 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWaterFlow: Explicit Physics-Prior Rectified Flow for Underwater Saliency Mask Generation
Oct 14, 2025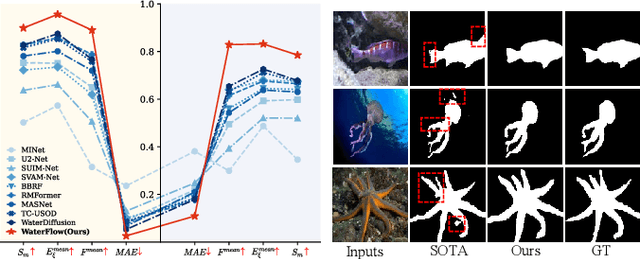
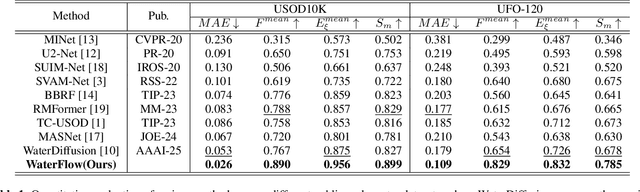
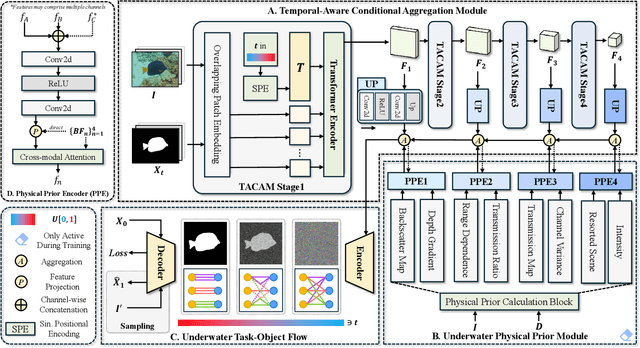

Underwater Salient Object Detection (USOD) faces significant challenges, including underwater image quality degradation and domain gaps. Existing methods tend to ignore the physical principles of underwater imaging or simply treat degradation phenomena in underwater images as interference factors that must be eliminated, failing to fully exploit the valuable information they contain. We propose WaterFlow, a rectified flow-based framework for underwater salient object detection that innovatively incorporates underwater physical imaging information as explicit priors directly into the network training process and introduces temporal dimension modeling, significantly enhancing the model's capability for salient object identification. On the USOD10K dataset, WaterFlow achieves a 0.072 gain in S_m, demonstrating the effectiveness and superiority of our method. The code will be published after the acceptance.
Feature Statistics with Uncertainty Help Adversarial Robustness
Mar 26, 2025Despite the remarkable success of deep neural networks (DNNs), the security threat of adversarial attacks poses a significant challenge to the reliability of DNNs. By introducing randomness into different parts of DNNs, stochastic methods can enable the model to learn some uncertainty, thereby improving model robustness efficiently. In this paper, we theoretically discover a universal phenomenon that adversarial attacks will shift the distributions of feature statistics. Motivated by this theoretical finding, we propose a robustness enhancement module called Feature Statistics with Uncertainty (FSU). It resamples channel-wise feature means and standard deviations of examples from multivariate Gaussian distributions, which helps to reconstruct the attacked examples and calibrate the shifted distributions. The calibration recovers some domain characteristics of the data for classification, thereby mitigating the influence of perturbations and weakening the ability of attacks to deceive models. The proposed FSU module has universal applicability in training, attacking, predicting and fine-tuning, demonstrating impressive robustness enhancement ability at trivial additional time cost. For example, against powerful optimization-based CW attacks, by incorporating FSU into attacking and predicting phases, it endows many collapsed state-of-the-art models with 50%-80% robust accuracy on CIFAR10, CIFAR100 and SVHN.
