 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePHASOR: Anatomy- and Phase-Consistent Volumetric Diffusion for CT Virtual Contrast Enhancement
Apr 01, 2026Contrast-enhanced computed tomography (CECT) is pivotal for highlighting tissue perfusion and vascularity, yet its clinical ubiquity is impeded by the invasive nature of contrast agents and radiation risks. While virtual contrast enhancement (VCE) offers an alternative to synthesizing CECT from non-contrast CT (NCCT), existing methods struggle with anatomical heterogeneity and spatial misalignment, leading to inconsistent enhancement patterns and incorrect details. This paper introduces PHASOR, a volumetric diffusion framework for high-fidelity CT VCE. By treating CT volumes as coherent sequences, we leverage a video diffusion model to enhance structural coherence and volumetric accuracy. To ensure anatomy-phase consistent synthesis, we introduce two complementary modules. First, anatomy-routed mixture-of-experts (AR-MoE) anchors distinct enhancement patterns to anatomical semantics, with organ-specific memory to capture salient details. Second, intensity-phase aware representation alignment (IP-REPA) highlights intricate contrast signals while mitigating the impact of imperfect spatial alignment. Extensive experiments across three datasets demonstrate that PHASOR significantly outperforms state-of-the-art methods in both synthesis quality and enhancement accuracy.
Translation via Annotation: A Computational Study of Translating Classical Chinese into Japanese
Nov 07, 2025Ancient people translated classical Chinese into Japanese by annotating around each character. We abstract this process as sequence tagging tasks and fit them into modern language technologies. The research of this annotation and translation system is a facing low-resource problem. We release this problem by introducing a LLM-based annotation pipeline and construct a new dataset from digitalized open-source translation data. We show that under the low-resource setting, introducing auxiliary Chinese NLP tasks has a promoting effect on the training of sequence tagging tasks. We also evaluate the performance of large language models. They achieve high scores in direct machine translation, but they are confused when being asked to annotate characters. Our method could work as a supplement of LLMs.
FoundDiff: Foundational Diffusion Model for Generalizable Low-Dose CT Denoising
Aug 24, 2025Low-dose computed tomography (CT) denoising is crucial for reduced radiation exposure while ensuring diagnostically acceptable image quality. Despite significant advancements driven by deep learning (DL) in recent years, existing DL-based methods, typically trained on a specific dose level and anatomical region, struggle to handle diverse noise characteristics and anatomical heterogeneity during varied scanning conditions, limiting their generalizability and robustness in clinical scenarios. In this paper, we propose FoundDiff, a foundational diffusion model for unified and generalizable LDCT denoising across various dose levels and anatomical regions. FoundDiff employs a two-stage strategy: (i) dose-anatomy perception and (ii) adaptive denoising. First, we develop a dose- and anatomy-aware contrastive language image pre-training model (DA-CLIP) to achieve robust dose and anatomy perception by leveraging specialized contrastive learning strategies to learn continuous representations that quantify ordinal dose variations and identify salient anatomical regions. Second, we design a dose- and anatomy-aware diffusion model (DA-Diff) to perform adaptive and generalizable denoising by synergistically integrating the learned dose and anatomy embeddings from DACLIP into diffusion process via a novel dose and anatomy conditional block (DACB) based on Mamba. Extensive experiments on two public LDCT datasets encompassing eight dose levels and three anatomical regions demonstrate superior denoising performance of FoundDiff over existing state-of-the-art methods and the remarkable generalization to unseen dose levels. The codes and models are available at https://github.com/hao1635/FoundDiff.
MedITok: A Unified Tokenizer for Medical Image Synthesis and Interpretation
May 25, 2025Advanced autoregressive models have reshaped multimodal AI. However, their transformative potential in medical imaging remains largely untapped due to the absence of a unified visual tokenizer -- one capable of capturing fine-grained visual structures for faithful image reconstruction and realistic image synthesis, as well as rich semantics for accurate diagnosis and image interpretation. To this end, we present MedITok, the first unified tokenizer tailored for medical images, encoding both low-level structural details and high-level clinical semantics within a unified latent space. To balance these competing objectives, we introduce a novel two-stage training framework: a visual representation alignment stage that cold-starts the tokenizer reconstruction learning with a visual semantic constraint, followed by a textual semantic representation alignment stage that infuses detailed clinical semantics into the latent space. Trained on the meticulously collected large-scale dataset with over 30 million medical images and 2 million image-caption pairs, MedITok achieves state-of-the-art performance on more than 30 datasets across 9 imaging modalities and 4 different tasks. By providing a unified token space for autoregressive modeling, MedITok supports a wide range of tasks in clinical diagnostics and generative healthcare applications. Model and code will be made publicly available at: https://github.com/Masaaki-75/meditok.
