 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInstructionBench: An Instructional Video Understanding Benchmark
Apr 07, 2025



Despite progress in video large language models (Video-LLMs), research on instructional video understanding, crucial for enhancing access to instructional content, remains insufficient. To address this, we introduce InstructionBench, an Instructional video understanding Benchmark, which challenges models' advanced temporal reasoning within instructional videos characterized by their strict step-by-step flow. Employing GPT-4, we formulate Q\&A pairs in open-ended and multiple-choice formats to assess both Coarse-Grained event-level and Fine-Grained object-level reasoning. Our filtering strategies exclude questions answerable purely by common-sense knowledge, focusing on visual perception and analysis when evaluating Video-LLM models. The benchmark finally contains 5k questions across over 700 videos. We evaluate the latest Video-LLMs on our InstructionBench, finding that closed-source models outperform open-source ones. However, even the best model, GPT-4o, achieves only 53.42\% accuracy, indicating significant gaps in temporal reasoning. To advance the field, we also develop a comprehensive instructional video dataset with over 19k Q\&A pairs from nearly 2.5k videos, using an automated data generation framework, thereby enriching the community's research resources.
Deep Learning-Based Diffusion MRI Tractography: Integrating Spatial and Anatomical Information
Mar 05, 2025Diffusion MRI tractography technique enables non-invasive visualization of the white matter pathways in the brain. It plays a crucial role in neuroscience and clinical fields by facilitating the study of brain connectivity and neurological disorders. However, the accuracy of reconstructed tractograms has been a longstanding challenge. Recently, deep learning methods have been applied to improve tractograms for better white matter coverage, but often comes at the expense of generating excessive false-positive connections. This is largely due to their reliance on local information to predict long range streamlines. To improve the accuracy of streamline propagation predictions, we introduce a novel deep learning framework that integrates image-domain spatial information and anatomical information along tracts, with the former extracted through convolutional layers and the later modeled via a Transformer-decoder. Additionally, we employ a weighted loss function to address fiber class imbalance encountered during training. We evaluate the proposed method on the simulated ISMRM 2015 Tractography Challenge dataset, achieving a valid streamline rate of 66.2%, white matter coverage of 63.8%, and successfully reconstructing 24 out of 25 bundles. Furthermore, on the multi-site Tractoinferno dataset, the proposed method demonstrates its ability to handle various diffusion MRI acquisition schemes, achieving a 5.7% increase in white matter coverage and a 4.1% decrease in overreach compared to RNN-based methods.
TimeMarker: A Versatile Video-LLM for Long and Short Video Understanding with Superior Temporal Localization Ability
Nov 27, 2024



Rapid development of large language models (LLMs) has significantly advanced multimodal large language models (LMMs), particularly in vision-language tasks. However, existing video-language models often overlook precise temporal localization and struggle with videos of varying lengths. We introduce TimeMarker, a versatile Video-LLM designed for high-quality dialogue based on video content, emphasizing temporal localization. TimeMarker integrates Temporal Separator Tokens to enhance temporal awareness, accurately marking specific moments within videos. It employs the AnyLength mechanism for dynamic frame sampling and adaptive token merging, enabling effective handling of both short and long videos. Additionally, TimeMarker utilizes diverse datasets, including further transformed temporal-related video QA datasets, to bolster its temporal understanding capabilities. Image and interleaved data are also employed to further enhance the model's semantic perception ability. Evaluations demonstrate that TimeMarker achieves state-of-the-art performance across multiple benchmarks, excelling in both short and long video categories. Our project page is at \url{https://github.com/TimeMarker-LLM/TimeMarker/}.
