 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKwai Keye-VL-2.0 Technical Report
Jun 09, 2026We introduce Kwai Keye-VL-2.0-30B-A3B, an open-source Mixture-of-Experts (MoE) multimodal foundation model designed to advance long-video understanding and agentic intelligence. To address the challenges of ultra-long contexts, information redundancy, and prohibitive computational costs inherent in hour-level videos, Keye-VL-2.0 is the first to adapt DeepSeek Sparse Attention (DSA) to GQA-based multimodal architectures, enabling lossless 256K context processing while capturing critical frames and long-range temporal dependencies. This architecture is underpinned by a highly optimized training and inference infrastructure, including scalable video I/O, heterogeneous ViT-LM parallelism, and custom DSA kernels that significantly maximize throughput and minimize computational overhead. Furthermore, to overcome the algorithmic dilemma of catastrophic forgetting during multi-task alignment, we introduce Cross-Modal Multi-Teacher On-Policy Distillation (MOPD) paired with Context-RL and Video-RL. By distilling dense token-level teacher feedback from on-policy rollouts back into the MoE backbone, which activates only 3B parameters, Keye-VL-2.0 natively empowers advanced agent collaboration across Code, Tool, and Search scenarios with multimodal self-correction. Extensive evaluations across video understanding, temporal grounding, reasoning, STEM, and agent benchmarks demonstrate that Keye-VL-2.0-30B-A3B achieves state-of-the-art performance among models of similar scale, particularly excelling in fine-grained temporal localization on TimeLens and long-video comprehension on Video-MME-v2 and LongVideoBench. We release our model checkpoints to accelerate community progress toward scalable and robust multimodal agentic applications.
Analytic Task Scheduler: Recursive Least Squares Based Method for Continual Learning in Embodied Foundation Models
Jun 11, 2025Embodied foundation models are crucial for Artificial Intelligence (AI) interacting with the physical world by integrating multi-modal inputs, such as proprioception, vision and language, to understand human intentions and generate actions to control robots. While these models demonstrate strong generalization and few-shot learning capabilities, they face significant challenges in continually acquiring new skills without forgetting previously learned skills, a problem known as catastrophic forgetting. To address this issue, we propose the Analytic Task Scheduler (ATS), a novel framework for continual learning in embodied foundation models. ATS consists of a task-specific model library, where each model is fine-tuned independently on a single task, and an analytic scheduler trained using recursive least squares (RLS) to learn the mapping between language instructions and task-specific models. This architecture enables accurate task recognition and dynamic model selection while fundamentally avoiding parameter interference across tasks. The scheduler updates its parameters incrementally using only statistics (autocorrelation and cross-correlation matrices), enabling forgetting-resistant learning without the need to revisit historical data. We validate ATS on a real-world robot platform (RM65B), demonstrating superior resistance to forgetting and strong adaptability to task variations. The results highlight ATS as an effective, scalable, and deployable solution for continual learning in embodied foundation models operating in complex, dynamic environments. Our code will be available at https://github.com/MIAA-Embodied-AI/AnalyticTaskScheduler
Learning Free Token Reduction for Multi-Modal LLM
Jan 29, 2025



Vision-Language Models (VLMs) have achieved remarkable success across a range of multimodal tasks; however, their practical deployment is often constrained by high computational costs and prolonged inference times. Since the vision modality typically carries more information than the text modality, compressing visual prompts offers a promising solution to alleviate these challenges. Existing approaches predominantly focus on refining model architectures or directly reducing the number of visual tokens. However, these methods often compromise inference performance due to a lack of consideration for the unique spatial and temporal characteristics of visual data. In this work, we propose a token compression paradigm that operates on both spatial and temporal dimensions. Our approach includes a learning-free, plug-and-play compression pipeline that can be seamlessly integrated into most Multimodal Large Language Model (MLLM) frameworks. By leveraging this method, we enhance the model inference capability while simultaneously reducing its computational cost. Experimental results on the Video-QA task demonstrate the effectiveness of the proposed approach, showcasing significant improvements in efficiency without sacrificing performance.
JAQ: Joint Efficient Architecture Design and Low-Bit Quantization with Hardware-Software Co-Exploration
Jan 09, 2025



The co-design of neural network architectures, quantization precisions, and hardware accelerators offers a promising approach to achieving an optimal balance between performance and efficiency, particularly for model deployment on resource-constrained edge devices. In this work, we propose the JAQ Framework, which jointly optimizes the three critical dimensions. However, effectively automating the design process across the vast search space of those three dimensions poses significant challenges, especially when pursuing extremely low-bit quantization. Specifical, the primary challenges include: (1) Memory overhead in software-side: Low-precision quantization-aware training can lead to significant memory usage due to storing large intermediate features and latent weights for back-propagation, potentially causing memory exhaustion. (2) Search time-consuming in hardware-side: The discrete nature of hardware parameters and the complex interplay between compiler optimizations and individual operators make the accelerator search time-consuming. To address these issues, JAQ mitigates the memory overhead through a channel-wise sparse quantization (CSQ) scheme, selectively applying quantization to the most sensitive components of the model during optimization. Additionally, JAQ designs BatchTile, which employs a hardware generation network to encode all possible tiling modes, thereby speeding up the search for the optimal compiler mapping strategy. Extensive experiments demonstrate the effectiveness of JAQ, achieving approximately 7% higher Top-1 accuracy on ImageNet compared to previous methods and reducing the hardware search time per iteration to 0.15 seconds.