Radiologist-in-the-Loop Self-Training for Generalizable CT Metal Artifact Reduction
Jan 26, 2025



Metal artifacts in computed tomography (CT) images can significantly degrade image quality and impede accurate diagnosis. Supervised metal artifact reduction (MAR) methods, trained using simulated datasets, often struggle to perform well on real clinical CT images due to a substantial domain gap. Although state-of-the-art semi-supervised methods use pseudo ground-truths generated by a prior network to mitigate this issue, their reliance on a fixed prior limits both the quality and quantity of these pseudo ground-truths, introducing confirmation bias and reducing clinical applicability. To address these limitations, we propose a novel Radiologist-In-the-loop SElf-training framework for MAR, termed RISE-MAR, which can integrate radiologists' feedback into the semi-supervised learning process, progressively improving the quality and quantity of pseudo ground-truths for enhanced generalization on real clinical CT images. For quality assurance, we introduce a clinical quality assessor model that emulates radiologist evaluations, effectively selecting high-quality pseudo ground-truths for semi-supervised training. For quantity assurance, our self-training framework iteratively generates additional high-quality pseudo ground-truths, expanding the clinical dataset and further improving model generalization. Extensive experimental results on multiple clinical datasets demonstrate the superior generalization performance of our RISE-MAR over state-of-the-art methods, advancing the development of MAR models for practical application. Code is available at https://github.com/Masaaki-75/rise-mar.
Team Ryu's Submission to SIGMORPHON 2024 Shared Task on Subword Tokenization
Oct 19, 2024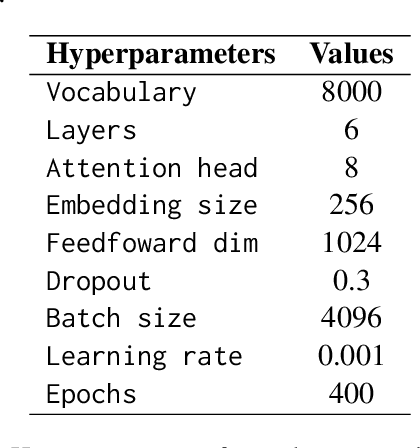
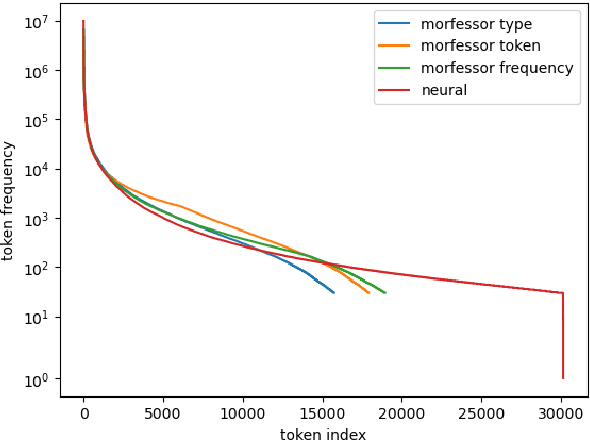


This papers presents the submission of team Ryu to the canceled SIGMORPHON 2024 shared task on subword tokenization. My submission explores whether morphological segmentation methods can be used as a part of subword tokenizers. I adopt two approaches: the statistical segmentation method Morfessor and a transformer based sequence-to-sequence (seq2seq) segmentation model in tokenizers. The prediction results show that morphological segmentation could be as effective as commonly used subword tokenizers. Additionally, I investigate how a tokenizer's vocabulary influences the performance of language models. A tokenizer with a balanced token frequency distribution tends to work better. A balanced token vocabulary can be achieved by keeping frequent words as unique tokens.