VidCompress: Memory-Enhanced Temporal Compression for Video Understanding in Large Language Models
Oct 15, 2024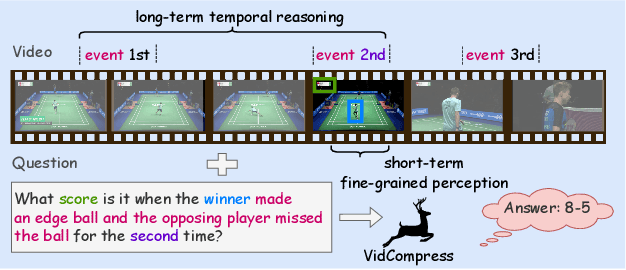
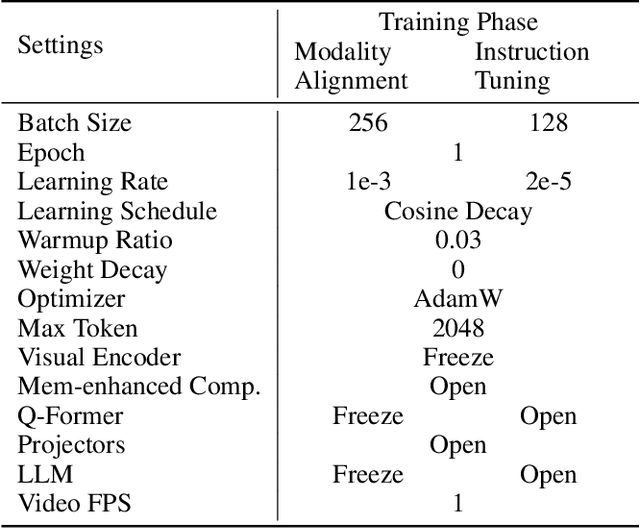
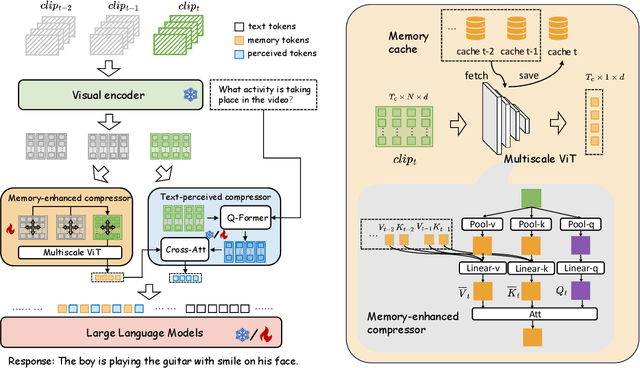
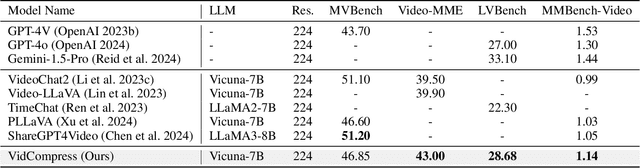
Video-based multimodal large language models (Video-LLMs) possess significant potential for video understanding tasks. However, most Video-LLMs treat videos as a sequential set of individual frames, which results in insufficient temporal-spatial interaction that hinders fine-grained comprehension and difficulty in processing longer videos due to limited visual token capacity. To address these challenges, we propose VidCompress, a novel Video-LLM featuring memory-enhanced temporal compression. VidCompress employs a dual-compressor approach: a memory-enhanced compressor captures both short-term and long-term temporal relationships in videos and compresses the visual tokens using a multiscale transformer with a memory-cache mechanism, while a text-perceived compressor generates condensed visual tokens by utilizing Q-Former and integrating temporal contexts into query embeddings with cross attention. Experiments on several VideoQA datasets and comprehensive benchmarks demonstrate that VidCompress efficiently models complex temporal-spatial relations and significantly outperforms existing Video-LLMs.
