 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHi-Agent: Hierarchical Vision-Language Agents for Mobile Device Control
Oct 16, 2025Building agents that autonomously operate mobile devices has attracted increasing attention. While Vision-Language Models (VLMs) show promise, most existing approaches rely on direct state-to-action mappings, which lack structured reasoning and planning, and thus generalize poorly to novel tasks or unseen UI layouts. We introduce Hi-Agent, a trainable hierarchical vision-language agent for mobile control, featuring a high-level reasoning model and a low-level action model that are jointly optimized. For efficient training, we reformulate multi-step decision-making as a sequence of single-step subgoals and propose a foresight advantage function, which leverages execution feedback from the low-level model to guide high-level optimization. This design alleviates the path explosion issue encountered by Group Relative Policy Optimization (GRPO) in long-horizon tasks and enables stable, critic-free joint training. Hi-Agent achieves a new State-Of-The-Art (SOTA) 87.9% task success rate on the Android-in-the-Wild (AitW) benchmark, significantly outperforming prior methods across three paradigms: prompt-based (AppAgent: 17.7%), supervised (Filtered BC: 54.5%), and reinforcement learning-based (DigiRL: 71.9%). It also demonstrates competitive zero-shot generalization on the ScreenSpot-v2 benchmark. On the more challenging AndroidWorld benchmark, Hi-Agent also scales effectively with larger backbones, showing strong adaptability in high-complexity mobile control scenarios.
PAMD: Plausibility-Aware Motion Diffusion Model for Long Dance Generation
May 26, 2025Computational dance generation is crucial in many areas, such as art, human-computer interaction, virtual reality, and digital entertainment, particularly for generating coherent and expressive long dance sequences. Diffusion-based music-to-dance generation has made significant progress, yet existing methods still struggle to produce physically plausible motions. To address this, we propose Plausibility-Aware Motion Diffusion (PAMD), a framework for generating dances that are both musically aligned and physically realistic. The core of PAMD lies in the Plausible Motion Constraint (PMC), which leverages Neural Distance Fields (NDFs) to model the actual pose manifold and guide generated motions toward a physically valid pose manifold. To provide more effective guidance during generation, we incorporate Prior Motion Guidance (PMG), which uses standing poses as auxiliary conditions alongside music features. To further enhance realism for complex movements, we introduce the Motion Refinement with Foot-ground Contact (MRFC) module, which addresses foot-skating artifacts by bridging the gap between the optimization objective in linear joint position space and the data representation in nonlinear rotation space. Extensive experiments show that PAMD significantly improves musical alignment and enhances the physical plausibility of generated motions. This project page is available at: https://mucunzhuzhu.github.io/PAMD-page/.
XiYan-SQL: A Multi-Generator Ensemble Framework for Text-to-SQL
Nov 13, 2024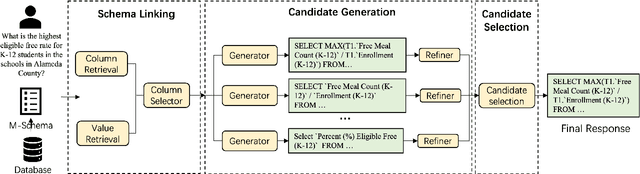


To tackle the challenges of large language model performance in natural language to SQL tasks, we introduce XiYan-SQL, an innovative framework that employs a multi-generator ensemble strategy to improve candidate generation. We introduce M-Schema, a semi-structured schema representation method designed to enhance the understanding of database structures. To enhance the quality and diversity of generated candidate SQL queries, XiYan-SQL integrates the significant potential of in-context learning (ICL) with the precise control of supervised fine-tuning. On one hand, we propose a series of training strategies to fine-tune models to generate high-quality candidates with diverse preferences. On the other hand, we implement the ICL approach with an example selection method based on named entity recognition to prevent overemphasis on entities. The refiner optimizes each candidate by correcting logical or syntactical errors. To address the challenge of identifying the best candidate, we fine-tune a selection model to distinguish nuances of candidate SQL queries. The experimental results on multiple dialect datasets demonstrate the robustness of XiYan-SQL in addressing challenges across different scenarios. Overall, our proposed XiYan-SQL achieves the state-of-the-art execution accuracy of 89.65% on the Spider test set, 69.86% on SQL-Eval, 41.20% on NL2GQL, and a competitive score of 72.23% on the Bird development benchmark. The proposed framework not only enhances the quality and diversity of SQL queries but also outperforms previous methods.
