 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOOD-GraphLLM: Graph Large Language Model for Out-of-Distribution Generalized Drug Synergy Prediction
May 28, 2026Drug synergy prediction (DSP) aims to identify efficacious drug combinations under various cellular contexts with different targets. However, the continual emergence of novel compounds results in variations in molecular scaffolds and sizes, causing drug synergy data to exhibit out-of-distribution (O.O.D.) shifts with respect to topological structure. Existing works rely on in-distribution (I.D.) assumption, failing to handle the O.O.D. shifts. To solve this problem, we study out-of-distribution generalized drug synergy prediction through a graph large language model for the first time. Nevertheless, O.O.D. generalized DSP is highly non-trivial, posing several challenges: i) how to discover structurally relevant and irrelevant molecular representations with respect to cell targets; ii) how to find the optimal graph neural architectures that accurately calculate molecular representations; and iii) how to jointly leverage molecular structural and semantic information in LLMs. To address these challenges, we propose OOD-GraphLLM, a novel graphLLM framework which is able to accurately predict drug synergy under O.O.D. settings via jointly optimizing molecular graph representation and biomedical semantic language representations in a unified manner. Furthermore, we finetune DrugSyn-LLM, a biomedical LLM, and employ a retrieval-augmented biomedical instruction tuning strategy to align molecular topological information and molecular semantic information with language-based reasoning for O.O.D. generalized DSP. Both the source code (https://github.com/EkkoXiao/Bio-GraphLLM) and released model (https://mn.cs.tsinghua.edu.cn/bio-graphllm/) are publicly available, where users are allowed to download model resources and interactively use the system through a web interface.
Asymmetric Generative Recommendation via Multi-Expert Projection and Multi-Faceted Hierarchical Quantization
May 14, 2026Generative Recommendation (GenRec) models reformulate recommendation as a sequence generation task, representing items as discrete Semantic IDs used symmetrically as both inputs and prediction targets. We identify a critical dual-stage information bottleneck in this design: (1) the Input Bottleneck, where lossy quantization degrades fine-grained semantics, while popularity bias skews the learned representations toward frequent items, and (2) the Output Bottleneck, where imprecise discrete targets limit supervision quality. To address these issues, we propose AsymRec, an asymmetric continuous-discrete framework that decouples input and output representations. Specifically, Multi-expert Semantic Projection (MSP) maps continuous embeddings into the Transformer's hidden space via expert-specialized projections, preserving semantic richness and improving generalization to infrequent items. Multi-faceted Hierarchical Quantization (MHQ) constructs high-capacity, structured discrete targets through multi-view and multi-level quantization with semantic regularization, preventing dimensional collapse while retaining fine-grained distinctions. Extensive experiments demonstrate that AsymRec consistently outperforms state-of-the-art generative recommenders by an average of 15.8 %. The code will be released.
A Unified Graph Language Model for Multi-Domain Multi-Task Graph Alignment Instruction Tuning
May 12, 2026Leveraging Graph Neural Networks (GNNs) as graph encoders and aligning the resulting representations with Large Language Models (LLMs) through alignment instruction tuning has become a mainstream paradigm for constructing Graph Language Models (GLMs), combining the generalization ability of LLMs with the structural modeling capacity of GNNs. However, existing GLMs that adopt GNNs as graph encoders largely overlook the problem of aligning GNN-encoded representations across domains and tasks with the LLM token space to obtain unified graph tokens, thereby limiting their ability to generalize across diverse graph data. To bridge this gap, we aim to incorporate a multi-domain, multi-task GNN encoder into GLMs and align its representations with LLMs to enable multi-domain, multi-task graph alignment instruction tuning. This alignment problem remains underexplored and poses two key challenges: 1) learning GNN-encoded representations that are simultaneously generalizable across domains and tasks and well aligned with textual semantics is difficult, due to substantial variations in graph structures, feature distributions, and supervision signals, together with the lack of textual-semantic alignment guidance in task-specific GNN training; 2) diverse graph data and task-specific instructions can exhibit different degrees of compatibility with the LLM token space during instruction tuning, leading to varying alignment difficulty and rendering a fixed alignment strategy suboptimal. To tackle these challenges, we propose UniGraphLM, a Unified Graph Language Model that incorporates a multi-domain, multi-task GNN encoder to learn generalizable graph representations aligned with textual semantics, and then adaptively aligns these representations with the LLM.
