 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeControllable Video Captioning with an Exemplar Sentence
Paper and Code



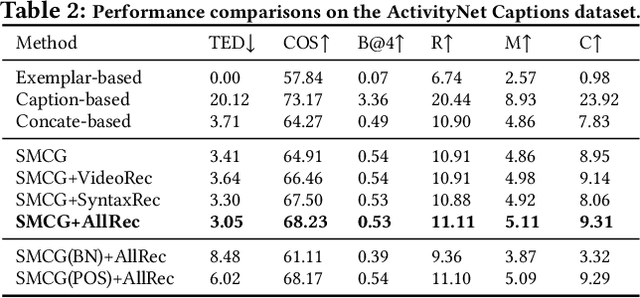
In this paper, we investigate a novel and challenging task, namely controllable video captioning with an exemplar sentence. Formally, given a video and a syntactically valid exemplar sentence, the task aims to generate one caption which not only describes the semantic contents of the video, but also follows the syntactic form of the given exemplar sentence. In order to tackle such an exemplar-based video captioning task, we propose a novel Syntax Modulated Caption Generator (SMCG) incorporated in an encoder-decoder-reconstructor architecture. The proposed SMCG takes video semantic representation as an input, and conditionally modulates the gates and cells of long short-term memory network with respect to the encoded syntactic information of the given exemplar sentence. Therefore, SMCG is able to control the states for word prediction and achieve the syntax customized caption generation. We conduct experiments by collecting auxiliary exemplar sentences for two public video captioning datasets. Extensive experimental results demonstrate the effectiveness of our approach on generating syntax controllable and semantic preserved video captions. By providing different exemplar sentences, our approach is capable of producing different captions with various syntactic structures, thus indicating a promising way to strengthen the diversity of video captioning.