 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMimicLM: Zero-Shot Voice Imitation through Autoregressive Modeling of Pseudo-Parallel Speech Corpora
Apr 13, 2026Voice imitation aims to transform source speech to match a reference speaker's timbre and speaking style while preserving linguistic content. A straightforward approach is to train on triplets of (source, reference, target), where source and target share the same content but target matches the reference's voice characteristics, yet such data is extremely scarce. Existing approaches either employ carefully designed disentanglement architectures to bypass this data scarcity or leverage external systems to synthesize pseudo-parallel training data. However, the former requires intricate model design, and the latter faces a quality ceiling when synthetic speech is used as training targets. To address these limitations, we propose MimicLM, which takes a novel approach by using synthetic speech as training sources while retaining real recordings as targets. This design enables the model to learn directly from real speech distributions, breaking the synthetic quality ceiling. Building on this data construction approach, we incorporate interleaved text-audio modeling to guide the generation of content-accurate speech and apply post-training with preference alignment to mitigate the inherent distributional mismatch when training on synthetic data. Experiments demonstrate that MimicLM achieves superior voice imitation quality with a simple yet effective architecture, significantly outperforming existing methods in naturalness while maintaining competitive similarity scores across speaker identity, accent, and emotion dimensions.
UniSync: A Unified Framework for Audio-Visual Synchronization
Mar 20, 2025Precise audio-visual synchronization in speech videos is crucial for content quality and viewer comprehension. Existing methods have made significant strides in addressing this challenge through rule-based approaches and end-to-end learning techniques. However, these methods often rely on limited audio-visual representations and suboptimal learning strategies, potentially constraining their effectiveness in more complex scenarios. To address these limitations, we present UniSync, a novel approach for evaluating audio-visual synchronization using embedding similarities. UniSync offers broad compatibility with various audio representations (e.g., Mel spectrograms, HuBERT) and visual representations (e.g., RGB images, face parsing maps, facial landmarks, 3DMM), effectively handling their significant dimensional differences. We enhance the contrastive learning framework with a margin-based loss component and cross-speaker unsynchronized pairs, improving discriminative capabilities. UniSync outperforms existing methods on standard datasets and demonstrates versatility across diverse audio-visual representations. Its integration into talking face generation frameworks enhances synchronization quality in both natural and AI-generated content.
JAQ: Joint Efficient Architecture Design and Low-Bit Quantization with Hardware-Software Co-Exploration
Jan 09, 2025



The co-design of neural network architectures, quantization precisions, and hardware accelerators offers a promising approach to achieving an optimal balance between performance and efficiency, particularly for model deployment on resource-constrained edge devices. In this work, we propose the JAQ Framework, which jointly optimizes the three critical dimensions. However, effectively automating the design process across the vast search space of those three dimensions poses significant challenges, especially when pursuing extremely low-bit quantization. Specifical, the primary challenges include: (1) Memory overhead in software-side: Low-precision quantization-aware training can lead to significant memory usage due to storing large intermediate features and latent weights for back-propagation, potentially causing memory exhaustion. (2) Search time-consuming in hardware-side: The discrete nature of hardware parameters and the complex interplay between compiler optimizations and individual operators make the accelerator search time-consuming. To address these issues, JAQ mitigates the memory overhead through a channel-wise sparse quantization (CSQ) scheme, selectively applying quantization to the most sensitive components of the model during optimization. Additionally, JAQ designs BatchTile, which employs a hardware generation network to encode all possible tiling modes, thereby speeding up the search for the optimal compiler mapping strategy. Extensive experiments demonstrate the effectiveness of JAQ, achieving approximately 7% higher Top-1 accuracy on ImageNet compared to previous methods and reducing the hardware search time per iteration to 0.15 seconds.
Iterative-in-Iterative Super-Resolution Biomedical Imaging Using One Real Image
Jun 26, 2023Deep learning-based super-resolution models have the potential to revolutionize biomedical imaging and diagnoses by effectively tackling various challenges associated with early detection, personalized medicine, and clinical automation. However, the requirement of an extensive collection of high-resolution images presents limitations for widespread adoption in clinical practice. In our experiment, we proposed an approach to effectively train the deep learning-based super-resolution models using only one real image by leveraging self-generated high-resolution images. We employed a mixed metric of image screening to automatically select images with a distribution similar to ground truth, creating an incrementally curated training data set that encourages the model to generate improved images over time. After five training iterations, the proposed deep learning-based super-resolution model experienced a 7.5\% and 5.49\% improvement in structural similarity and peak-signal-to-noise ratio, respectively. Significantly, the model consistently produces visually enhanced results for training, improving its performance while preserving the characteristics of original biomedical images. These findings indicate a potential way to train a deep neural network in a self-revolution manner independent of real-world human data.