Universal Incomplete-View CT Reconstruction with Prompted Contextual Transformer
Dec 13, 2023Despite the reduced radiation dose, suitability for objects with physical constraints, and accelerated scanning procedure, incomplete-view computed tomography (CT) images suffer from severe artifacts, hampering their value for clinical diagnosis. The incomplete-view CT can be divided into two scenarios depending on the sampling of projection, sparse-view CT and limited-angle CT, each encompassing various settings for different clinical requirements. Existing methods tackle with these settings separately and individually due to their significantly different artifact patterns; this, however, gives rise to high computational and storage costs, hindering its flexible adaptation to new settings. To address this challenge, we present the first-of-its-kind all-in-one incomplete-view CT reconstruction model with PROmpted Contextual Transformer, termed ProCT. More specifically, we first devise the projection view-aware prompting to provide setting-discriminative information, enabling a single model to handle diverse incomplete-view CT settings. Then, we propose artifact-aware contextual learning to provide the contextual guidance of image pairs from either CT phantom or publicly available datasets, making ProCT capable of accurately removing the complex artifacts from the incomplete-view CT images. Extensive experiments demonstrate that ProCT can achieve superior performance on a wide range of incomplete-view CT settings using a single model. Remarkably, our model with only image-domain information surpasses the state-of-the-art dual-domain methods that require the access to raw data. The code is available at: https://github.com/Masaaki-75/proct
Prompt-In-Prompt Learning for Universal Image Restoration
Dec 08, 2023



Image restoration, which aims to retrieve and enhance degraded images, is fundamental across a wide range of applications. While conventional deep learning approaches have notably improved the image quality across various tasks, they still suffer from (i) the high storage cost needed for various task-specific models and (ii) the lack of interactivity and flexibility, hindering their wider application. Drawing inspiration from the pronounced success of prompts in both linguistic and visual domains, we propose novel Prompt-In-Prompt learning for universal image restoration, named PIP. First, we present two novel prompts, a degradation-aware prompt to encode high-level degradation knowledge and a basic restoration prompt to provide essential low-level information. Second, we devise a novel prompt-to-prompt interaction module to fuse these two prompts into a universal restoration prompt. Third, we introduce a selective prompt-to-feature interaction module to modulate the degradation-related feature. By doing so, the resultant PIP works as a plug-and-play module to enhance existing restoration models for universal image restoration. Extensive experimental results demonstrate the superior performance of PIP on multiple restoration tasks, including image denoising, deraining, dehazing, deblurring, and low-light enhancement. Remarkably, PIP is interpretable, flexible, efficient, and easy-to-use, showing promising potential for real-world applications. The code is available at https://github.com/longzilicart/pip_universal.
LICO: Explainable Models with Language-Image Consistency
Oct 15, 2023Interpreting the decisions of deep learning models has been actively studied since the explosion of deep neural networks. One of the most convincing interpretation approaches is salience-based visual interpretation, such as Grad-CAM, where the generation of attention maps depends merely on categorical labels. Although existing interpretation methods can provide explainable decision clues, they often yield partial correspondence between image and saliency maps due to the limited discriminative information from one-hot labels. This paper develops a Language-Image COnsistency model for explainable image classification, termed LICO, by correlating learnable linguistic prompts with corresponding visual features in a coarse-to-fine manner. Specifically, we first establish a coarse global manifold structure alignment by minimizing the distance between the distributions of image and language features. We then achieve fine-grained saliency maps by applying optimal transport (OT) theory to assign local feature maps with class-specific prompts. Extensive experimental results on eight benchmark datasets demonstrate that the proposed LICO achieves a significant improvement in generating more explainable attention maps in conjunction with existing interpretation methods such as Grad-CAM. Remarkably, LICO improves the classification performance of existing models without introducing any computational overhead during inference. Source code is made available at https://github.com/ymLeiFDU/LICO.
Learning to Distill Global Representation for Sparse-View CT
Aug 19, 2023



Sparse-view computed tomography (CT) -- using a small number of projections for tomographic reconstruction -- enables much lower radiation dose to patients and accelerated data acquisition. The reconstructed images, however, suffer from strong artifacts, greatly limiting their diagnostic value. Current trends for sparse-view CT turn to the raw data for better information recovery. The resultant dual-domain methods, nonetheless, suffer from secondary artifacts, especially in ultra-sparse view scenarios, and their generalization to other scanners/protocols is greatly limited. A crucial question arises: have the image post-processing methods reached the limit? Our answer is not yet. In this paper, we stick to image post-processing methods due to great flexibility and propose global representation (GloRe) distillation framework for sparse-view CT, termed GloReDi. First, we propose to learn GloRe with Fourier convolution, so each element in GloRe has an image-wide receptive field. Second, unlike methods that only use the full-view images for supervision, we propose to distill GloRe from intermediate-view reconstructed images that are readily available but not explored in previous literature. The success of GloRe distillation is attributed to two key components: representation directional distillation to align the GloRe directions, and band-pass-specific contrastive distillation to gain clinically important details. Extensive experiments demonstrate the superiority of the proposed GloReDi over the state-of-the-art methods, including dual-domain ones. The source code is available at https://github.com/longzilicart/GloReDi.