3D Weakly Supervised Semantic Segmentation with 2D Vision-Language Guidance
Jul 13, 2024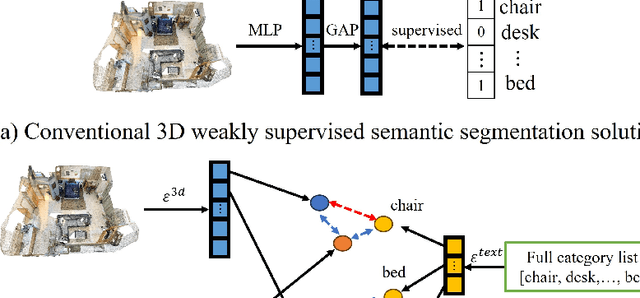
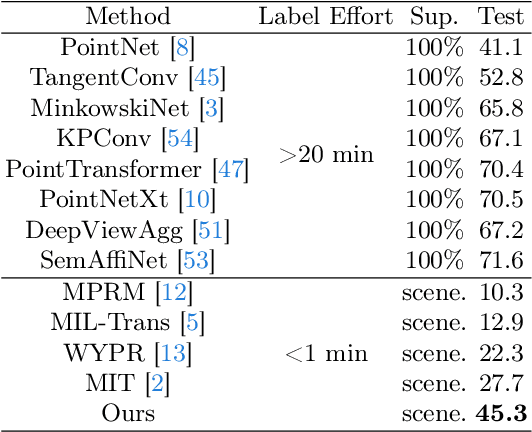
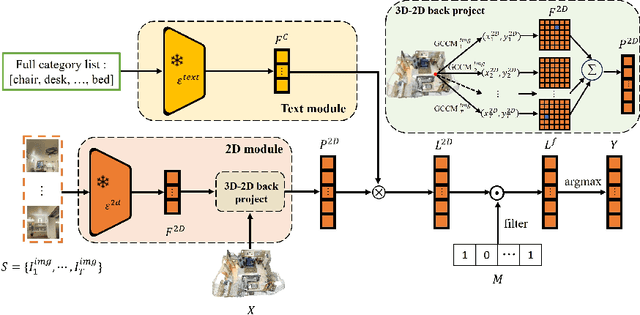
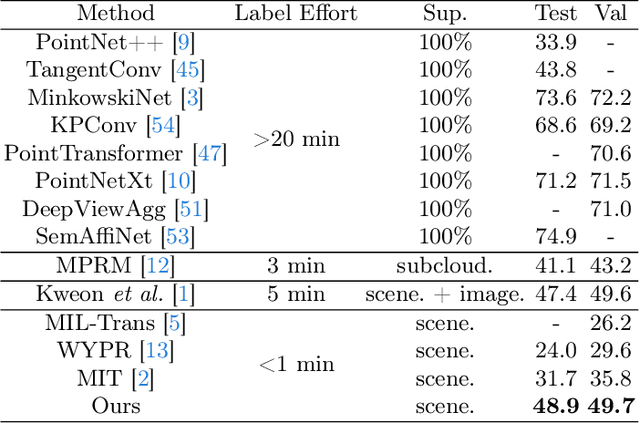
In this paper, we propose 3DSS-VLG, a weakly supervised approach for 3D Semantic Segmentation with 2D Vision-Language Guidance, an alternative approach that a 3D model predicts dense-embedding for each point which is co-embedded with both the aligned image and text spaces from the 2D vision-language model. Specifically, our method exploits the superior generalization ability of the 2D vision-language models and proposes the Embeddings Soft-Guidance Stage to utilize it to implicitly align 3D embeddings and text embeddings. Moreover, we introduce the Embeddings Specialization Stage to purify the feature representation with the help of a given scene-level label, specifying a better feature supervised by the corresponding text embedding. Thus, the 3D model is able to gain informative supervisions both from the image embedding and text embedding, leading to competitive segmentation performances. To the best of our knowledge, this is the first work to investigate 3D weakly supervised semantic segmentation by using the textual semantic information of text category labels. Moreover, with extensive quantitative and qualitative experiments, we present that our 3DSS-VLG is able not only to achieve the state-of-the-art performance on both S3DIS and ScanNet datasets, but also to maintain strong generalization capability.
Fewer Tokens and Fewer Videos: Extending Video Understanding Abilities in Large Vision-Language Models
Jun 12, 2024



Amidst the advancements in image-based Large Vision-Language Models (image-LVLM), the transition to video-based models (video-LVLM) is hindered by the limited availability of quality video data. This paper addresses the challenge by leveraging the visual commonalities between images and videos to efficiently evolve image-LVLMs into video-LVLMs. We present a cost-effective video-LVLM that enhances model architecture, introduces innovative training strategies, and identifies the most effective types of video instruction data. Our innovative weighted token sampler significantly compresses the visual token numbers of each video frame, effectively cutting computational expenses. We also find that judiciously using just 10% of the video data, compared to prior video-LVLMs, yields impressive results during various training phases. Moreover, we delve into the influence of video instruction data in limited-resource settings, highlighting the significance of incorporating video training data that emphasizes temporal understanding to enhance model performance. The resulting Fewer Tokens and Fewer Videos LVLM (FTFV-LVLM) exhibits exceptional performance across video and image benchmarks, validating our model's design and training approaches.