MA^2: A Self-Supervised and Motion Augmenting Autoencoder for Gait-Based Automatic Disease Detection
Nov 05, 2024Ground reaction force (GRF) is the force exerted by the ground on a body in contact with it. GRF-based automatic disease detection (ADD) has become an emerging medical diagnosis method, which aims to learn and identify disease patterns corresponding to different gait pressures based on deep learning methods. Although existing ADD methods can save doctors time in making diagnoses, training deep models still struggles with the cost caused by the labeling engineering for a large number of gait diagnostic data for subjects. On the other hand, the accuracy of the deep model under the unified benchmark GRF dataset and the generalization ability on scalable gait datasets need to be further improved. To address these issues, we propose MA2, a GRF-based self-supervised and motion augmenting auto-encoder, which models the ADD task as an encoder-decoder paradigm. In the encoder, we introduce an embedding block including the 3-layer 1D convolution for extracting the token and a mask generator to randomly mask out the sequence of tokens to maximize the model's potential to capture high-level, discriminative, intrinsic representations. whereafter, the decoder utilizes this information to reconstruct the pixel sequence of the origin input and calculate the reconstruction loss to optimize the network. Moreover, the backbone of an auto-encoder is multi-head self-attention that can consider the global information of the token from the input, not just the local neighborhood. This allows the model to capture generalized contextual information. Extensive experiments demonstrate MA2 has SOTA performance of 90.91% accuracy on 1% limited pathological GRF samples with labels, and good generalization ability of 78.57% accuracy on scalable Parkinson disease dataset.
Flexible Music-Conditioned Dance Generation with Style Description Prompts
Jun 12, 2024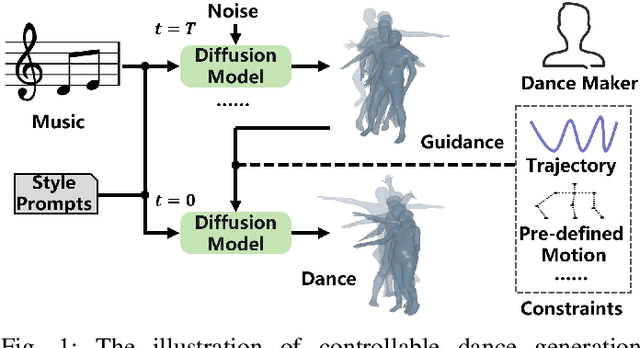
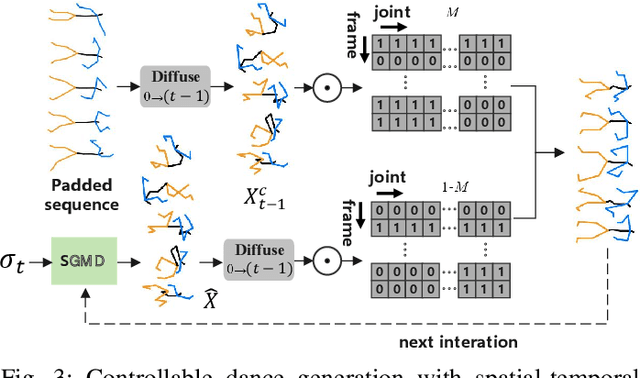
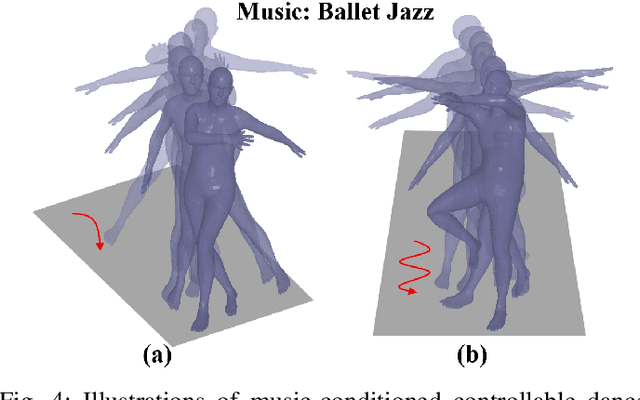
