 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMaster Micro Residual Correction with Adaptive Tactile Fusion and Force-Mixed Control for Contact-Rich Manipulation
Mar 16, 2026Robotic contact-rich and fine-grained manipulation remains a significant challenge due to complex interaction dynamics and the competing requirements of multi-timescale control. While current visual imitation learning methods excel at long-horizon planning, they often fail to perceive critical interaction cues like friction variations or incipient slip, and struggle to balance global task coherence with local reactive feedback. To address these challenges, we propose M2-ResiPolicy, a novel Master-Micro residual control architecture that synergizes high-level action guidance with low-level correction. The framework consists of a Master-Guidance Policy (MGP) operating at 10 Hz, which generates temporally consistent action chunks via a diffusion-based backbone and employs a tactile-intensity-driven adaptive fusion mechanism to dynamically modulate perceptual weights between vision and touch. Simultaneously, a high-frequency (60 Hz) Micro-Residual Corrector (MRC) utilizes a lightweight GRU to provide real-time action compensation based on TCP wrench feedback. This policy is further integrated with a force-mixed PBIC execution layer, effectively regulating contact forces to ensure interaction safety. Experiments across several demanding tasks including fragile object grasping and precision insertion, demonstrate that M2-ResiPolicy significantly outperforms standard Diffusion Policy (DP) and state-of-the-art Reactive Diffusion Policy (RDP), achieving a 93\% damage-free success rate in chip grasping and superior force regulation stability.
E^2-LLM: Bridging Neural Signals and Interpretable Affective Analysis
Jan 11, 2026Emotion recognition from electroencephalography (EEG) signals remains challenging due to high inter-subject variability, limited labeled data, and the lack of interpretable reasoning in existing approaches. While recent multimodal large language models (MLLMs) have advanced emotion analysis, they have not been adapted to handle the unique spatiotemporal characteristics of neural signals. We present E^2-LLM (EEG-to-Emotion Large Language Model), the first MLLM framework for interpretable emotion analysis from EEG. E^2-LLM integrates a pretrained EEG encoder with Qwen-based LLMs through learnable projection layers, employing a multi-stage training pipeline that encompasses emotion-discriminative pretraining, cross-modal alignment, and instruction tuning with chain-of-thought reasoning. We design a comprehensive evaluation protocol covering basic emotion prediction, multi-task reasoning, and zero-shot scenario understanding. Experiments on the dataset across seven emotion categories demonstrate that E^2-LLM achieves excellent performance on emotion classification, with larger variants showing enhanced reliability and superior zero-shot generalization to complex reasoning scenarios. Our work establishes a new paradigm combining physiological signals with LLM reasoning capabilities, showing that model scaling improves both recognition accuracy and interpretable emotional understanding in affective computing.
FlexiCup: Wireless Multimodal Suction Cup with Dual-Zone Vision-Tactile Sensing
Nov 18, 2025
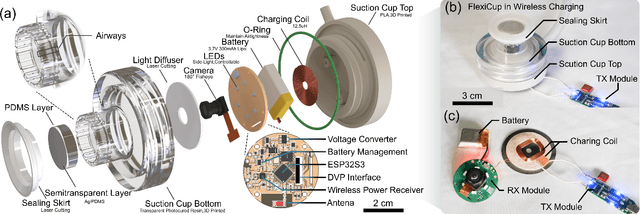
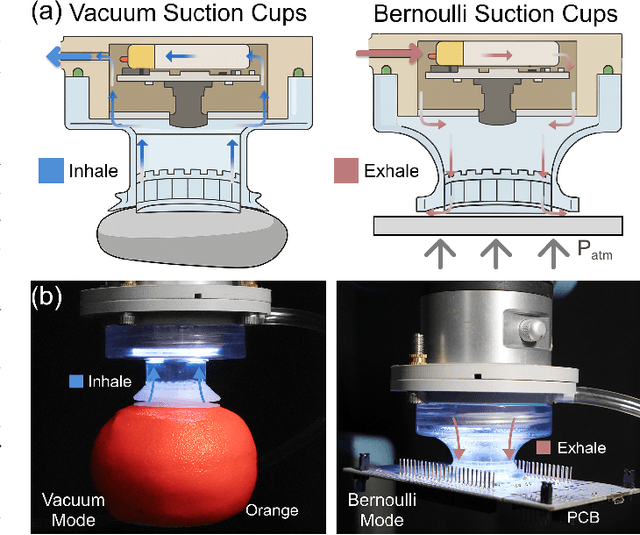
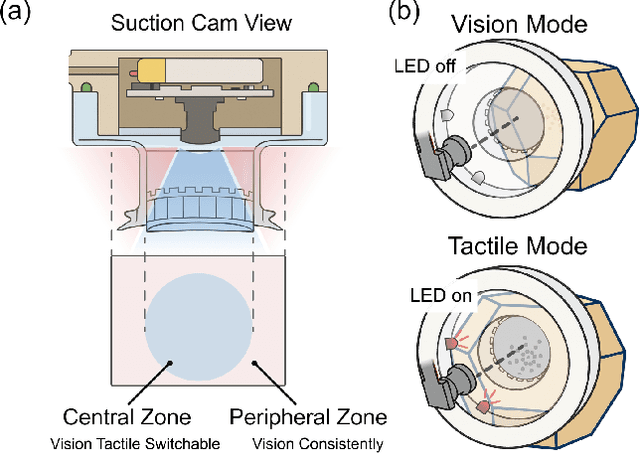