Semi-supervised Symmetric Matrix Factorization with Low-Rank Tensor Representation
May 04, 2024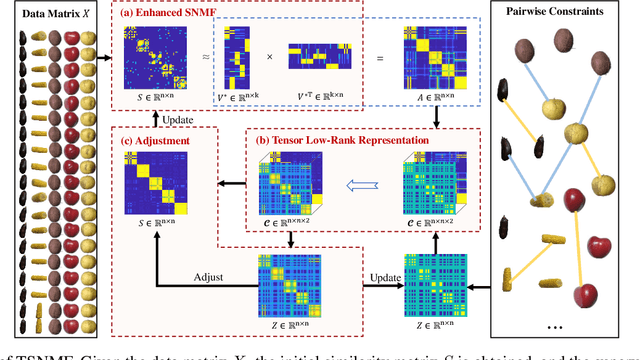
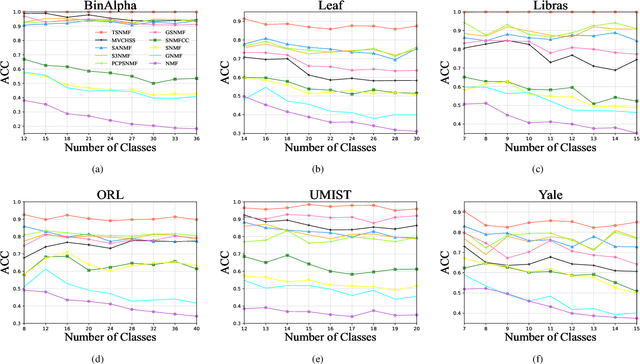
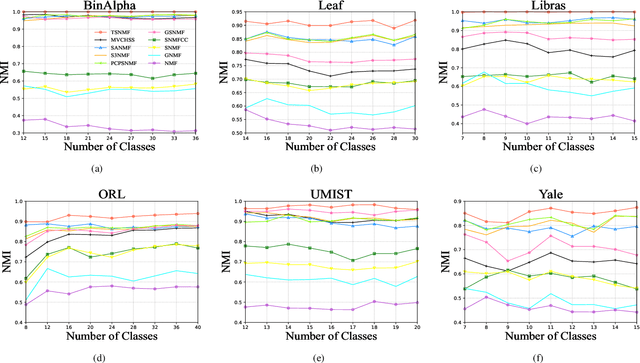

Semi-supervised symmetric non-negative matrix factorization (SNMF) utilizes the available supervisory information (usually in the form of pairwise constraints) to improve the clustering ability of SNMF. The previous methods introduce the pairwise constraints from the local perspective, i.e., they either directly refine the similarity matrix element-wisely or restrain the distance of the decomposed vectors in pairs according to the pairwise constraints, which overlook the global perspective, i.e., in the ideal case, the pairwise constraint matrix and the ideal similarity matrix possess the same low-rank structure. To this end, we first propose a novel semi-supervised SNMF model by seeking low-rank representation for the tensor synthesized by the pairwise constraint matrix and a similarity matrix obtained by the product of the embedding matrix and its transpose, which could strengthen those two matrices simultaneously from a global perspective. We then propose an enhanced SNMF model, making the embedding matrix tailored to the above tensor low-rank representation. We finally refine the similarity matrix by the strengthened pairwise constraints. We repeat the above steps to continuously boost the similarity matrix and pairwise constraint matrix, leading to a high-quality embedding matrix. Extensive experiments substantiate the superiority of our method. The code is available at https://github.com/JinaLeejnl/TSNMF.