Weakly-Supervised 3D Visual Grounding based on Visual Linguistic Alignment
Dec 15, 2023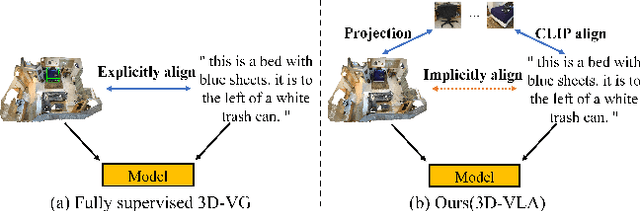
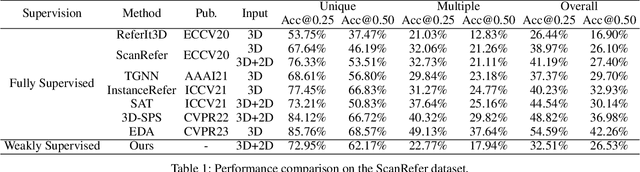
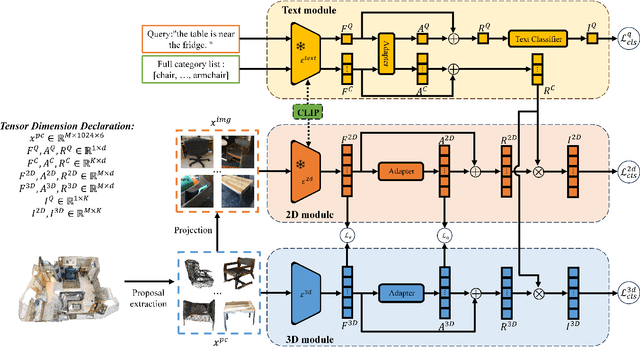
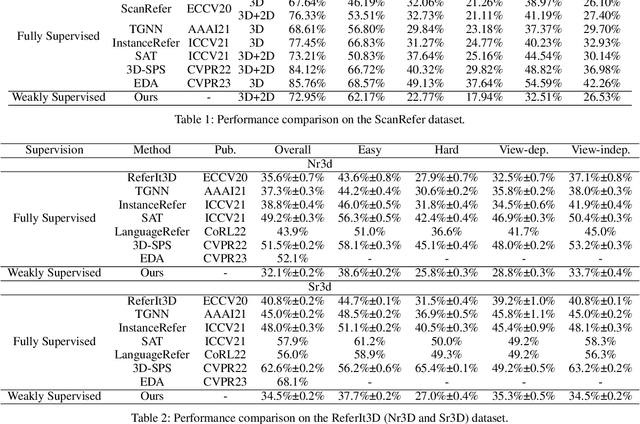
Learning to ground natural language queries to target objects or regions in 3D point clouds is quite essential for 3D scene understanding. Nevertheless, existing 3D visual grounding approaches require a substantial number of bounding box annotations for text queries, which is time-consuming and labor-intensive to obtain. In this paper, we propose \textbf{3D-VLA}, a weakly supervised approach for \textbf{3D} visual grounding based on \textbf{V}isual \textbf{L}inguistic \textbf{A}lignment. Our 3D-VLA exploits the superior ability of current large-scale vision-language models (VLMs) on aligning the semantics between texts and 2D images, as well as the naturally existing correspondences between 2D images and 3D point clouds, and thus implicitly constructs correspondences between texts and 3D point clouds with no need for fine-grained box annotations in the training procedure. During the inference stage, the learned text-3D correspondence will help us ground the text queries to the 3D target objects even without 2D images. To the best of our knowledge, this is the first work to investigate 3D visual grounding in a weakly supervised manner by involving large scale vision-language models, and extensive experiments on ReferIt3D and ScanRefer datasets demonstrate that our 3D-VLA achieves comparable and even superior results over the fully supervised methods.