Conventional suction cups lack sensing capabilities for contact-aware manipulation in unstructured environments. This paper presents FlexiCup, a fully wireless multimodal suction cup that integrates dual-zone vision-tactile sensing. The central zone dynamically switches between vision and tactile modalities via illumination control for contact detection, while the peripheral zone provides continuous spatial awareness for approach planning. FlexiCup supports both vacuum and Bernoulli suction modes through modular mechanical configurations, achieving complete wireless autonomy with onboard computation and power. We validate hardware versatility through dual control paradigms. Modular perception-driven grasping across structured surfaces with varying obstacle densities demonstrates comparable performance between vacuum (90.0% mean success) and Bernoulli (86.7% mean success) modes. Diffusion-based end-to-end learning achieves 73.3% success on inclined transport and 66.7% on orange extraction tasks. Ablation studies confirm that multi-head attention coordinating dual-zone observations provides 13% improvements for contact-aware manipulation. Hardware designs and firmware are available at https://anonymous.4open.science/api/repo/FlexiCup-DA7D/file/index.html?v=8f531b44.
Universal Visuo-Tactile Video Understanding for Embodied Interaction
May 28, 2025



Tactile perception is essential for embodied agents to understand physical attributes of objects that cannot be determined through visual inspection alone. While existing approaches have made progress in visual and language modalities for physical understanding, they fail to effectively incorporate tactile information that provides crucial haptic feedback for real-world interaction. In this paper, we present VTV-LLM, the first multi-modal large language model for universal Visuo-Tactile Video (VTV) understanding that bridges the gap between tactile perception and natural language. To address the challenges of cross-sensor and cross-modal integration, we contribute VTV150K, a comprehensive dataset comprising 150,000 video frames from 100 diverse objects captured across three different tactile sensors (GelSight Mini, DIGIT, and Tac3D), annotated with four fundamental tactile attributes (hardness, protrusion, elasticity, and friction). We develop a novel three-stage training paradigm that includes VTV enhancement for robust visuo-tactile representation, VTV-text alignment for cross-modal correspondence, and text prompt finetuning for natural language generation. Our framework enables sophisticated tactile reasoning capabilities including feature assessment, comparative analysis, scenario-based decision making and so on. Experimental evaluations demonstrate that VTV-LLM achieves superior performance in tactile video understanding tasks, establishing a foundation for more intuitive human-machine interaction in tactile domains.
Matching Distance and Geometric Distribution Aided Learning Multiview Point Cloud Registration
May 06, 2025



Multiview point cloud registration plays a crucial role in robotics, automation, and computer vision fields. This paper concentrates on pose graph construction and motion synchronization within multiview registration. Previous methods for pose graph construction often pruned fully connected graphs or constructed sparse graph using global feature aggregated from local descriptors, which may not consistently yield reliable results. To identify dependable pairs for pose graph construction, we design a network model that extracts information from the matching distance between point cloud pairs. For motion synchronization, we propose another neural network model to calculate the absolute pose in a data-driven manner, rather than optimizing inaccurate handcrafted loss functions. Our model takes into account geometric distribution information and employs a modified attention mechanism to facilitate flexible and reliable feature interaction. Experimental results on diverse indoor and outdoor datasets confirm the effectiveness and generalizability of our approach. The source code is available at https://github.com/Shi-Qi-Li/MDGD.
