 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLoad-Aware Locomotion Control for Humanoid Robots in Industrial Transportation Tasks
Mar 15, 2026Humanoid robots deployed in industrial environments are required to perform load-carrying transportation tasks that tightly couple locomotion and manipulation. However, achieving stable and robust locomotion under varying payloads and upper-body motions is challenging due to dynamic coupling and partial observability. This paper presents a load-aware locomotion framework for industrial humanoids based on a decoupled yet coordinated loco-manipulation architecture. Lower-body locomotion is controlled via a reinforcement learning policy producing residual joint actions on kinematically derived nominal configurations. A kinematics-based locomotion reference with a height-conditioned joint-space offset guides learning, while a history-based state estimator infers base linear velocity and height and encodes residual load- and manipulation-induced disturbances in a compact latent representation. The framework is trained entirely in simulation and deployed on a full-size humanoid robot without fine-tuning. Simulation and real-world experiments demonstrate faster training, accurate height tracking, and stable loco-manipulation. Project page: https://lequn-f.github.io/LALO/
IGASA: Integrated Geometry-Aware and Skip-Attention Modules for Enhanced Point Cloud Registration
Mar 13, 2026Point cloud registration (PCR) is a fundamental task in 3D vision and provides essential support for applications such as autonomous driving, robotics, and environmental modeling. Despite its widespread use, existing methods often fail when facing real-world challenges like heavy noise, significant occlusions, and large-scale transformations. These limitations frequently result in compromised registration accuracy and insufficient robustness in complex environments. In this paper, we propose IGASA as a novel registration framework constructed upon a Hierarchical Pyramid Architecture (HPA) designed for robust multi-scale feature extraction and fusion. The framework integrates two pivotal components consisting of the Hierarchical Cross-Layer Attention (HCLA) module and the Iterative Geometry-Aware Refinement (IGAR) module. The HCLA module utilizes skip attention mechanisms to align multi-resolution features and enhance local geometric consistency. Simultaneously, the IGAR module is designed for the fine matching phase by leveraging reliable correspondences established during coarse matching. This synergistic integration within the architecture allows IGASA to adapt effectively to diverse point cloud structures and intricate transformations. We evaluate the performance of IGASA on four widely recognized benchmark datasets including 3D(Lo)Match, KITTI, and nuScenes. Our extensive experiments consistently demonstrate that IGASA significantly surpasses state-of-the-art methods and achieves notable improvements in registration accuracy. This work provides a robust foundation for advancing point cloud registration techniques while offering valuable insights for practical 3D vision applications. The code for IGASA is available in \href{https://github.com/DongXu-Zhang/IGASA}{https://github.com/DongXu-Zhang/IGASA}.
Matching Distance and Geometric Distribution Aided Learning Multiview Point Cloud Registration
May 06, 2025



Multiview point cloud registration plays a crucial role in robotics, automation, and computer vision fields. This paper concentrates on pose graph construction and motion synchronization within multiview registration. Previous methods for pose graph construction often pruned fully connected graphs or constructed sparse graph using global feature aggregated from local descriptors, which may not consistently yield reliable results. To identify dependable pairs for pose graph construction, we design a network model that extracts information from the matching distance between point cloud pairs. For motion synchronization, we propose another neural network model to calculate the absolute pose in a data-driven manner, rather than optimizing inaccurate handcrafted loss functions. Our model takes into account geometric distribution information and employs a modified attention mechanism to facilitate flexible and reliable feature interaction. Experimental results on diverse indoor and outdoor datasets confirm the effectiveness and generalizability of our approach. The source code is available at https://github.com/Shi-Qi-Li/MDGD.
XiYan-SQL: A Multi-Generator Ensemble Framework for Text-to-SQL
Nov 13, 2024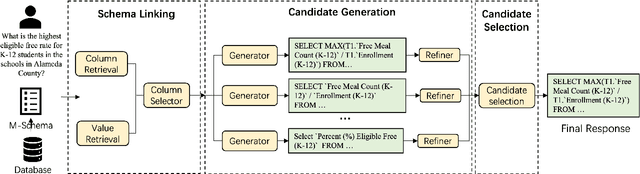
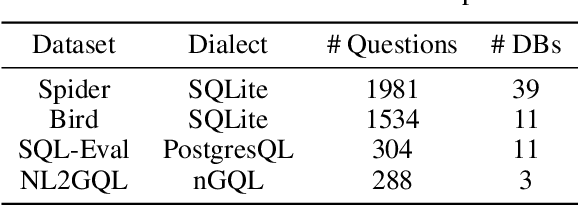