A Closer Look at Debiased Temporal Sentence Grounding in Videos: Dataset, Metric, and Approach
Mar 10, 2022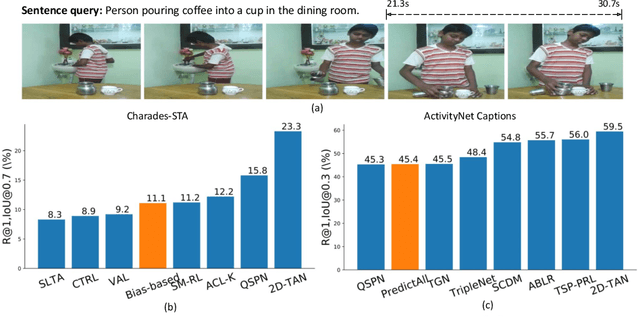
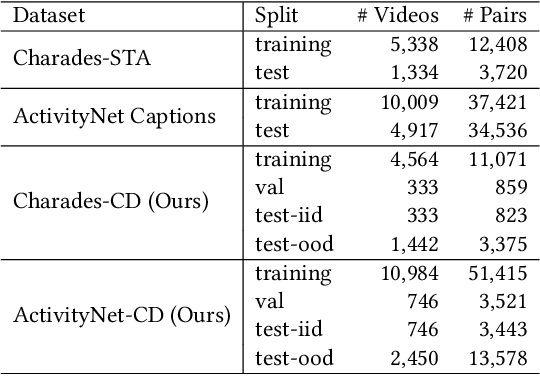
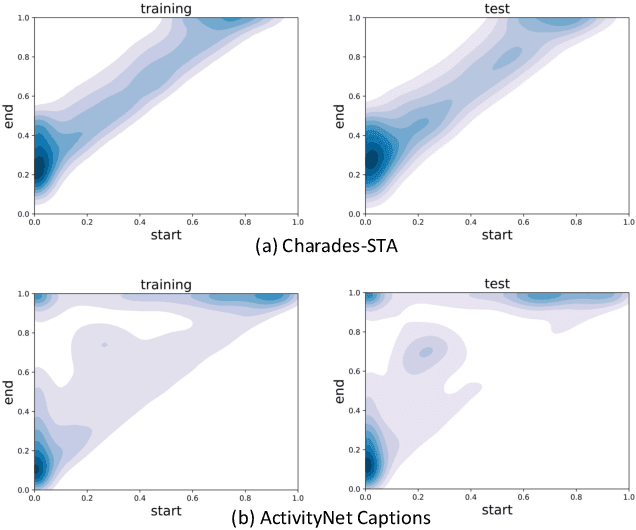
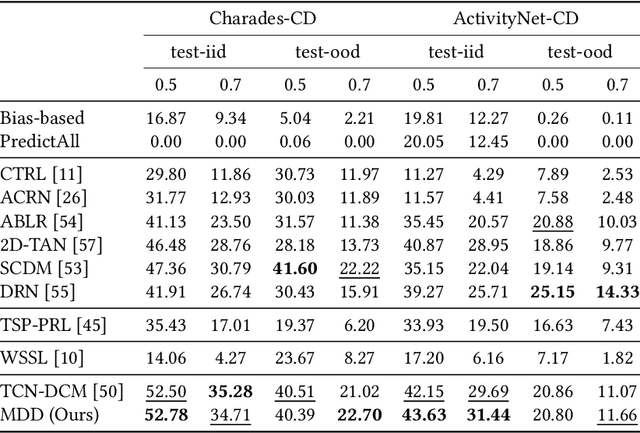
Temporal Sentence Grounding in Videos (TSGV), which aims to ground a natural language sentence in an untrimmed video, has drawn widespread attention over the past few years. However, recent studies have found that current benchmark datasets may have obvious moment annotation biases, enabling several simple baselines even without training to achieve SOTA performance. In this paper, we take a closer look at existing evaluation protocols, and find both the prevailing dataset and evaluation metrics are the devils that lead to untrustworthy benchmarking. Therefore, we propose to re-organize the two widely-used datasets, making the ground-truth moment distributions different in the training and test splits, i.e., out-of-distribution (OOD) test. Meanwhile, we introduce a new evaluation metric "dR@n,IoU@m" that discounts the basic recall scores to alleviate the inflating evaluation caused by biased datasets. New benchmarking results indicate that our proposed evaluation protocols can better monitor the research progress. Furthermore, we propose a novel causality-based Multi-branch Deconfounding Debiasing (MDD) framework for unbiased moment prediction. Specifically, we design a multi-branch deconfounder to eliminate the effects caused by multiple confounders with causal intervention. In order to help the model better align the semantics between sentence queries and video moments, we enhance the representations during feature encoding. Specifically, for textual information, the query is parsed into several verb-centered phrases to obtain a more fine-grained textual feature. For visual information, the positional information has been decomposed from moment features to enhance representations of moments with diverse locations. Extensive experiments demonstrate that our proposed approach can achieve competitive results among existing SOTA approaches and outperform the base model with great gains.