MuseFace: Text-driven Face Editing via Diffusion-based Mask Generation Approach
Mar 31, 2025
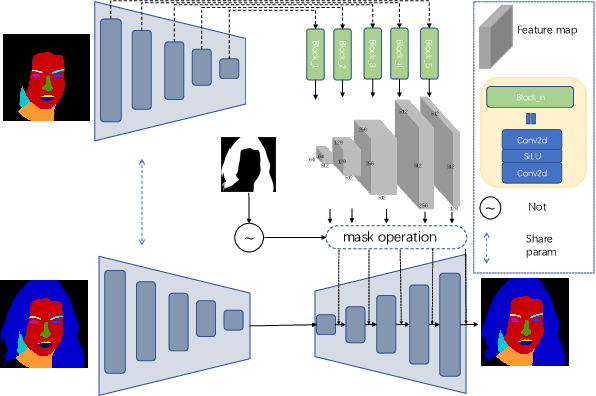
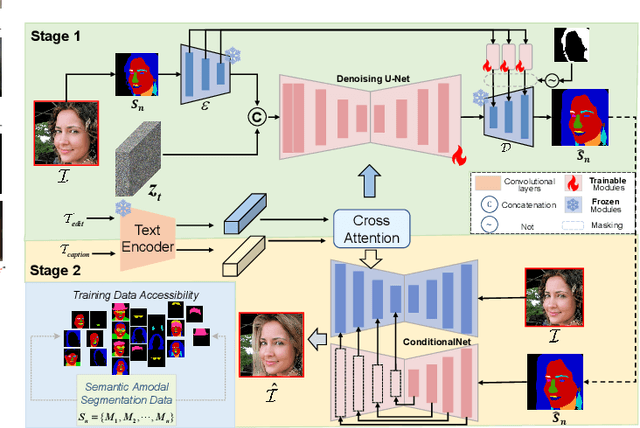
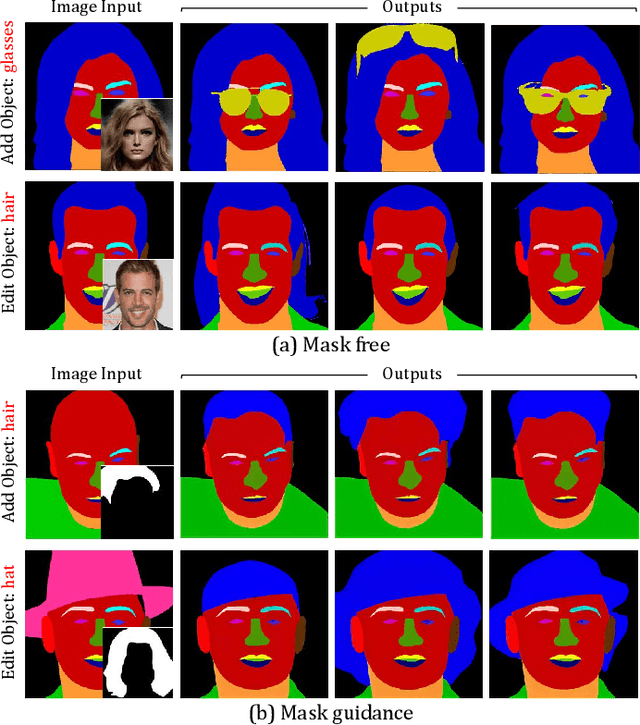
Face editing modifies the appearance of face, which plays a key role in customization and enhancement of personal images. Although much work have achieved remarkable success in text-driven face editing, they still face significant challenges as none of them simultaneously fulfill the characteristics of diversity, controllability and flexibility. To address this challenge, we propose MuseFace, a text-driven face editing framework, which relies solely on text prompt to enable face editing. Specifically, MuseFace integrates a Text-to-Mask diffusion model and a semantic-aware face editing model, capable of directly generating fine-grained semantic masks from text and performing face editing. The Text-to-Mask diffusion model provides \textit{diversity} and \textit{flexibility} to the framework, while the semantic-aware face editing model ensures \textit{controllability} of the framework. Our framework can create fine-grained semantic masks, making precise face editing possible, and significantly enhancing the controllability and flexibility of face editing models. Extensive experiments demonstrate that MuseFace achieves superior high-fidelity performance.
Object Isolated Attention for Consistent Story Visualization
Mar 30, 2025Open-ended story visualization is a challenging task that involves generating coherent image sequences from a given storyline. One of the main difficulties is maintaining character consistency while creating natural and contextually fitting scenes--an area where many existing methods struggle. In this paper, we propose an enhanced Transformer module that uses separate self attention and cross attention mechanisms, leveraging prior knowledge from pre-trained diffusion models to ensure logical scene creation. The isolated self attention mechanism improves character consistency by refining attention maps to reduce focus on irrelevant areas and highlight key features of the same character. Meanwhile, the isolated cross attention mechanism independently processes each character's features, avoiding feature fusion and further strengthening consistency. Notably, our method is training-free, allowing the continuous generation of new characters and storylines without re-tuning. Both qualitative and quantitative evaluations show that our approach outperforms current methods, demonstrating its effectiveness.