Weakly-Supervised 3D Scene Graph Generation via Visual-Linguistic Assisted Pseudo-labeling
Apr 03, 2024



Learning to build 3D scene graphs is essential for real-world perception in a structured and rich fashion. However, previous 3D scene graph generation methods utilize a fully supervised learning manner and require a large amount of entity-level annotation data of objects and relations, which is extremely resource-consuming and tedious to obtain. To tackle this problem, we propose 3D-VLAP, a weakly-supervised 3D scene graph generation method via Visual-Linguistic Assisted Pseudo-labeling. Specifically, our 3D-VLAP exploits the superior ability of current large-scale visual-linguistic models to align the semantics between texts and 2D images, as well as the naturally existing correspondences between 2D images and 3D point clouds, and thus implicitly constructs correspondences between texts and 3D point clouds. First, we establish the positional correspondence from 3D point clouds to 2D images via camera intrinsic and extrinsic parameters, thereby achieving alignment of 3D point clouds and 2D images. Subsequently, a large-scale cross-modal visual-linguistic model is employed to indirectly align 3D instances with the textual category labels of objects by matching 2D images with object category labels. The pseudo labels for objects and relations are then produced for 3D-VLAP model training by calculating the similarity between visual embeddings and textual category embeddings of objects and relations encoded by the visual-linguistic model, respectively. Ultimately, we design an edge self-attention based graph neural network to generate scene graphs of 3D point cloud scenes. Extensive experiments demonstrate that our 3D-VLAP achieves comparable results with current advanced fully supervised methods, meanwhile significantly alleviating the pressure of data annotation.
Compositional Oil Spill Detection Based on Object Detector and Adapted Segment Anything Model from SAR Images
Jan 15, 2024



Semantic segmentation-based methods have attracted extensive attention in oil spill detection from SAR images. However, the existing approaches require a large number of finely annotated segmentation samples in the training stage. To alleviate this issue, we propose a composite oil spill detection framework, SAM-OIL, comprising an object detector (e.g., YOLOv8), an adapted Segment Anything Model (SAM), and an Ordered Mask Fusion (OMF) module. SAM-OIL is the first application of the powerful SAM in oil spill detection. Specifically, the SAM-OIL strategy uses YOLOv8 to obtain the categories and bounding boxes of oil spill-related objects, then inputs bounding boxes into the adapted SAM to retrieve category-agnostic masks, and finally adopts the Ordered Mask Fusion (OMF) module to fuse the masks and categories. The adapted SAM, combining a frozen SAM with a learnable Adapter module, can enhance SAM's ability to segment ambiguous objects. The OMF module, a parameter-free method, can effectively resolve pixel category conflicts within SAM. Experimental results demonstrate that SAM-OIL surpasses existing semantic segmentation-based oil spill detection methods, achieving mIoU of 69.52%. The results also indicated that both OMF and Adapter modules can effectively improve the accuracy in SAM-OIL.