Self-similarity-based super-resolution of photoacoustic angiography from hand-drawn doodles
May 02, 2023Deep-learning-based super-resolution photoacoustic angiography (PAA) is a powerful tool that restores blood vessel images from under-sampled images to facilitate disease diagnosis. Nonetheless, due to the scarcity of training samples, PAA super-resolution models often exhibit inadequate generalization capabilities, particularly in the context of continuous monitoring tasks. To address this challenge, we propose a novel approach that employs a super-resolution PAA method trained with forged PAA images. We start by generating realistic PAA images of human lips from hand-drawn curves using a diffusion-based image generation model. Subsequently, we train a self-similarity-based super-resolution model with these forged PAA images. Experimental results show that our method outperforms the super-resolution model trained with authentic PAA images in both original-domain and cross-domain tests. Specially, our approach boosts the quality of super-resolution reconstruction using the images forged by the deep learning model, indicating that the collaboration between deep learning models can facilitate generalization, despite limited initial dataset. This approach shows promising potential for exploring zero-shot learning neural networks for vision tasks.
Silicon Photonics in Optical Access Networks for 5G Communications
May 12, 2021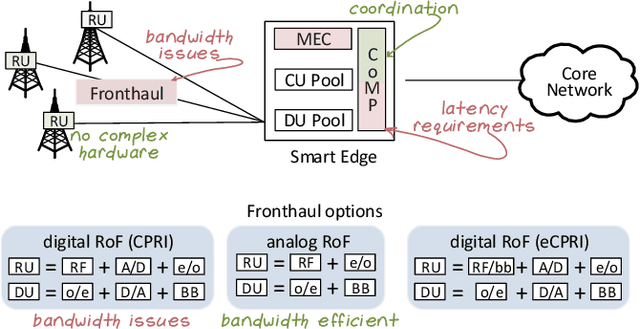
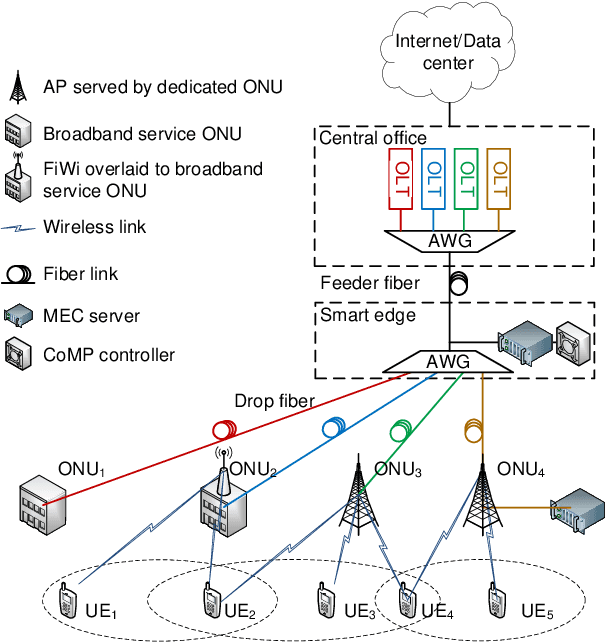

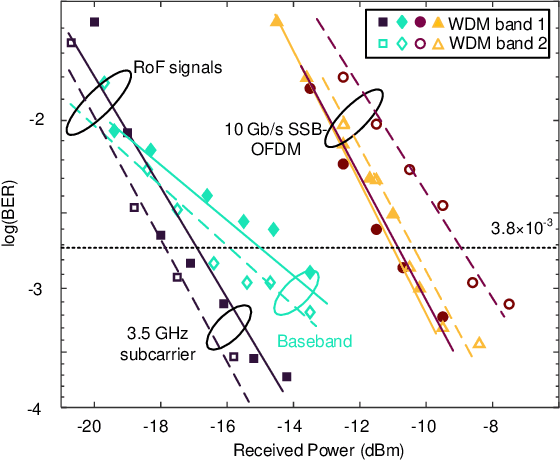
Only radio access networks can provide connectivity across multiple antenna sites to achieve the great leap forward in capacity targeted by 5G. Optical fronthaul remains a sticking point in that connectivity, and we make the case for analog radio over fiber signals and an optical access network smartedge to achieve the potential of radio access networks. The edge of the network would house the intelligence that coordinates wireless transmissions to minimize interference and maximize throughput. As silicon photonics provides a hardware platform well adapted to support optical fronthaul, it is poised to drive smart edge adoption. We draw out the issues in adopting oursolution, propose a strategy for network densification, and cite recent demonstrations to support our approach.