UniSync: A Unified Framework for Audio-Visual Synchronization
Mar 20, 2025Precise audio-visual synchronization in speech videos is crucial for content quality and viewer comprehension. Existing methods have made significant strides in addressing this challenge through rule-based approaches and end-to-end learning techniques. However, these methods often rely on limited audio-visual representations and suboptimal learning strategies, potentially constraining their effectiveness in more complex scenarios. To address these limitations, we present UniSync, a novel approach for evaluating audio-visual synchronization using embedding similarities. UniSync offers broad compatibility with various audio representations (e.g., Mel spectrograms, HuBERT) and visual representations (e.g., RGB images, face parsing maps, facial landmarks, 3DMM), effectively handling their significant dimensional differences. We enhance the contrastive learning framework with a margin-based loss component and cross-speaker unsynchronized pairs, improving discriminative capabilities. UniSync outperforms existing methods on standard datasets and demonstrates versatility across diverse audio-visual representations. Its integration into talking face generation frameworks enhances synchronization quality in both natural and AI-generated content.
Observation-Graph Interaction and Key-Detail Guidance for Vision and Language Navigation
Mar 14, 2025Vision and Language Navigation (VLN) requires an agent to navigate through environments following natural language instructions. However, existing methods often struggle with effectively integrating visual observations and instruction details during navigation, leading to suboptimal path planning and limited success rates. In this paper, we propose OIKG (Observation-graph Interaction and Key-detail Guidance), a novel framework that addresses these limitations through two key components: (1) an observation-graph interaction module that decouples angular and visual information while strengthening edge representations in the navigation space, and (2) a key-detail guidance module that dynamically extracts and utilizes fine-grained location and object information from instructions. By enabling more precise cross-modal alignment and dynamic instruction interpretation, our approach significantly improves the agent's ability to follow complex navigation instructions. Extensive experiments on the R2R and RxR datasets demonstrate that OIKG achieves state-of-the-art performance across multiple evaluation metrics, validating the effectiveness of our method in enhancing navigation precision through better observation-instruction alignment.
Unseen Horizons: Unveiling the Real Capability of LLM Code Generation Beyond the Familiar
Dec 11, 2024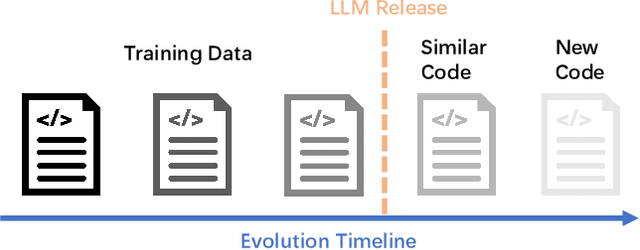

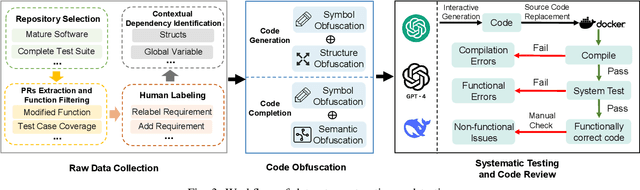
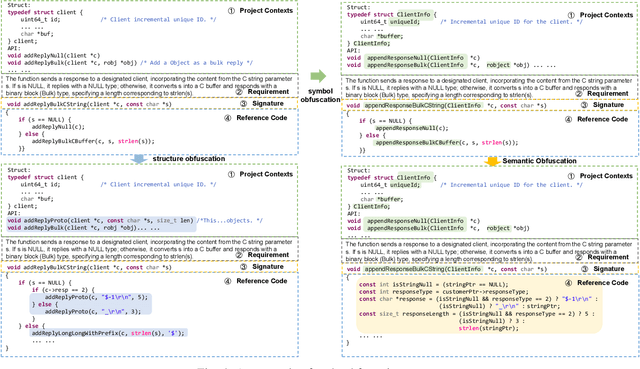
Recently, large language models (LLMs) have shown strong potential in code generation tasks. However, there are still gaps before they can be fully applied in actual software development processes. Accurately assessing the code generation capabilities of large language models has become an important basis for evaluating and improving the models. Some existing works have constructed datasets to evaluate the capabilities of these models. However, the current evaluation process may encounter the illusion of "Specialist in Familiarity", primarily due to three gaps: the exposure of target code, case timeliness, and dependency availability. The fundamental reason for these gaps is that the code in current datasets may have been extensively exposed and exercised during the training phase, and due to the continuous training and development of LLM, their timeliness has been severely compromised. The key to solve the problem is to, as much as possible, evaluate the LLMs using code that they have not encountered before. Thus, the fundamental idea in this paper is to draw on the concept of code obfuscation, changing code at different levels while ensuring the functionality and output. To this end, we build a code-obfuscation based benchmark OBFUSEVAL. We first collect 1,354 raw cases from five real-world projects, including function description and code. Then we use three-level strategy (symbol, structure and semantic) to obfuscate descriptions, code and context dependencies. We evaluate four LLMs on OBFU- SEVAL and compared the effectiveness of different obfuscation strategy. We use official test suites of these projects to evaluate the generated code. The results show that after obfuscation, the average decrease ratio of test pass rate can up to 62.5%.