Agentic AIs Are the Missing Paradigm for Out-of-Distribution Generalization in Foundation Models
May 07, 2026Foundation models (FMs) are increasingly deployed in open-world settings where distribution shift is the rule rather than the exception. The out-of-distribution (OOD) phenomena they face -- knowledge boundaries, capability ceilings, compositional shifts, and open-ended task variation -- differ in kind from the settings that have shaped prior OOD research, and are further complicated because the pretraining and post-training distributions of modern FMs are often only partially observed. Our position is that OOD for foundation models is a structurally distinct problem that cannot be solved within the prevailing model-centric paradigm, and that agentic systems constitute the missing paradigm required to address it. We defend this claim through four steps. First, we give a stage-aware formalization of OOD that accommodates partially observed multi-stage training distributions. Second, we prove a parameter coverage ceiling: there exist practically relevant inputs that no model-centric method (training-time or test-time) can handle within tolerance $\varepsilon$, for reasons intrinsic to parameter-based representation. Third, we characterize agentic OOD systems by four structural properties -- perception, strategy selection, external action, and closed-loop verification -- and show that they strictly extend the reachable set beyond the ceiling. Fourth, we respond to seven counterarguments, conceding two, and outline a research agenda. We do not claim that agentic methods subsume model-centric ones; we argue that the two are complementary, and that progress on FM-OOD requires explicit recognition of the agentic paradigm as a first-class research direction.
WiSparse: Boosting LLM Inference Efficiency with Weight-Aware Mixed Activation Sparsity
Feb 16, 2026Large Language Models (LLMs) offer strong capabilities but incur high inference costs due to dense computation and memory access. Training-free activation sparsity is a promising approach for efficient LLM inference, yet existing methods often rely solely on activation information and uniform sparsity ratios. This overlooks the critical interplay with weights and inter-block sensitivity variation, leading to suboptimal performance. We identify two key phenomena in modern LLMs: 1) less significant activations may align with highly important weights, and 2) sparsity sensitivity varies non-monotonically across model blocks. We propose Weight-aware Mixed-Granularity Training-free Activation Sparsity (WiSparse), which leverages both activation and weight information for adaptive sparsity allocation. Specifically, we introduce a weight-aware mechanism integrating activation magnitudes with precomputed weight norms to accurately identify salient channels. This is combined with a mixed-granularity allocation scheme: a global budget is distributed across blocks via evolutionary search to protect sensitive regions, then refined within blocks to minimize reconstruction error. We improve sparse kernels and demonstrate effectiveness on three representative models. Notably, at 50% sparsity, WiSparse preserves 97% of Llama3.1's dense performance, surpassing the strongest baseline by 2.23 percentage points while achieving a 21.4% acceleration in end-to-end inference speed. Our research advances the limits of training-free approaches for efficient LLM inference, pushing the boundaries of achievable speedup without training.
WorldArena: A Unified Benchmark for Evaluating Perception and Functional Utility of Embodied World Models
Feb 09, 2026While world models have emerged as a cornerstone of embodied intelligence by enabling agents to reason about environmental dynamics through action-conditioned prediction, their evaluation remains fragmented. Current evaluation of embodied world models has largely focused on perceptual fidelity (e.g., video generation quality), overlooking the functional utility of these models in downstream decision-making tasks. In this work, we introduce WorldArena, a unified benchmark designed to systematically evaluate embodied world models across both perceptual and functional dimensions. WorldArena assesses models through three dimensions: video perception quality, measured with 16 metrics across six sub-dimensions; embodied task functionality, which evaluates world models as data engines, policy evaluators, and action planners integrating with subjective human evaluation. Furthermore, we propose EWMScore, a holistic metric integrating multi-dimensional performance into a single interpretable index. Through extensive experiments on 14 representative models, we reveal a significant perception-functionality gap, showing that high visual quality does not necessarily translate into strong embodied task capability. WorldArena benchmark with the public leaderboard is released at https://worldarena.ai, providing a framework for tracking progress toward truly functional world models in embodied AI.