Dance plays an important role as an artistic form and expression in human culture, yet the creation of dance remains a challenging task. Most dance generation methods primarily rely solely on music, seldom taking into consideration intrinsic attributes such as music style or genre. In this work, we introduce Flexible Dance Generation with Style Description Prompts (DGSDP), a diffusion-based framework suitable for diversified tasks of dance generation by fully leveraging the semantics of music style. The core component of this framework is Music-Conditioned Style-Aware Diffusion (MCSAD), which comprises a Transformer-based network and a music Style Modulation module. The MCSAD seemly integrates music conditions and style description prompts into the dance generation framework, ensuring that generated dances are consistent with the music content and style. To facilitate flexible dance generation and accommodate different tasks, a spatial-temporal masking strategy is effectively applied in the backward diffusion process. The proposed framework successfully generates realistic dance sequences that are accurately aligned with music for a variety of tasks such as long-term generation, dance in-betweening, dance inpainting, and etc. We hope that this work has the potential to inspire dance generation and creation, with promising applications in entertainment, art, and education.
FormulaQA: A Question Answering Dataset for Formula-Based Numerical Reasoning
Feb 21, 2024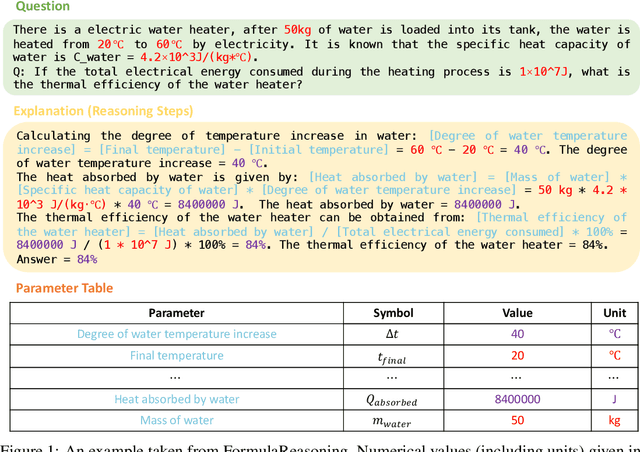



The application of formulas is a fundamental ability of humans when addressing numerical reasoning problems. However, existing numerical reasoning datasets seldom explicitly indicate the formulas employed during the reasoning steps. To bridge this gap, we propose a question answering dataset for formula-based numerical reasoning called FormulaQA, from junior high school physics examinations. We further conduct evaluations on LLMs with size ranging from 7B to over 100B parameters utilizing zero-shot and few-shot chain-of-thoughts methods and we explored the approach of using retrieval-augmented LLMs when providing an external formula database. We also fine-tune on smaller models with size not exceeding 2B. Our empirical findings underscore the significant potential for improvement in existing models when applied to our complex, formula-driven FormulaQA.