To tackle the challenges of large language model performance in natural language to SQL tasks, we introduce XiYan-SQL, an innovative framework that employs a multi-generator ensemble strategy to improve candidate generation. We introduce M-Schema, a semi-structured schema representation method designed to enhance the understanding of database structures. To enhance the quality and diversity of generated candidate SQL queries, XiYan-SQL integrates the significant potential of in-context learning (ICL) with the precise control of supervised fine-tuning. On one hand, we propose a series of training strategies to fine-tune models to generate high-quality candidates with diverse preferences. On the other hand, we implement the ICL approach with an example selection method based on named entity recognition to prevent overemphasis on entities. The refiner optimizes each candidate by correcting logical or syntactical errors. To address the challenge of identifying the best candidate, we fine-tune a selection model to distinguish nuances of candidate SQL queries. The experimental results on multiple dialect datasets demonstrate the robustness of XiYan-SQL in addressing challenges across different scenarios. Overall, our proposed XiYan-SQL achieves the state-of-the-art execution accuracy of 89.65% on the Spider test set, 69.86% on SQL-Eval, 41.20% on NL2GQL, and a competitive score of 72.23% on the Bird development benchmark. The proposed framework not only enhances the quality and diversity of SQL queries but also outperforms previous methods.
3D-JEPA: A Joint Embedding Predictive Architecture for 3D Self-Supervised Representation Learning
Sep 24, 2024Invariance-based and generative methods have shown a conspicuous performance for 3D self-supervised representation learning (SSRL). However, the former relies on hand-crafted data augmentations that introduce bias not universally applicable to all downstream tasks, and the latter indiscriminately reconstructs masked regions, resulting in irrelevant details being saved in the representation space. To solve the problem above, we introduce 3D-JEPA, a novel non-generative 3D SSRL framework. Specifically, we propose a multi-block sampling strategy that produces a sufficiently informative context block and several representative target blocks. We present the context-aware decoder to enhance the reconstruction of the target blocks. Concretely, the context information is fed to the decoder continuously, facilitating the encoder in learning semantic modeling rather than memorizing the context information related to target blocks. Overall, 3D-JEPA predicts the representation of target blocks from a context block using the encoder and context-aware decoder architecture. Various downstream tasks on different datasets demonstrate 3D-JEPA's effectiveness and efficiency, achieving higher accuracy with fewer pretraining epochs, e.g., 88.65% accuracy on PB_T50_RS with 150 pretraining epochs.
Multiple Rotation Averaging with Constrained Reweighting Deep Matrix Factorization
Sep 15, 2024Multiple rotation averaging plays a crucial role in computer vision and robotics domains. The conventional optimization-based methods optimize a nonlinear cost function based on certain noise assumptions, while most previous learning-based methods require ground truth labels in the supervised training process. Recognizing the handcrafted noise assumption may not be reasonable in all real-world scenarios, this paper proposes an effective rotation averaging method for mining data patterns in a learning manner while avoiding the requirement of labels. Specifically, we apply deep matrix factorization to directly solve the multiple rotation averaging problem in unconstrained linear space. For deep matrix factorization, we design a neural network model, which is explicitly low-rank and symmetric to better suit the background of multiple rotation averaging. Meanwhile, we utilize a spanning tree-based edge filtering to suppress the influence of rotation outliers. What's more, we also adopt a reweighting scheme and dynamic depth selection strategy to further improve the robustness. Our method synthesizes the merit of both optimization-based and learning-based methods. Experimental results on various datasets validate the effectiveness of our proposed method.
Incremental Multiview Point Cloud Registration with Two-stage Candidate Retrieval
Jul 10, 2024