Self-evolving Embodied AI
Feb 04, 2026Embodied Artificial Intelligence (AI) is an intelligent system formed by agents and their environment through active perception, embodied cognition, and action interaction. Existing embodied AI remains confined to human-crafted setting, in which agents are trained on given memory and construct models for given tasks, enabling fixed embodiments to interact with relatively static environments. Such methods fail in in-the-wild setting characterized by variable embodiments and dynamic open environments. This paper introduces self-evolving embodied AI, a new paradigm in which agents operate based on their changing state and environment with memory self-updating, task self-switching, environment self-prediction, embodiment self-adaptation, and model self-evolution, aiming to achieve continually adaptive intelligence with autonomous evolution. Specifically, we present the definition, framework, components, and mechanisms of self-evolving embodied AI, systematically review state-of-the-art works for realized components, discuss practical applications, and point out future research directions. We believe that self-evolving embodied AI enables agents to autonomously learn and interact with environments in a human-like manner and provide a new perspective toward general artificial intelligence.
Out-of-Distribution Generalization in Graph Foundation Models
Jan 28, 2026Graphs are a fundamental data structure for representing relational information in domains such as social networks, molecular systems, and knowledge graphs. However, graph learning models often suffer from limited generalization when applied beyond their training distributions. In practice, distribution shifts may arise from changes in graph structure, domain semantics, available modalities, or task formulations. To address these challenges, graph foundation models (GFMs) have recently emerged, aiming to learn general-purpose representations through large-scale pretraining across diverse graphs and tasks. In this survey, we review recent progress on GFMs from the perspective of out-of-distribution (OOD) generalization. We first discuss the main challenges posed by distribution shifts in graph learning and outline a unified problem setting. We then organize existing approaches based on whether they are designed to operate under a fixed task specification or to support generalization across heterogeneous task formulations, and summarize the corresponding OOD handling strategies and pretraining objectives. Finally, we review common evaluation protocols and discuss open directions for future research. To the best of our knowledge, this paper is the first survey for OOD generalization in GFMs.
Aerial World Model for Long-horizon Visual Generation and Navigation in 3D Space
Dec 26, 2025Unmanned aerial vehicles (UAVs) have emerged as powerful embodied agents. One of the core abilities is autonomous navigation in large-scale three-dimensional environments. Existing navigation policies, however, are typically optimized for low-level objectives such as obstacle avoidance and trajectory smoothness, lacking the ability to incorporate high-level semantics into planning. To bridge this gap, we propose ANWM, an aerial navigation world model that predicts future visual observations conditioned on past frames and actions, thereby enabling agents to rank candidate trajectories by their semantic plausibility and navigational utility. ANWM is trained on 4-DoF UAV trajectories and introduces a physics-inspired module: Future Frame Projection (FFP), which projects past frames into future viewpoints to provide coarse geometric priors. This module mitigates representational uncertainty in long-distance visual generation and captures the mapping between 3D trajectories and egocentric observations. Empirical results demonstrate that ANWM significantly outperforms existing world models in long-distance visual forecasting and improves UAV navigation success rates in large-scale environments.