Furthest Reasoning with Plan Assessment: Stable Reasoning Path with Retrieval-Augmented Large Language Models
Sep 22, 2023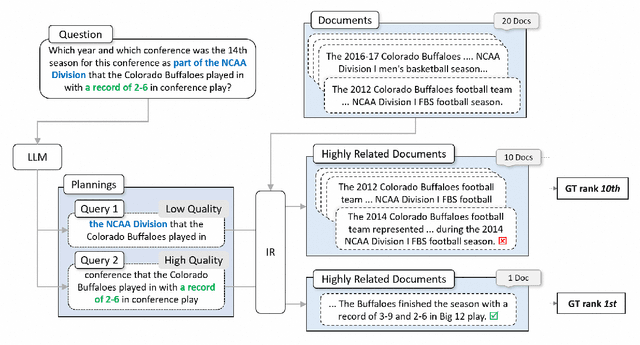
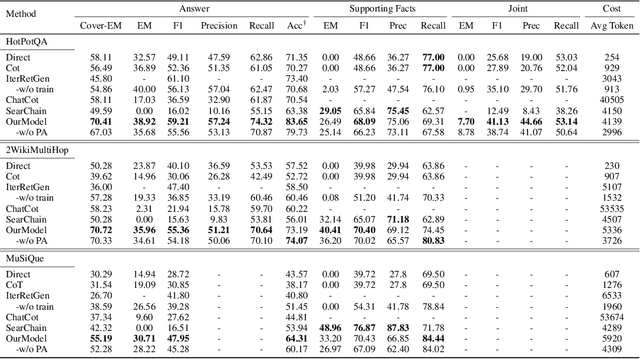
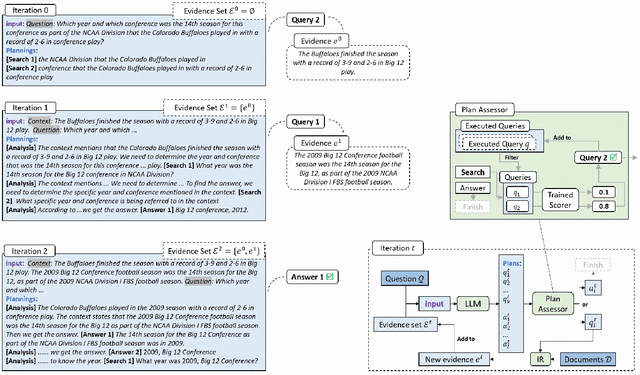
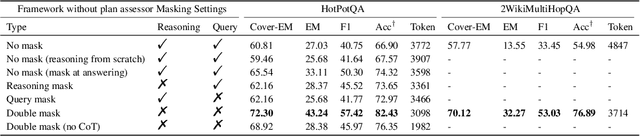
Large Language Models (LLMs), acting as a powerful reasoner and generator, exhibit extraordinary performance across various natural language tasks, such as question answering (QA). Among these tasks, Multi-Hop Question Answering (MHQA) stands as a widely discussed category, necessitating seamless integration between LLMs and the retrieval of external knowledge. Existing methods employ LLM to generate reasoning paths and plans, and utilize IR to iteratively retrieve related knowledge, but these approaches have inherent flaws. On one hand, Information Retriever (IR) is hindered by the low quality of generated queries by LLM. On the other hand, LLM is easily misguided by the irrelevant knowledge by IR. These inaccuracies, accumulated by the iterative interaction between IR and LLM, lead to a disaster in effectiveness at the end. To overcome above barriers, in this paper, we propose a novel pipeline for MHQA called Furthest-Reasoning-with-Plan-Assessment (FuRePA), including an improved framework (Furthest Reasoning) and an attached module (Plan Assessor). 1) Furthest reasoning operates by masking previous reasoning path and generated queries for LLM, encouraging LLM generating chain of thought from scratch in each iteration. This approach enables LLM to break the shackle built by previous misleading thoughts and queries (if any). 2) The Plan Assessor is a trained evaluator that selects an appropriate plan from a group of candidate plans proposed by LLM. Our methods are evaluated on three highly recognized public multi-hop question answering datasets and outperform state-of-the-art on most metrics (achieving a 10%-12% in answer accuracy).