Multiview point cloud registration serves as a cornerstone of various computer vision tasks. Previous approaches typically adhere to a global paradigm, where a pose graph is initially constructed followed by motion synchronization to determine the absolute pose. However, this separated approach may not fully leverage the characteristics of multiview registration and might struggle with low-overlap scenarios. In this paper, we propose an incremental multiview point cloud registration method that progressively registers all scans to a growing meta-shape. To determine the incremental ordering, we employ a two-stage coarse-to-fine strategy for point cloud candidate retrieval. The first stage involves the coarse selection of scans based on neighbor fusion-enhanced global aggregation features, while the second stage further reranks candidates through geometric-based matching. Additionally, we apply a transformation averaging technique to mitigate accumulated errors during the registration process. Finally, we utilize a Reservoir sampling-based technique to address density variance issues while reducing computational load. Comprehensive experimental results across various benchmarks validate the effectiveness and generalization of our approach.
Iterative Feedback Network for Unsupervised Point Cloud Registration
Jan 09, 2024

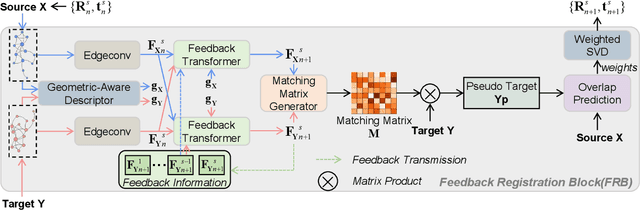

As a fundamental problem in computer vision, point cloud registration aims to seek the optimal transformation for aligning a pair of point clouds. In most existing methods, the information flows are usually forward transferring, thus lacking the guidance from high-level information to low-level information. Besides, excessive high-level information may be overly redundant, and directly using it may conflict with the original low-level information. In this paper, we propose a novel Iterative Feedback Network (IFNet) for unsupervised point cloud registration, in which the representation of low-level features is efficiently enriched by rerouting subsequent high-level features. Specifically, our IFNet is built upon a series of Feedback Registration Block (FRB) modules, with each module responsible for generating the feedforward rigid transformation and feedback high-level features. These FRB modules are cascaded and recurrently unfolded over time. Further, the Feedback Transformer is designed to efficiently select relevant information from feedback high-level features, which is utilized to refine the low-level features. What's more, we incorporate a geometry-awareness descriptor to empower the network for making full use of most geometric information, which leads to more precise registration results. Extensive experiments on various benchmark datasets demonstrate the superior registration performance of our IFNet.
Cross-Modal Information-Guided Network using Contrastive Learning for Point Cloud Registration
Nov 02, 2023The majority of point cloud registration methods currently rely on extracting features from points. However, these methods are limited by their dependence on information obtained from a single modality of points, which can result in deficiencies such as inadequate perception of global features and a lack of texture information. Actually, humans can employ visual information learned from 2D images to comprehend the 3D world. Based on this fact, we present a novel Cross-Modal Information-Guided Network (CMIGNet), which obtains global shape perception through cross-modal information to achieve precise and robust point cloud registration. Specifically, we first incorporate the projected images from the point clouds and fuse the cross-modal features using the attention mechanism. Furthermore, we employ two contrastive learning strategies, namely overlapping contrastive learning and cross-modal contrastive learning. The former focuses on features in overlapping regions, while the latter emphasizes the correspondences between 2D and 3D features. Finally, we propose a mask prediction module to identify keypoints in the point clouds. Extensive experiments on several benchmark datasets demonstrate that our network achieves superior registration performance.
DBDNet:Partial-to-Partial Point Cloud Registration with Dual Branches Decoupling
Oct 18, 2023



Point cloud registration plays a crucial role in various computer vision tasks, and usually demands the resolution of partial overlap registration in practice. Most existing methods perform a serial calculation of rotation and translation, while jointly predicting overlap during registration, this coupling tends to degenerate the registration performance. In this paper, we propose an effective registration method with dual branches decoupling for partial-to-partial registration, dubbed as DBDNet. Specifically, we introduce a dual branches structure to eliminate mutual interference error between rotation and translation by separately creating two individual correspondence matrices. For partial-to-partial registration, we consider overlap prediction as a preordering task before the registration procedure. Accordingly, we present an overlap predictor that benefits from explicit feature interaction, which is achieved by the powerful attention mechanism to accurately predict pointwise masks. Furthermore, we design a multi-resolution feature extraction network to capture both local and global patterns thus enhancing both overlap prediction and registration module. Experimental results on both synthetic and real datasets validate the effectiveness of our proposed method.