Controllable Video Captioning with an Exemplar Sentence
Dec 02, 2021


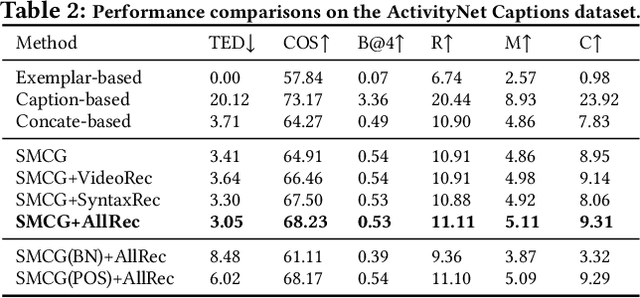
In this paper, we investigate a novel and challenging task, namely controllable video captioning with an exemplar sentence. Formally, given a video and a syntactically valid exemplar sentence, the task aims to generate one caption which not only describes the semantic contents of the video, but also follows the syntactic form of the given exemplar sentence. In order to tackle such an exemplar-based video captioning task, we propose a novel Syntax Modulated Caption Generator (SMCG) incorporated in an encoder-decoder-reconstructor architecture. The proposed SMCG takes video semantic representation as an input, and conditionally modulates the gates and cells of long short-term memory network with respect to the encoded syntactic information of the given exemplar sentence. Therefore, SMCG is able to control the states for word prediction and achieve the syntax customized caption generation. We conduct experiments by collecting auxiliary exemplar sentences for two public video captioning datasets. Extensive experimental results demonstrate the effectiveness of our approach on generating syntax controllable and semantic preserved video captions. By providing different exemplar sentences, our approach is capable of producing different captions with various syntactic structures, thus indicating a promising way to strengthen the diversity of video captioning.
Syntax Customized Video Captioning by Imitating Exemplar Sentences
Dec 02, 2021
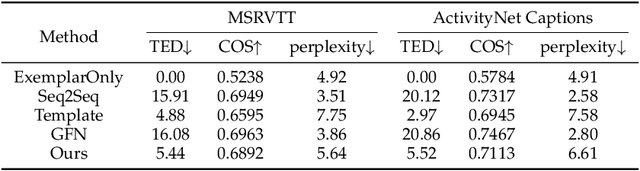
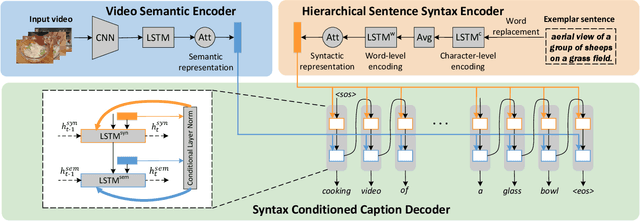
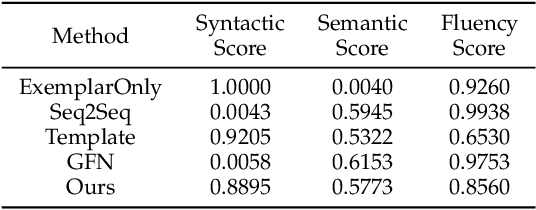
Enhancing the diversity of sentences to describe video contents is an important problem arising in recent video captioning research. In this paper, we explore this problem from a novel perspective of customizing video captions by imitating exemplar sentence syntaxes. Specifically, given a video and any syntax-valid exemplar sentence, we introduce a new task of Syntax Customized Video Captioning (SCVC) aiming to generate one caption which not only semantically describes the video contents but also syntactically imitates the given exemplar sentence. To tackle the SCVC task, we propose a novel video captioning model, where a hierarchical sentence syntax encoder is firstly designed to extract the syntactic structure of the exemplar sentence, then a syntax conditioned caption decoder is devised to generate the syntactically structured caption expressing video semantics. As there is no available syntax customized groundtruth video captions, we tackle such a challenge by proposing a new training strategy, which leverages the traditional pairwise video captioning data and our collected exemplar sentences to accomplish the model learning. Extensive experiments, in terms of semantic, syntactic, fluency, and diversity evaluations, clearly demonstrate our model capability to generate syntax-varied and semantics-coherent video captions that well imitate different exemplar sentences with enriched diversities.