DyRRen: A Dynamic Retriever-Reranker-Generator Model for Numerical Reasoning over Tabular and Textual Data
Nov 23, 2022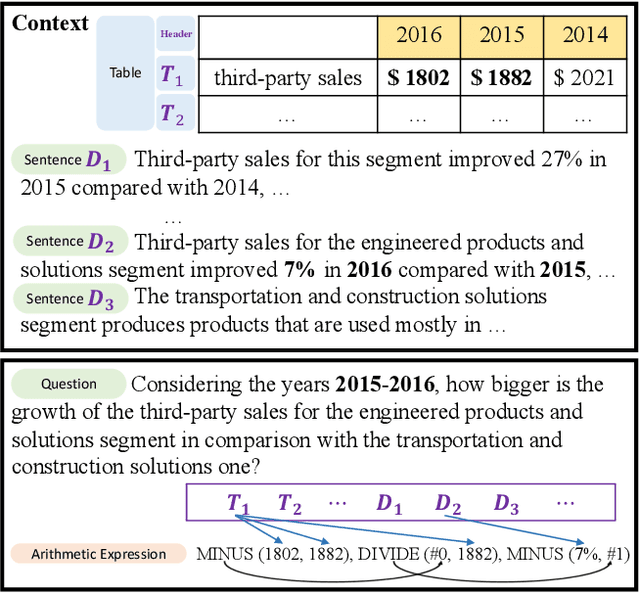
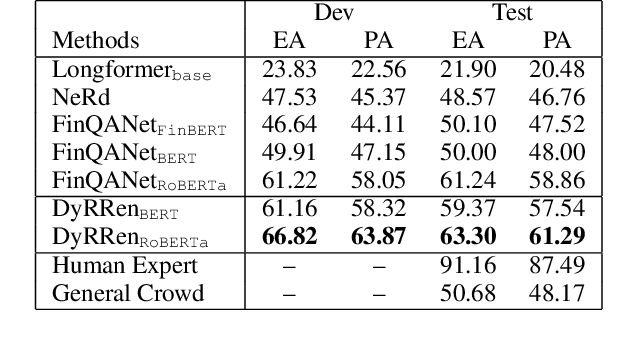
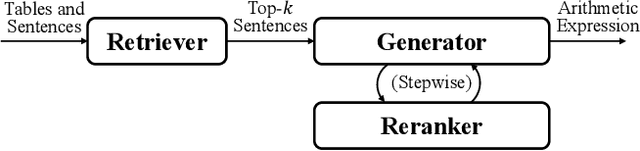
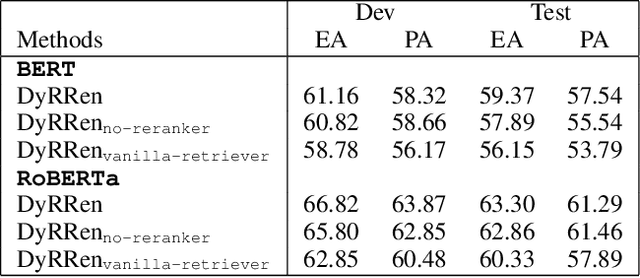
Numerical reasoning over hybrid data containing tables and long texts has recently received research attention from the AI community. To generate an executable reasoning program consisting of math and table operations to answer a question, state-of-the-art methods use a retriever-generator pipeline. However, their retrieval results are static, while different generation steps may rely on different sentences. To attend to the retrieved information that is relevant to each generation step, in this paper, we propose DyRRen, an extended retriever-reranker-generator framework where each generation step is enhanced by a dynamic reranking of retrieved sentences. It outperforms existing baselines on the FinQA dataset.