Weakly-Supervised 3D Visual Grounding based on Visual Linguistic Alignment
Dec 15, 2023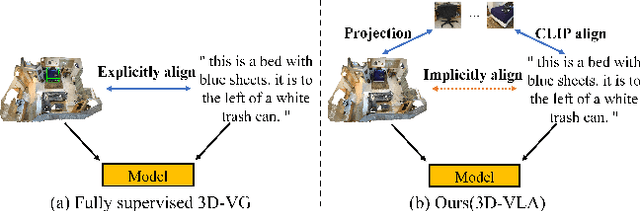
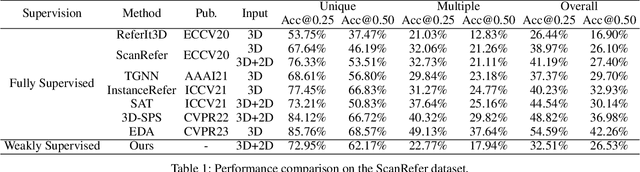
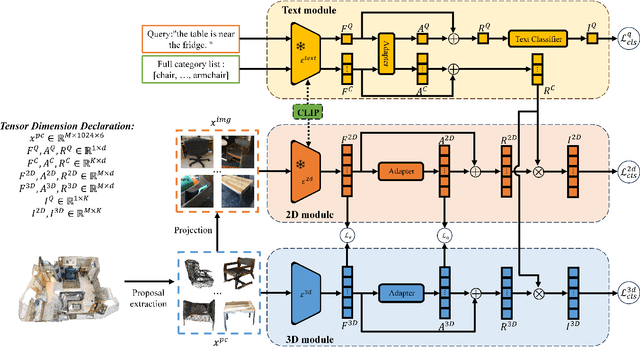
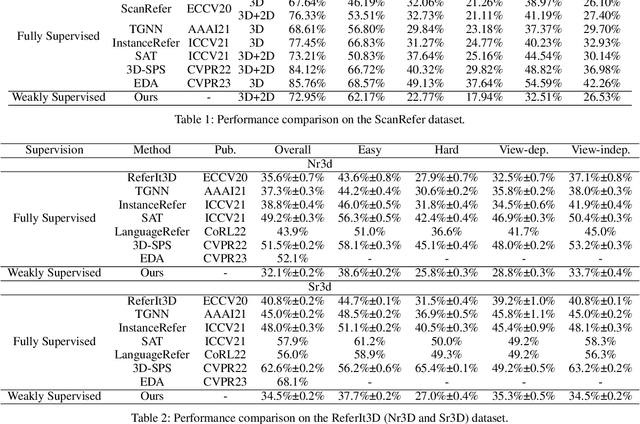
Learning to ground natural language queries to target objects or regions in 3D point clouds is quite essential for 3D scene understanding. Nevertheless, existing 3D visual grounding approaches require a substantial number of bounding box annotations for text queries, which is time-consuming and labor-intensive to obtain. In this paper, we propose \textbf{3D-VLA}, a weakly supervised approach for \textbf{3D} visual grounding based on \textbf{V}isual \textbf{L}inguistic \textbf{A}lignment. Our 3D-VLA exploits the superior ability of current large-scale vision-language models (VLMs) on aligning the semantics between texts and 2D images, as well as the naturally existing correspondences between 2D images and 3D point clouds, and thus implicitly constructs correspondences between texts and 3D point clouds with no need for fine-grained box annotations in the training procedure. During the inference stage, the learned text-3D correspondence will help us ground the text queries to the 3D target objects even without 2D images. To the best of our knowledge, this is the first work to investigate 3D visual grounding in a weakly supervised manner by involving large scale vision-language models, and extensive experiments on ReferIt3D and ScanRefer datasets demonstrate that our 3D-VLA achieves comparable and even superior results over the fully supervised methods.
Superpixel Segmentation Based on Spatially Constrained Subspace Clustering
Dec 11, 2020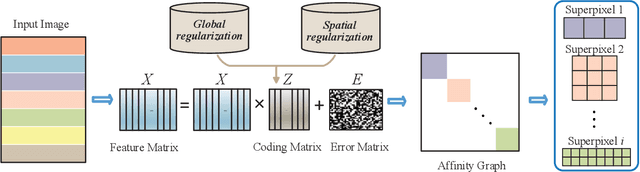
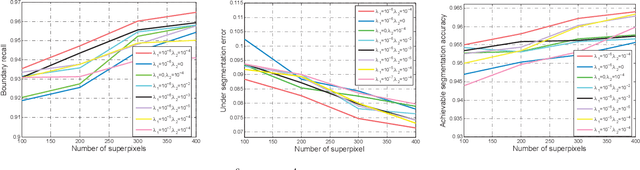

Superpixel segmentation aims at dividing the input image into some representative regions containing pixels with similar and consistent intrinsic properties, without any prior knowledge about the shape and size of each superpixel. In this paper, to alleviate the limitation of superpixel segmentation applied in practical industrial tasks that detailed boundaries are difficult to be kept, we regard each representative region with independent semantic information as a subspace, and correspondingly formulate superpixel segmentation as a subspace clustering problem to preserve more detailed content boundaries. We show that a simple integration of superpixel segmentation with the conventional subspace clustering does not effectively work due to the spatial correlation of the pixels within a superpixel, which may lead to boundary confusion and segmentation error when the correlation is ignored. Consequently, we devise a spatial regularization and propose a novel convex locality-constrained subspace clustering model that is able to constrain the spatial adjacent pixels with similar attributes to be clustered into a superpixel and generate the content-aware superpixels with more detailed boundaries. Finally, the proposed model is solved by an efficient alternating direction method of multipliers (ADMM) solver. Experiments on different standard datasets demonstrate that the proposed method achieves superior performance both quantitatively and qualitatively compared with some state-of-the-art methods.