EMS: Adaptive Evict-then-Merge Strategy for Head-wise KV Cache Compression Based on Global-Local Importance
Dec 11, 2024As large language models (LLMs) continue to advance, the demand for higher quality and faster processing of long contexts across various applications is growing. KV cache is widely adopted as it stores previously generated key and value tokens, effectively reducing redundant computations during inference. However, as memory overhead becomes a significant concern, efficient compression of KV cache has gained increasing attention. Most existing methods perform compression from two perspectives: identifying important tokens and designing compression strategies. However, these approaches often produce biased distributions of important tokens due to the influence of accumulated attention scores or positional encoding. Furthermore, they overlook the sparsity and redundancy across different heads, which leads to difficulties in preserving the most effective information at the head level. To this end, we propose EMS to overcome these limitations, while achieving better KV cache compression under extreme compression ratios. Specifically, we introduce a Global-Local score that combines accumulated attention scores from both global and local KV tokens to better identify the token importance. For the compression strategy, we design an adaptive and unified Evict-then-Merge framework that accounts for the sparsity and redundancy of KV tokens across different heads. Additionally, we implement the head-wise parallel compression through a zero-class mechanism to enhance efficiency. Extensive experiments demonstrate our SOTA performance even under extreme compression ratios. EMS consistently achieves the lowest perplexity, improves scores by over 1.28 points across four LLMs on LongBench under a 256 cache budget, and preserves 95% retrieval accuracy with a cache budget less than 2% of the context length in the Needle-in-a-Haystack task.
Towards NeuroAI: Introducing Neuronal Diversity into Artificial Neural Networks
Jan 23, 2023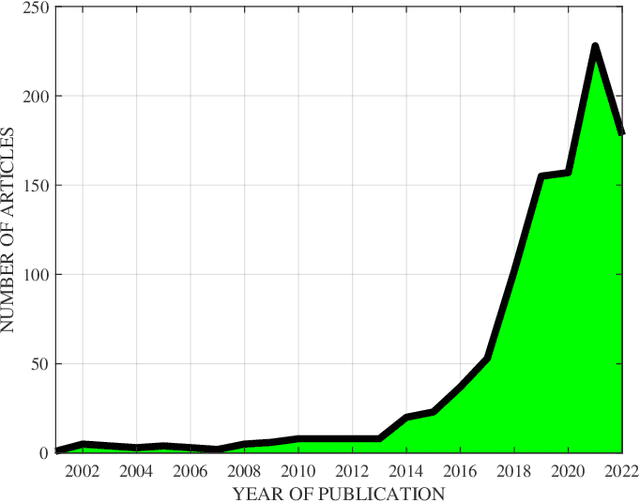
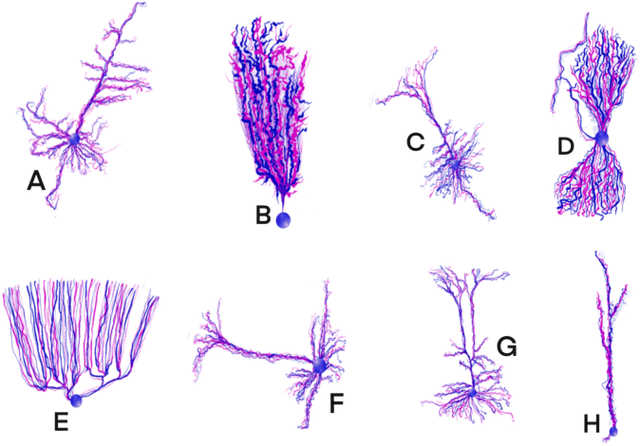
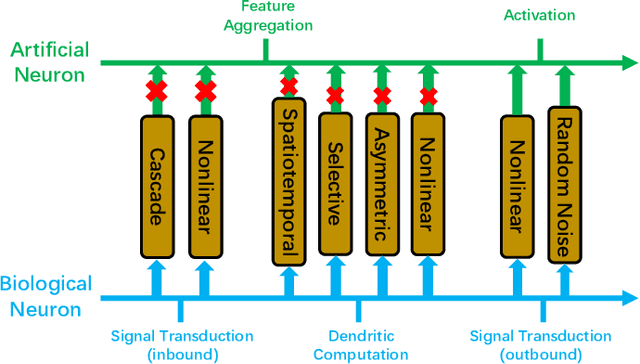
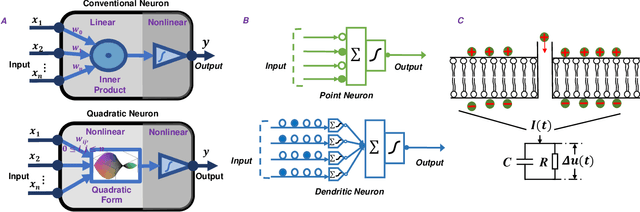
Throughout history, the development of artificial intelligence, particularly artificial neural networks, has been open to and constantly inspired by the increasingly deepened understanding of the brain, such as the inspiration of neocognitron, which is the pioneering work of convolutional neural networks. Per the motives of the emerging field: NeuroAI, a great amount of neuroscience knowledge can help catalyze the next generation of AI by endowing a network with more powerful capabilities. As we know, the human brain has numerous morphologically and functionally different neurons, while artificial neural networks are almost exclusively built on a single neuron type. In the human brain, neuronal diversity is an enabling factor for all kinds of biological intelligent behaviors. Since an artificial network is a miniature of the human brain, introducing neuronal diversity should be valuable in terms of addressing those essential problems of artificial networks such as efficiency, interpretability, and memory. In this Primer, we first discuss the preliminaries of biological neuronal diversity and the characteristics of information transmission and processing in a biological neuron. Then, we review studies of designing new neurons for artificial networks. Next, we discuss what gains can neuronal diversity bring into artificial networks and exemplary applications in several important fields. Lastly, we discuss the challenges and future directions of neuronal diversity to explore the potential of NeuroAI.