From Node Interaction to Hop Interaction: New Effective and Scalable Graph Learning Paradigm
Nov 21, 2022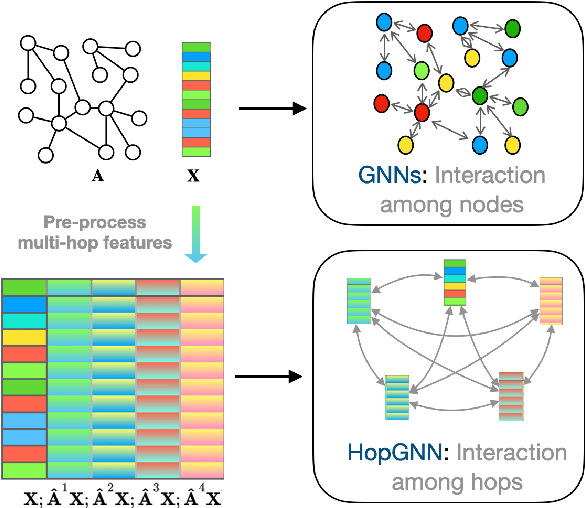
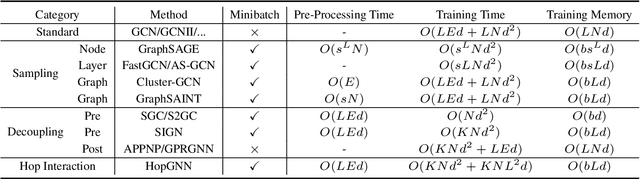
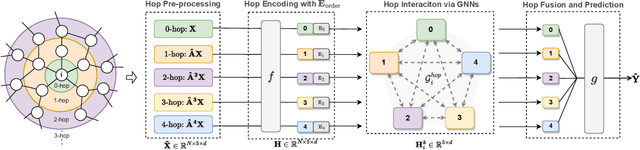
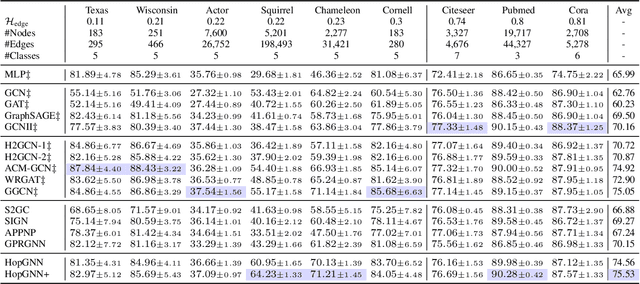
Existing Graph Neural Networks (GNNs) follow the message-passing mechanism that conducts information interaction among nodes iteratively. While considerable progress has been made, such node interaction paradigms still have the following limitation. First, the scalability limitation precludes the wide application of GNNs in large-scale industrial settings since the node interaction among rapidly expanding neighbors incurs high computation and memory costs. Second, the over-smoothing problem restricts the discrimination ability of nodes, i.e., node representations of different classes will converge to indistinguishable after repeated node interactions. In this work, we propose a novel hop interaction paradigm to address these limitations simultaneously. The core idea of hop interaction is to convert the target of message-passing from nodes into multi-hop features inside each node. Specifically, it first pre-computed multi-hop features of nodes to reduce computation costs during training and inference. Then, it conducts a non-linear interaction among multi-hop features to enhance the discrimination of nodes. We design a simple yet effective HopGNN framework that can easily utilize existing GNNs to achieve hop interaction. Furthermore, we propose a multi-task learning strategy with a self-supervised learning objective to enhance HopGNN. We conduct extensive experiments on 12 benchmark datasets in a wide range of domains, scales, and smoothness of graphs. Experimental results show that our methods achieve superior performance while maintaining high scalability and efficiency.
Binaural Rendering of Ambisonic Signals by Neural Networks
Nov 04, 2022



Binaural rendering of ambisonic signals is of broad interest to virtual reality and immersive media. Conventional methods often require manually measured Head-Related Transfer Functions (HRTFs). To address this issue, we collect a paired ambisonic-binaural dataset and propose a deep learning framework in an end-to-end manner. Experimental results show that neural networks outperform the conventional method in objective metrics and achieve comparable subjective metrics. To validate the proposed framework, we experimentally explore different settings of the input features, model structures, output features, and loss functions. Our proposed system achieves an SDR of 7.32 and MOSs of 3.83, 3.58, 3.87, 3.58 in quality, timbre, localization, and immersion dimensions.