and develop two complementary alignment approaches: \textit{in-context alignment} directly conditioning on persona representations and \textit{preference-bridged alignment} modeling intermediate preference distributions. Extensive experiments demonstrate substantial improvements over existing methods, with an average 17.06\% accuracy gain across four benchmarks while exhibiting a strong adaptation capability to novel preferences, robustness to limited user data, and precise preference controllability. These results validate our framework's effectiveness, advancing toward truly user-adaptive AI systems.
2D-TPE: Two-Dimensional Positional Encoding Enhances Table Understanding for Large Language Models
Sep 29, 2024Tables are ubiquitous across various domains for concisely representing structured information. Empowering large language models (LLMs) to reason over tabular data represents an actively explored direction. However, since typical LLMs only support one-dimensional~(1D) inputs, existing methods often flatten the two-dimensional~(2D) table structure into a sequence of tokens, which can severely disrupt the spatial relationships and result in an inevitable loss of vital contextual information. In this paper, we first empirically demonstrate the detrimental impact of such flattening operations on the performance of LLMs in capturing the spatial information of tables through two elaborate proxy tasks. Subsequently, we introduce a simple yet effective positional encoding method, termed ``2D-TPE'' (Two-Dimensional Table Positional Encoding), to address this challenge. 2D-TPE enables each attention head to dynamically select a permutation order of tokens within the context for attending to them, where each permutation represents a distinct traversal mode for the table, such as column-wise or row-wise traversal. 2D-TPE effectively mitigates the risk of losing essential spatial information while preserving computational efficiency, thus better preserving the table structure. Extensive experiments across five benchmarks demonstrate that 2D-TPE outperforms strong baselines, underscoring the importance of preserving the table structure for accurate table comprehension. Comprehensive analysis further reveals the substantially better scalability of 2D-TPE to large tables than baselines.
Semi-supervised Symmetric Matrix Factorization with Low-Rank Tensor Representation
May 04, 2024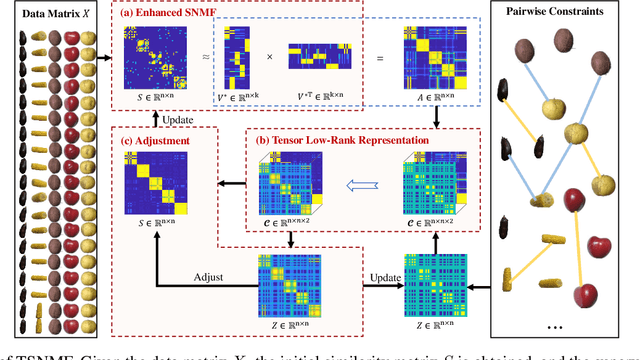
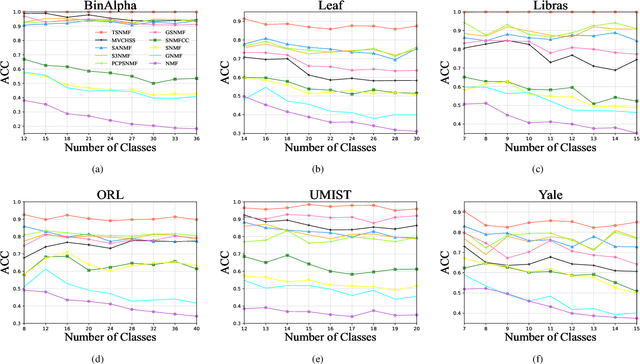
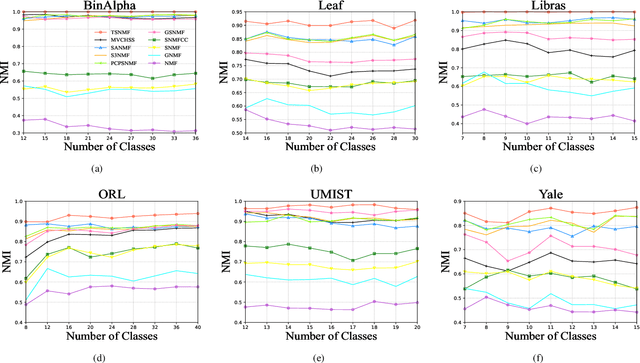

Semi-supervised symmetric non-negative matrix factorization (SNMF) utilizes the available supervisory information (usually in the form of pairwise constraints) to improve the clustering ability of SNMF. The previous methods introduce the pairwise constraints from the local perspective, i.e., they either directly refine the similarity matrix element-wisely or restrain the distance of the decomposed vectors in pairs according to the pairwise constraints, which overlook the global perspective, i.e., in the ideal case, the pairwise constraint matrix and the ideal similarity matrix possess the same low-rank structure. To this end, we first propose a novel semi-supervised SNMF model by seeking low-rank representation for the tensor synthesized by the pairwise constraint matrix and a similarity matrix obtained by the product of the embedding matrix and its transpose, which could strengthen those two matrices simultaneously from a global perspective. We then propose an enhanced SNMF model, making the embedding matrix tailored to the above tensor low-rank representation. We finally refine the similarity matrix by the strengthened pairwise constraints. We repeat the above steps to continuously boost the similarity matrix and pairwise constraint matrix, leading to a high-quality embedding matrix. Extensive experiments substantiate the superiority of our method. The code is available at https://github.com/JinaLeejnl/TSNMF.
StreamingDialogue: Prolonged Dialogue Learning via Long Context Compression with Minimal Losses
Mar 13, 2024Standard Large Language Models (LLMs) struggle with handling dialogues with long contexts due to efficiency and consistency issues. According to our observation, dialogue contexts are highly structured, and the special token of \textit{End-of-Utterance} (EoU) in dialogues has the potential to aggregate information. We refer to the EoU tokens as ``conversational attention sinks'' (conv-attn sinks). Accordingly, we introduce StreamingDialogue, which compresses long dialogue history into conv-attn sinks with minimal losses, and thus reduces computational complexity quadratically with the number of sinks (i.e., the number of utterances). Current LLMs already demonstrate the ability to handle long context window, e.g., a window size of 200k or more. To this end, by compressing utterances into EoUs, our method has the potential to handle more than 200k of utterances, resulting in a prolonged dialogue learning. In order to minimize information losses from reconstruction after compression, we design two learning strategies of short-memory reconstruction (SMR) and long-memory reactivation (LMR). Our method outperforms strong baselines in dialogue tasks and achieves a 4 $\times$ speedup while reducing memory usage by 18 $\times$ compared to dense attention recomputation.