TS-DP: Reinforcement Speculative Decoding For Temporal Adaptive Diffusion Policy Acceleration
Dec 13, 2025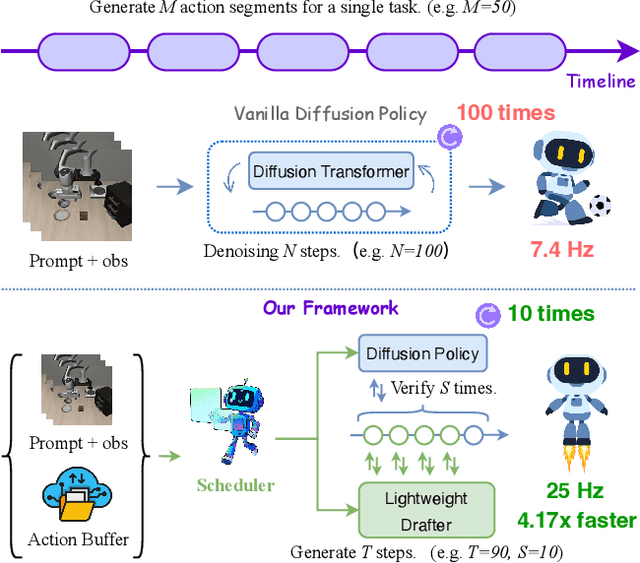
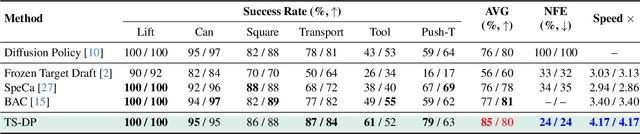

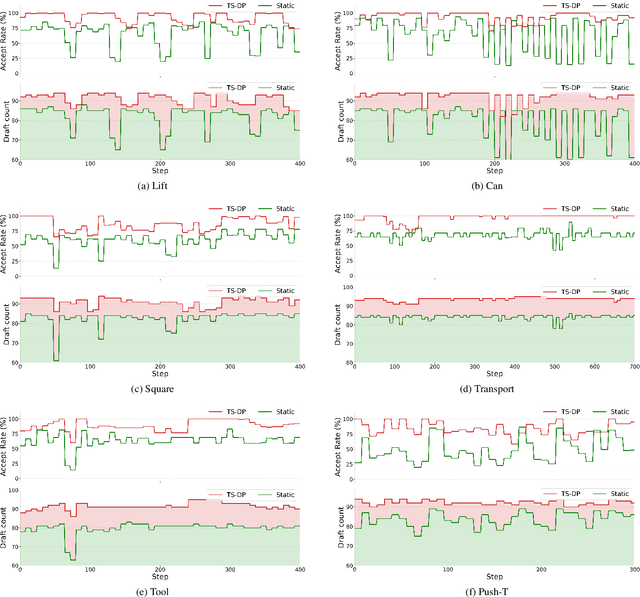
Diffusion Policy (DP) excels in embodied control but suffers from high inference latency and computational cost due to multiple iterative denoising steps. The temporal complexity of embodied tasks demands a dynamic and adaptable computation mode. Static and lossy acceleration methods, such as quantization, fail to handle such dynamic embodied tasks, while speculative decoding offers a lossless and adaptive yet underexplored alternative for DP. However, it is non-trivial to address the following challenges: how to match the base model's denoising quality at lower cost under time-varying task difficulty in embodied settings, and how to dynamically and interactively adjust computation based on task difficulty in such environments. In this paper, we propose Temporal-aware Reinforcement-based Speculative Diffusion Policy (TS-DP), the first framework that enables speculative decoding for DP with temporal adaptivity. First, to handle dynamic environments where task difficulty varies over time, we distill a Transformer-based drafter to imitate the base model and replace its costly denoising calls. Second, an RL-based scheduler further adapts to time-varying task difficulty by adjusting speculative parameters to maintain accuracy while improving efficiency. Extensive experiments across diverse embodied environments demonstrate that TS-DP achieves up to 4.17 times faster inference with over 94% accepted drafts, reaching an inference frequency of 25 Hz and enabling real-time diffusion-based control without performance degradation.